The first time Meta released the Llama 3 language model, Intel optimized and verified that the Llama 3 model with 8 billion and 70 billion parameters could run on Intel AI product portfolio. In the client field, Intel Ruixuan Graphics card The powerful performance of allows developers to easily run the Llama 3 model locally, providing acceleration for generated AI workloads.
In the preliminary test of the Llama3 model, Intel Core Ultra H series processors showed output generation performance higher than the reading speed of ordinary people. This result is mainly due to its built-in Intel Ruixuan GPU, which has 8 Xe cores and DP4a AI accelerator And system memory bandwidth up to 120GB/s.
The Intel Core Ultra processor and Intel Ruixuan graphics card provided good adaptation at the first time of the release of the Llama 3 model, which demonstrated the efforts made by Intel and Meta to jointly develop local AI and deploy millions of devices. The substantial improvement of Intel client hardware performance benefits from the rich Software Framework and tools, and OpenVINO toolkit for model deployment and reasoning.
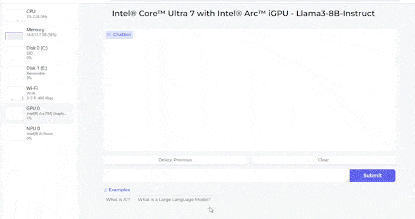
Run Meta-Lama3-8B-Instruct on Intel Core Ultra7 with Intel Flash graphics card
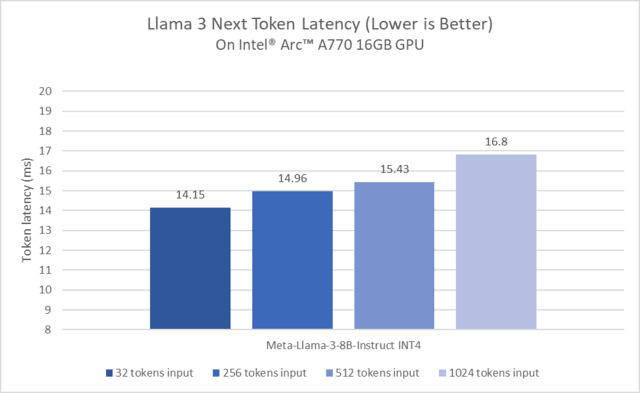
Next Token Delay for Running Llama3 on Intel Sharp A770
The figure above shows the excellent performance of the Intel Ruixuan A770 graphics card when running the Llama3 model after matching with the PyTorch framework and optimizing for the Intel GPU. In addition, Intel Ruixuan graphics card also supports developers to run large language models including Mistral-7B-InstructLLM, Phi2, Llama2, etc. locally.
The main reason why developers can run multiple models locally based on the same basic installation can be attributed to IPEX-LLM, a large language model library for PyTorch. It is mainly based on Intel PyTorch expansion package, covering the latest big language model optimization and low bit data compress (INT4/FP4/INT8/FP8), and most of the latest performance optimizations for Intel hardware. Thanks to the Xe core XMX AI acceleration function on Intel independent graphics cards such as Ruixuan A series graphics cards, IPEX-LLM can significantly improve performance. It supports Intel Ruixuan A series graphics cards on Windows subsystem Linux version, native Windows environment and native Linux.
Since all operations and models are based on the native PyTorch framework, developers can easily replace or use different PyTorch models and input data. The above models and data can not only run on Intel Ruixuan graphics card, but also developers can enjoy the performance improvement brought by Intel Ruixuan graphics card acceleration.
This article is an original article. If it is reproduced, please indicate the source: First time fit! Intel Ruixuan GPU shows excellent performance when running Llama 3 https://server.zol.com.cn/867/8676225.html
https://server.zol.com.cn/867/8676225.html
server.zol.com.cn
true
Zhongguancun Online
https://server.zol.com.cn/867/8676225.html
report
one thousand eight hundred and sixteen
The first time Meta released the Llama 3 language model, Intel optimized and verified that the Llama 3 model with 8 billion and 70 billion parameters could run on Intel AI product portfolio. In the client field, the powerful performance of Intel Ruixuan graphics card enables developers to easily run the Llama 3 model locally, providing acceleration for the generated AI workload. In the preliminary test of Llama3 model