IMPC数据来源于多种分析。每个分析都有不同的特征,因此不能用单一的统计方法进行分析。自数据发布12起,IMPC使用一个名为OpenStats(开放状态),可用作R包,为每种数据类型应用适当的统计方法。以前的版本依赖于PhenStat公司用于统计分析,也可作为R包提供在这里.
OpenStats包提供了识别异常表型的统计方法,重点是高通量数据流。该包包含:
- 数据集预处理和检查最低要求;和
- 3项统计测试,以确定对表型的显著基因型影响:
- 分类数据的Fisher精确检验
- 连续数据的线性混合模型
- 低N连续数据的参考范围+(RR+)模型
所有分析框架都输出统计显著性度量、效应大小度量、模型诊断(适当时),以及 数据可视化(尤其是图表页面).
可以找到有关OpenStats包的更多文档在这里,同时可以访问预打印纸在这里.
分类数据
分类数据分析使用费希尔精确测试该方法包括构建一个列联表,以按表型和生物组(例如突变与基线)对动物进行分类。目前,特定性状的表型被归为一组,并与正常表型的频率进行比较。此类分析的示例包括异常的涂层颜色和眼睛形态异常.
连续数据
线性混合模型
使用线性混合模型该方法使用线性方程将测量值建模为基因型和其他变量的函数,包括性别、体重和批次(测量日期)。批次被视为随机效应,除非是随时间进行的测量(例如体重),在这种情况下,它包含在协变量中。基因型和性别等变量之间的相互作用也可以建模。
这种方法允许统计程序确定可归因于基因型而非其他协变量的显著变化。此类分析的示例包括旷野活动不足和临床化学中的循环胰岛素水平.
相关阅读:
时间变化对小鼠敲除表型研究设计和分析的影响
解决混杂因素的比率校正谬误
参考范围+
在线性混合模型失败的情况下,OpenStats使用参考范围+模型。这项技术包括将测量值与预定义范围进行比较,这些范围被视为捕获野生型中可接受的变异性。这些比较导致离散值(范围内与范围外),然后使用Fisher精确检验进行统计评估。
生存力和生育率数据
可育性和生育率数据采用自定义方法分别处理。我们将其称为线级参数。这些数据由表型中心收集和处理,表型中心使用适合其育种方案的统计方法。IMPReSS公司有关于如何成人和胚胎生存能力以及生育能力对数据进行了分析。
平行坐标查看器
链接:https://www.mousephinotype.org/help/data-visualization/faqs/how-do-i-use-the-parallel-coordinates-viewer/
控制选择策略
在高通量管道中生成数据的一个副作用是,统计计算的输入数据可能会在多天内生成。在比较不同日期收集的数据时,环境波动已被确定为一个混淆因素。IMPC将其描述为“批量效应”,并在混合模型框架中将其视为随机效应。
相关阅读:
请参阅IMPC文件改进高通量表型数据分析的软窗口应用,生物信息学361492–1500(2020年)
使用这些字段的独特组合识别待分析的数据集:
| 字段 | 描述 |
| 背景菌株 | 变异样本来源的原始菌株。 |
| 小巷/殖民地 | 突变体中的基因组变异。等位基因描述了突变的特征和严重程度,基因型效应术语. |
| 合度 | WT(野生型或+/+)
野生型等位基因。
杂合(het)
突变发生在一个等位基因拷贝中。
纯合子(hom)
突变发生在等位基因的两个拷贝中。
半合子(半合子)
突变发生在性连锁等位基因中,正常情况下,WT中只有一个拷贝。 |
| 管道 | 标准化表型管道如IMPReSS管道. |
| 程序 | 中所述的标准化程序集(实验)IMPReSS程序. |
| 参数 | 中所述的标准化测量集IMPReSS参数. |
| 元数据组 | 一些参数显示为“procedureMetadata”类型。其中一些元数据用于将可比较数据分组,如IMPReSS参数页面下的“数据分析所需”部分。标记为“数据分析所需”的参数由称为元数据组的标识符共同标识。 |
| 组织 | 执行实验并收集数据的表型组织。 |
性别[1]
| 标本的性别。当使用线性混合模型进行分析时,男性和女性一起进行分析,以确定性别和性别*基因型相互作用的影响项。[1]–可选 |
|
表型统计
如果突变基因型效应在IMPC水平为0.0001的连续和分类测量中代表了与对照组相比的显著变化,那么IMPC管道将尝试将哺乳动物表型(MP)术语数据(哺乳动物表型本体)。
为参数定义的特定MP项保留在IMPReSS公司。该术语通常表示增加或减少与对照组相比,测量参数的变化。如果这不合适,则反常的可能会指示呼叫。
当统计结果被确定为显著时,下图用于关联MP术语:
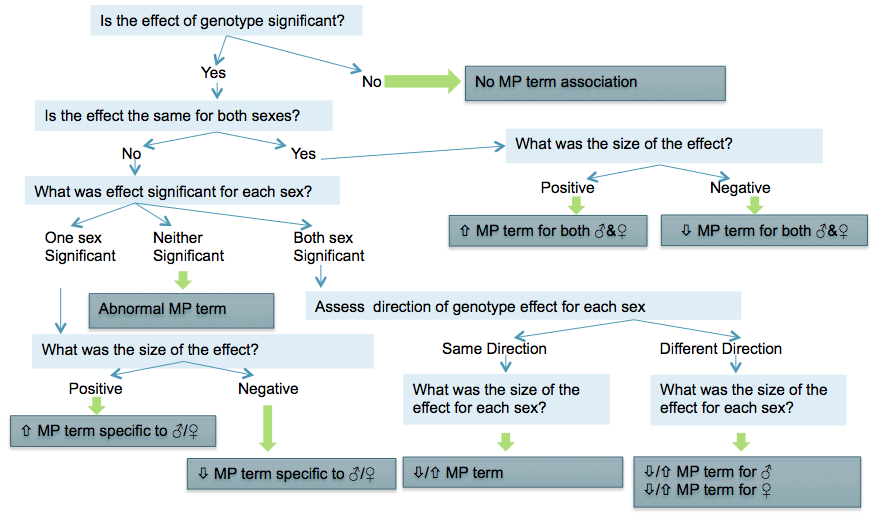
重要性
当突变型基因型效应P值小于1.0E-4(即0.0001)时,它被认为是显著的。
请参阅章节IMPC使用什么P值?
