在过去十年里,越来越多的市、县和州已经认识到现金保释制度的严重不公正性,在这种制度中,能够支付保释金的人可以自由行走,而不能支付保释费的人则被拘留。但这种意识引发了一个棘手的问题:什么应该取代它?法官应如何决定拘留审前人员?在许多情况下,答案是更加依赖风险评估,即基于预测分析的算法工具。
法官不仅在预审决定中使用风险评估,而且还使用或考虑使用在判刑和假释决定中。几乎每个美国州和联邦系统都以某种形式实施了风险评估。几个州正处于推出新工具的不同阶段,最近颁布的《第一步法案》(First Step Act)要求制定新的联邦风险评估,旨在减少累犯,并将被监禁者与服务联系起来。刑法的任何一个角落如果没有被预测模型所改变的话,很可能不会持续太久。
很容易看出风险评估的吸引力。法官和其他司法系统行动者每天作出的决定不仅对公共安全,而且对被告和犯罪受害者以及他们的家人和社区的生命都可能产生重大影响。然而,如果法官对被告或被告类型抱有偏见,不受约束的司法自由裁量权可能是危险的。
如果风险评估能够使这些决策变得更容易,并以严格、基于证据的方式进行,从而导致更公平和更公正的结果,那么它们将是一种纯粹的好东西。算法的支持者表示,强制实施一些数学规则将提高透明度和问责制,并最终改善当前系统。
但风险评估算法的实际情况更为复杂。批评人士表示,从开发到实现再到应用,偏见会在每个阶段蔓延开来。这通常是种族偏见,但其他特征如年龄和种族也可能导致不公平。
这些据称是客观的算法是由人类使用不完美的数据开发出来的,并且陷入了令人担忧的政治问题中。它们还经常用于超出其声明意图的情况。例如,用于衡量某人是否会重返法庭的风险评估有时被错误地用于衡量此人再次犯罪的风险。
尽管人们使用“算法”这个词的方式极具魔力,但这种决策的几乎每个方面最终都取决于人类的创造力(或缺乏创造力)。
由于算法风险评估的时代正在到来,问题不在于是否使用这些工具,而在于如何以最大化公平性和最小化危害的方式使用这些工具。即使是一些对偏见持谨慎态度的观察家也认为,使用风险评估来告知治疗决策并提供监禁以外的资源是有希望的。
这个解释者将有助于理解这些工具的一些基本技术方面,以及关于主导该领域的争议的状态。
风险评估工具的“算法化”意味着什么?
至少从20世纪30年代起,风险评估就一直是美国刑事法律体系的一部分,但几十年来,它一直是临床这意味着他们主要依赖专家的判断。这些专家可能是心理学家、社会工作者、缓刑官员或其他司法系统参与者,但评估取决于执行者的判断。
相反,精算师风险评估基于统计模型,表面上并不依赖于人类的判断。这样的模型可以像线性或逻辑回归模型一样简单,就像你在统计学入门课上学到的那样,也可以涉及现代机器学习技术。
算法因此,风险评估只是一种精算风险评估。该术语通常用于指计算机执行一系列步骤以提供最终风险评分的风险评估。
尽管人们以神奇的方式部署“算法”一词,但这种决策的几乎每个方面最终都取决于人类的独创性(或缺乏独创性)。算法由人类设计,在人类构建的计算机上运行,根据人类收集的数据进行训练,并根据它们反映人类优先事项和价值的程度进行评估。尽管这种方法很有用,但算法正义故事中反复出现的一个主题是,人类的缺陷如何彻底地渗透到表面上的客观机械过程中。
风险评估算法是如何工作的?
