因此,现在生成性人工智能的时代已经到来,它的大型语言模型(LLM)如ChatGPT,基于LLM GPT-3.5,具有67亿个参数。计算机科学家曾期望缩放语言模型将提高他们在已经熟悉的任务上的性能,但并不是说这些模型突然能够处理如此多的新的和不可预测的任务。事实上,新的ChatGPT使用场景每天都会出现在博客和推文中。当新的复杂属性或行为从系统内的交互中出现时,就会出现这种现象,称为涌现。涌现是当今计算机科学的一个中心研究问题;这已经讨论很久了斯坦福大学(Stanford University)的计算机科学家里希·博马萨尼(Rishi Bommasani)表示:“据我所知,文献中从未描述过语言模型可以完成这类任务。”。去年,他帮助编制了一份数十种紧急行为的清单。由Ethan Dyer(Google Research)发起的Beyond The Immation Game Benchmark(BIG-bench)项目也记录了LLM的紧急行为,共有444位作者来自132个机构的204项任务。主题多种多样,包括语言学、儿童发展、数学、生物、物理或软件开发等方面的问题。
在L3S和TIB联合实验室,Jennifer D’Souza博士和她的团队正在开放研究知识图(ORKG)项目中开发和使用LLM。ORKG使用语义技术共享研究新形式的知识,而不是PDF文档。核心要素是研究比较。它们的工作原理与亚马逊产品比较类似,只是ORKG的研究比较是基于结构化、基于属性的研究文章的描述。项目负责人Sören Auer教授说:“通过开放研究知识图,我们正在重塑科学传播。”。
ChatGPT在比较研究文章方面的表现如何?科学家们要求聊天机器人根据三篇文章的标题和摘要创建一个研究比较(根据给定的文本创建一个比较表以下三篇论文)。结果是:“第一次尝试很好,”D’Souza说。
图1:ChatGPT生成一个研究比较
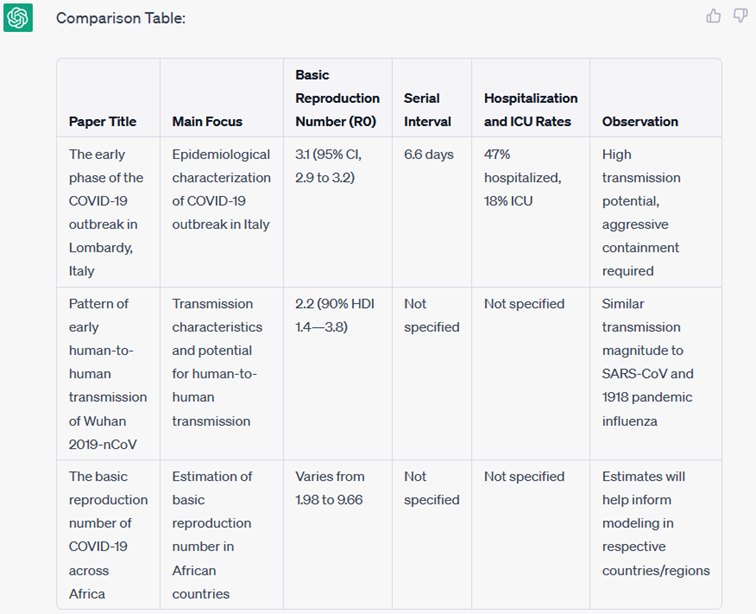
然而,ORKG研究比较应基于一个常见的研究问题,在这种情况下,即Covid-19基线繁殖数(R0)。为了对贡献进行总结,需要对比R0值具有其他属性。然而,上述比较只正确地反映了一个属性:R0的值。研究人员再次要求ChatGPT创建一个研究比较,但这一次使用了所需的属性(根据以下属性,从以下三篇论文的给定文本创建一个比较表:位置、日期、R0值、%CI值和方法)。
图2:ChatGPT生成与给定属性的研究比较。
答对 了!结果(图2)是一个研究比较,正确率约为80%,没有幻觉,这是LLM发明信息的现象。LLM生成表是一个相当令人惊讶的发现,它偏离了与文本生成中的预期行为显著不同。
在ORKG项目中,该团队正在积极研究使用LLM作为辅助工具进行研究比较。这篇文章展示了一个积极的例子,但也有一些案例表明,面对上下文过长或不足,甚至是幻觉信息。“在接下来的几个月里,我们计划衡量LLM生成研究比较的能力,并希望为紧急任务列表做出贡献在大板凳上,”D'Souza说。