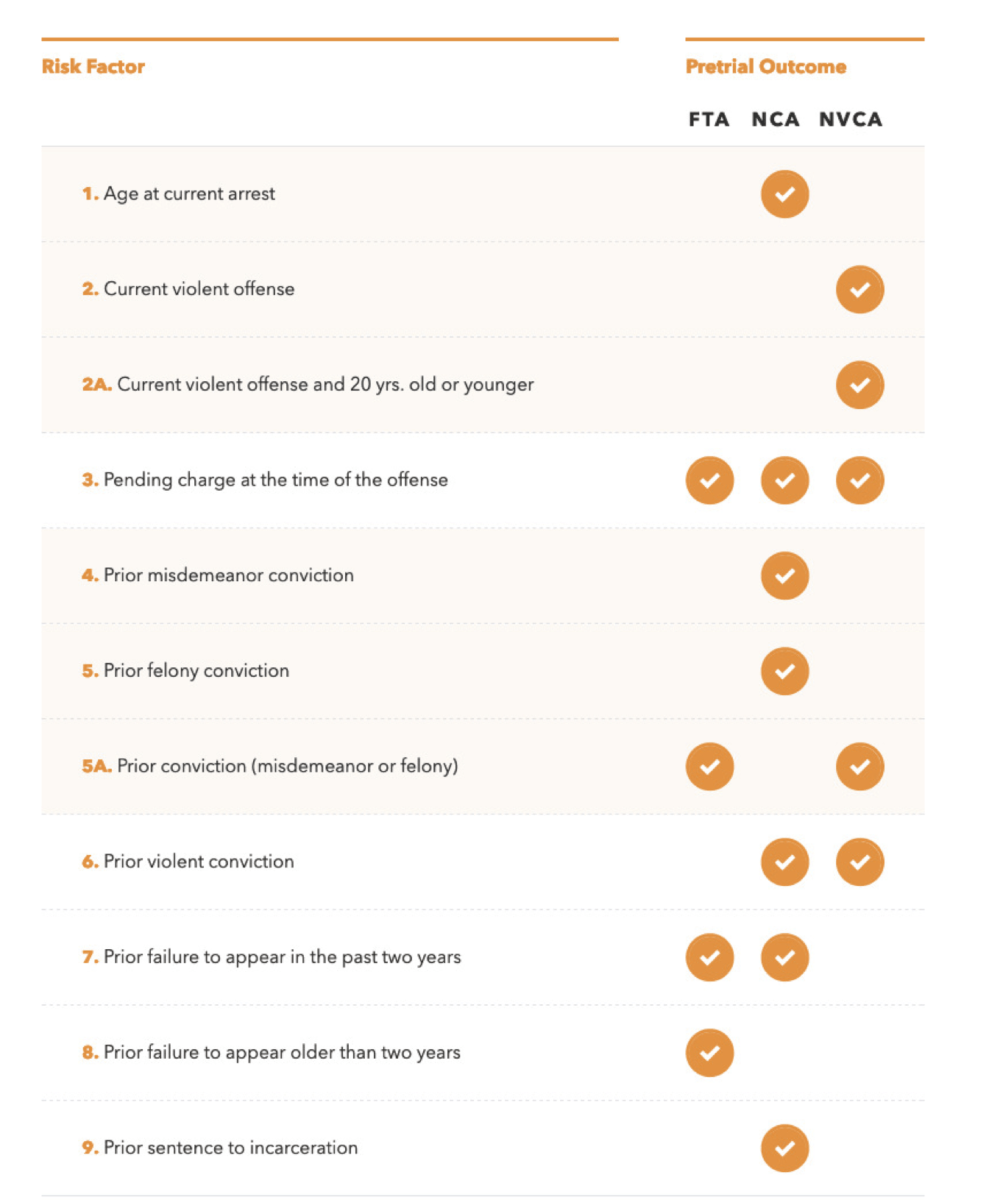
大多数风险评估工具将法庭和人口统计记录与法院官员管理的某种问卷相结合,例如保释情况下的审前服务官员,或假释决定中的监狱社会工作者。一些工具,如阿诺德基金会(现在称为阿诺德风险投资公司)创建的公共安全评估,省略了调查问卷,只使用静态数据。这些工具考虑了犯罪史、工作状态、教育水平和家庭信息等因素,为每个因素赋予了数字权重,从而使该因素在计算最终分数时或多或少变得重要。
模型中权重的概念需要特别强调,因为在许多情况下,这是算法中最不透明的部分。虽然一些风险评估的创建者与公众分享了他们模型的细节,但其他模型是由私营公司开发的,这些公司将算法的内部工作保密。即使对于一些最封闭、最专有的工具,从业者用来管理它们的问卷也可以免费获得,就像现在一样培训手册阿诺德基金会的公共安全评估使用了这些因素,这些因素通常具有该领域的代表性:
 截图,psaprepial.org阿诺德风险投资公司
截图,psaprepial.org阿诺德风险投资公司
设置权重的过程称为训练模型。在机器学习上下文中,这称为监督学习。将一个数据集输入模型,该模型包含一组特征,如年龄、先前被捕次数等,以及一组模型应预测的结果变量的已知值。
例如,如果模型应该预测两年内重新调整的可能性(正如许多风险评估工具中的情况),那么用于训练模型的数据将有一个大数据集,其格式类似于电子表格,将输入变量的值与输出变量的值相关联(即预测)。用于训练一个简单模型的输入,仅使用年龄和先前被捕人数来预测再次被捕,其结果可能如下:
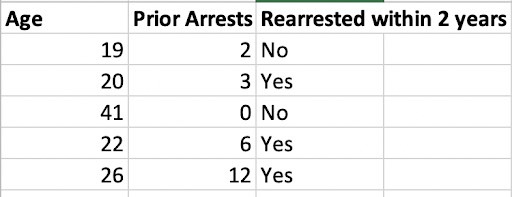
一个真实的数据集要大得多,并且有更多的变量,但在这里,为这个简单模型设置权重的过程只需要计算出年龄与之前被捕人数在预测特定结果可能性(是否在两年内再次被捕)方面的重要性。一旦开发人员建立了这些权重(最好是在大量测试之后),模型就可以应用于新数据。
算法数据,人类优先级
即使是上述具有两个特性和一个输出的基本模型,也引入了算法风险评估中最具争议的两个问题,即输入的选择和数据的质量。输入的选择既反映了工具开发人员想要预测的内容,也反映了他们认为能够使预测准确的数据。同样,进入模型的数据质量反映了收集数据的人的优先级,即他们选择捕获什么。
但是,风险评估要预测的结果与用于训练预测模型的数据之间往往存在不匹配,这种差距主要是由于可用数据的性质造成的。关于逮捕和定罪的数据非常丰富,这使得它成为工具开发人员的一个有吸引力的选择。然而,逮捕数据显示的更多是执法和法院的行为,而不是工具适用的个人。
用于告知量刑决定的风险评估应该预测被判刑的人在监管期结束后的某个时候是否会犯下新的罪行。这一决定应该基于具有相似背景的人过去是否继续犯罪。但与此同时估计数据关于这些活动,这些估计是不完整的。
许多风险评估工具的开发人员,例如COMPAS的制造商,使用二年内再次拘禁作为累犯的定义因此,这些开发人员构建的模型将基于仅包含此统计信息的数据。但理想的情况是,一个旨在告知量刑决定的工具应该能够预测被判刑者犯下新罪行的可能性,而不是再次被捕的可能性。许多犯罪行为都没有人被捕,当然,人们通常是在没有犯罪的情况下被捕的。有人被逮捕的可能性至少与警察工作有关,警察工作往往不成比例地针对低收入有色人种社区,这与被判刑人的行为同样重要。
这在费城尤其成问题。费城辩护律师协会律师布拉德利·布里奇告诉马歇尔计划,“这是一个复杂的问题……一旦他们被捕一次,他们更有可能第二次或第三次被捕,不是因为他们一定比其他人做得更多,而是因为他们之前被捕过一两次。”[安娜·玛丽亚·巴里·杰斯特、本·卡塞尔曼和达娜·戈尔茨坦/马歇尔项目]
统计数据的选择还存在其他问题。风险评估通常使用“出庭失败”率来预测某人重返法庭的可能性,但大多数缺席法庭的人并不是故意回避预约。他们可能无家可归,有孩子的问题,或者只是忘记了。使用这些数据预测某人是否会潜逃会产生误导性的结果。[“未能露面”谬论、伊桑·科里和帕克·洛/上诉]
同样,逮捕本身并不一定意味着某人再次犯罪。
虽然逮捕和定罪是对实际犯罪行为的一种不完善的衡量标准,但正如过去一样,它们被用于平衡的两边。也就是说,几乎任何旨在预测累犯的模型都会将逮捕作为预测因素和预测对象。
作为一个最近的论文AI Now Institute认为,在预测性警务的相关背景下,利用有关警务的数据建立预测模型,有可能清洗这些数据,将其从对过去发生的事情的描述转变为对未来发生的事情进行算法规划。只要将逮捕纳入风险评估,同样的危险也会发生。 [拉希达·理查森(Rashida Richardson)、杰森·舒尔茨(Jason Schultz)和凯特·克劳福德(Kate Crawford)/SSRN]
使用风险评估的每种环境也会引发独特的数据问题。风险评估用于刑事法律程序的许多阶段,从保释到判刑到假释决定,在每个阶段衡量风险意味着不同的事情。例如,一个人出庭的可能性与用于通知假释决定的风险评估工具无关,但在审前风险评估中当然至关重要。
同样,预测两年内再次逮捕可能性的判刑风险评估在预审工具所需的短期内也不会特别有用。尽管如此,风险评估工具通常被用于设计以外的用途。例如,COMPAS最初是作为帮助惩戒部门管理案件的软件开发的,但现在它被广泛用于其他场合,例如判刑。[哈佛法学院Danielle Kehl、Priscilla Guo和Samuel Kessler/Berkman Klein中心]
所有这一切只是说,风险评估工具的开发人员必须考虑他们用来训练模型的数据的来源,以免他们将现有警务策略的缺陷永久化,同时将其视为数学必然性的假象。同样,风险评估工具的消费者需要了解工具开发人员的选择,并了解数据的局限性以及创建数据的更广泛的社会背景。
算法风险评估是否“有偏见”?
2016年,ProPublica发布了一份文章副标题是“全国各地都有预测未来罪犯的软件。而且它对黑人有偏见。”研究的作者彻底分析COMPAS在佛罗里达州布劳沃德县法院判决中的应用分析显示,假阳性率和假阴性率存在种族差异,这意味着算法判定为“高危”但两年内未再次被捕的人更有可能是黑人。同样,那些被COMPAS称为“低风险”但在两年内再次被捕的人更有可能是白人。
因此,ProPublica的公平性指标回顾了算法的正确与错误,然后比较了不同种族的错误率。[Julia Angwin、Jeff Larson、Surya Mattu和Lauren Kirchner/ProPublica]
开发COMPAS的公司Northpointe(现称Equivant)为该工具辩护,认为COMPAS没有偏见,因为高风险分数的白人和高风险分数黑人被重新逮捕的可能性差不多。 [同类]
但诺思波因特的公平观遗漏了一些东西:布劳沃德县(和其他地方)的黑人和白人被捕的比率不同,部分原因是有偏见的警察,所以黑人更有可能记录在案。一种基于逮捕记录预测再犯可能性的算法使同样的种族差异永久化。
佐治亚大学法学教授桑德拉·梅森说:“犯罪率是深层次力量的表现。”。“犯罪率的种族差异(如果存在的话)表明了几个世纪以来种族压迫所产生的持久的社会和经济不平等。”将这些历史上的不平等编入算法可能会导致更多的监禁,进一步加剧几代人的歧视。[桑德拉·梅森/[美国海军陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队陆战队
Northpointe的方法是否仍然“公平”的问题是政策制定者的问题,最终也是这些政策制定者所代表的价值观的社区的问题。虚假否定的潜在公共安全影响可能会在此类讨论中凸显出来,但虚假肯定也应该得到同样或更多的关注。
在审前背景下,假阳性可能意味着一个人在被不必要的拘留期间失业,甚至失业此人更有可能最终被定罪对于判刑或假释决定,假阳性可能导致更长的监禁时间,以及更多的时间远离家人和社区。误报在多大程度上破坏了受影响人民的生活,以及这种破坏的潜在犯罪影响,不应被忽视。
同样值得注意的是,由于诸如Northpointe这样的公司的商业利益,偏见可能不会被发现拒绝完全披露其方法有失去竞争优势的风险。
口译的问题
主要论点之一风险评估的支持者提出的是,即使算法中存在一些偏差,也可以观察、研究和纠正偏差,而人类的偏差是无法做到的。然而,在实践中,算法和人工决策之间的相互作用是复杂的,有时会导致比人工或计算机单独决策更糟糕的结果。
肯塔基州的风险评估经验表明,当人类和算法判断相互作用时,会涉及到一些复杂性。2013年,英联邦推出了阿诺德基金会的公共安全评估(PSA),明确目标是降低审前拘留率。该工具的实施伴随着对低风险和中等风险被告在非货币条件下获释的法定推定。然而,乔治·梅森大学(George Mason University)法学教授梅根·史蒂文森(Megan Stevenson)对风险评估时代肯塔基州保释决定的分析表明,有几个令人担忧的发现。
首先,在采用该算法后,审前释放率的种族差异有所增加,这主要是因为在以白人为主的农村地区,法官提高释放率的速度高于多元化的非农村地区的法官。[梅根·史蒂文森/明尼苏达州法律评论]
此外,史蒂文森的分析表明,由于使用这种工具,早期的监禁收益是短暂的。PSA推出后,肯塔基州的审前羁押率立即大幅下降,63%的“低风险”被告获得了某种形式的非金钱释放。“中等风险”个人的表现也类似。然而,即使在这一急剧下降之后,肯塔基州的审前拘留率仍然高于全国平均水平。[梅根·史蒂文森/明尼苏达州法律评论]
虽然更好的技术有可能使风险评估更加公平,但这一结果远远不能保证。
加利福尼亚州在审前风险评估方面也有着令人不安的历史,这主要是由于法官选择性地应用了这些工具的建议。例如,人权观察报告称,在圣克鲁斯县,“法官同意84%的‘拘留’建议,但只有47%的‘释放’建议。”同样,阿拉米达县法官为四分之三的标有“低风险”的被告保释[人权观察]
是什么原因导致这些法官倾向于不成比例地推翻对被告或被告有利的风险决定?最近的一项研究表明,贫困可能与量刑时的风险评分相互作用,从而对经济上处于不利地位的人作出更严厉的判决。
300多名法官参与了一项受控实验,在该实验中,他们获得了描述被告仅在社会经济地位(相对贫穷与相对富裕)上存在差异的小插曲,以及是否提供了风险评估信息。法官被问及是否会判处此人缓刑或监禁。研究发现,与那些没有看到风险评分的法官相比,收到风险评估信息的法官监禁富裕被告的可能性要低15个百分点。相反,提供相对较差的被告的风险信息与15个百分点相关增加有可能被监禁。 [Jennifer L.Skeem等人/SSRN]
向法官提交风险评估结果的方式可能会影响他们在保释或判决中如何使用这些报告。目前大多数风险评估工具都将受试者描述为“低”、“中”或“高”风险,而不是给出数字风险分数。
例如,联邦法院系统中使用的审前风险评估(PTRA)将受试者的风险水平定为1至5。直觉上,人们可能会认为,这些风险水平中的每一个都对应于风险量表上的20个百分点,因此,处于1级风险的人违反审前释放条件的可能性在1%到20%之间,而处于5级的人几乎肯定会违反,在80%到100%之间。
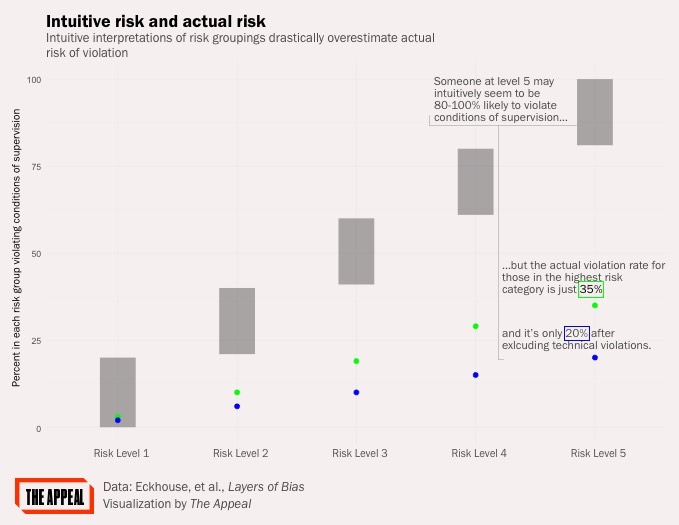
事实上,根据PTRA,只有不到20%的高危人群会因新的违法行为而违反释放条件。依赖这些分数的直观解释的法官不仅会大大高估这样一个人可能带来的实际风险,甚至会高估工具本身的输出。[Laurel Eckhouse等人/刑事司法与行为]
有一些证据表明,将人类的判断完全排除在风险评估过程之外可以提供更好的结果。使用一个经过五年纽约市逮捕数据训练的模型进行的计算机模拟表明,用风险评估工具取代保释决定中的人工判断,可以在不影响犯罪率的情况下将审前监禁减少40%。在该模型的某些版本中,研究人员能够通过确保某一种族被监禁的被告人数不高于该种族被告的百分比来消除一些种族偏见。[Jon Kleinberg等人/NBER]
其他研究表明,机器学习算法在确定被告不出庭的可能性方面可以优于人类法官,而且即使是更简单的算法在这项任务上的表现也几乎与更复杂的机器学习模型一样好。[Jongbin Jung等人/SSRN]
相反,最近的一项研究发现,未经培训的外行人员通过亚马逊的土耳其机器人在预测累犯风险方面与COMPAS进行了比较。然而,评论家声称这种方法上的缺陷使这些结果受到质疑。[Julia Dressel和Hany Farid/科学进展]
这并不是说计算机应该在保释或判刑决定中拥有唯一的自由裁量权。不仅极不可能有任何管辖权将人类完全排除在外(如果这种情况是可取的话),而且正如一个州最高法院发现的那样,这样做甚至可能侵犯宪法规定的正当程序权。
算法诉诸法庭:卢米斯案
在2016年的State v.Loomis案中,威斯康星州最高法院成为围绕风险评估明确解决宪法问题的最高法院。
埃里克·卢米斯(Eric Loomis)对2013年发生的一起驾车枪击案的几项指控认罪。初审法院随后进行了出庭调查,其中包括COMPAS风险评估。
卢米斯被确定为COMPAS打算衡量的所有维度中的“高风险”。他被判处分刑,必须在狱中服刑至少六年,此后还要接受相当长一段时间的监管。Loomis随后提出了一项定罪后动议,对他的判刑提出质疑,理由是使用COMPAS侵犯了他的正当程序权(以及与风险评估无关的其他挑战)。这一挑战最终进入了州高等法院。[州诉卢米斯]
卢米斯对COMPAS在他的案件中的使用方式提出了几点异议。首先,他声称,由于该工具的封闭性和专有性,他无法有效质疑自己的风险评分,这侵犯了他根据准确信息被判刑的权利。法院对这种黑盒模型的使用并不感到困扰,认为卢米斯的双重诉讼权利得到了满足,因为他有能力质疑输入模型的事实的准确性,并提供证据证明COMAS生成的风险评分在应用于他时是不正确的。法院发现,风险评估本身并不能决定对卢米斯的惩罚,而只是众多信息中的一条。[State诉Loomis案]
虽然法院最终拒绝给予Loomis救济,但它确实借此机会阐明了一系列免责声明,这些免责声明必须随风险评估报告一起提交,其中每一项都为法院使用算法进行惩罚提出了重要考虑:
首先,法院规定,当专有风险评估工具不披露其使用的风险因素或分配给它们的权重时,应予以注意。因此,尽管法院没有发现使用秘密算法侵犯了卢米斯的权利,但它还是决定威斯康星州法官在判刑时应牢记这些工具的不透明性。
其次,当用于创建风险评估报告的工具没有经过验证研究,以验证其模型对当地人口的预测时,法院要求风险评估报告附带警告。这个问题并非威斯康星州独有.大多数使用风险评估的州没有此类研究;那些没有提供结果的公司。
法院进一步要求报告承认对上述种族偏见的担忧。随着工具变得无处不在,法院无疑会越来越频繁地回到这个问题上。
只是 由于法院需要确信对社区居民的风险评估是正确的,因此他们必须确保工具在一段时间内保持准确。如果不这样做,可能会导致所谓的僵尸预测,因为过时的数据可能会人为夸大风险。法院的第四条警告正好解释了这种风险。[John Logan Koepke和David G.Robinson/《华盛顿法律评论》]
法院的最终标签警告说,将风险评估工具应用于不同背景的危险性,而非其设计背景,例如使用累犯工具来预测未出庭的风险。
一些批评人士驳斥了卢米斯法院的强制性免责声明,认为“橱窗装饰。”实际上,法院本可以更进一步,实际解决它观察到的一些缺陷,而不仅仅是要求法官指出这些缺陷。然而,如果其他正在考虑风险评估的法院显示出与威斯康星州高等法院同样的意愿,那么仍有乐观的余地。
结论
近年来,算法风险评估的使用激增,尽管努力属于反对这些工具的组织者们,这种趋势似乎不太可能很快减弱。这项技术肯定也会变得更加复杂,这将导致透明度更低,因为今天相对简单、可解释的模型被强大但不透明的深度学习方法所取代。
虽然更好的技术有可能使风险评估更加公平,但这一结果远未得到保证,这取决于设计、实施和使用这些工具的人,以确保他们能够以反映其社区价值观和维护社会边缘人权利的方式来进行评估。