介绍
下一页讨论了如何使用R 波尔 包执行有序logistic回归。 有关结果解释的数学处理方法,请参阅: 如何解释R中有序逻辑回归的系数?
准备
要求 (国外) 要求 (ggplot2) 要求 (质量) 要求 (哈米斯) 要求 (重塑2)
序数逻辑回归示例
数据的描述
日期 <- 阅读.dta ( " https://stats.idre.ucla.edu/stat/data/ologit.dta " ) 头 (日期)
##应用pared公共gpa ##1很可能0 0 3.26 ##2有可能1 0 3.21 ##3不太可能1 1 3.94 ##4有可能0 0 2.81 ##5有可能0 0 2.53 ##6不太可能0 1 2.59
##一次一个,表格应用、整理和公开 重叠地 (日期[, c(c) ( “应用” , “精简” , “公共” )],表)
##$适用 ## ##不太可能,有点可能,很可能 ## 220 140 40 ## ##$帕雷德 ## ## 0 1 ## 337 63 ## ##$公共 ## ## 0 1 ## 343 57
##三向交叉标签(xtabs)并展平表格 自由贸易区 ( xtabs公司 ( ~ 公众的 + 应用 + 削皮, 数据 =日期)
##已对0 1进行pared ##公共申请 ##0不太可能175 14 ##有点可能98 26 ##很可能20 10 ##1不太可能25 6 ##有点可能12 4 ##很可能7 3
总结 (日期 $ gpa)
##最小第1季度中位数平均第3季度最大。 ## 1.90 2.72 2.99 3.00 3.27 4.00
标准偏差 (日期 $ gpa)
## [1] 0.3979
ggplot图 (日期:, 原子发射光谱 ( x个 =适用, 年 =gpa)) + 地理箱线图 ( 大小 = .75 ) + 地理抖动 ( 阿尔法 = .5 ) + 面_网格 (已修剪 ~ 公众, 利润 = 真的 ) + 主题 ( 轴.text。 x个 = 元素_文本 ( 角 = 45 , 刚刚 = 1 , vjust(vjust) = 1 ))
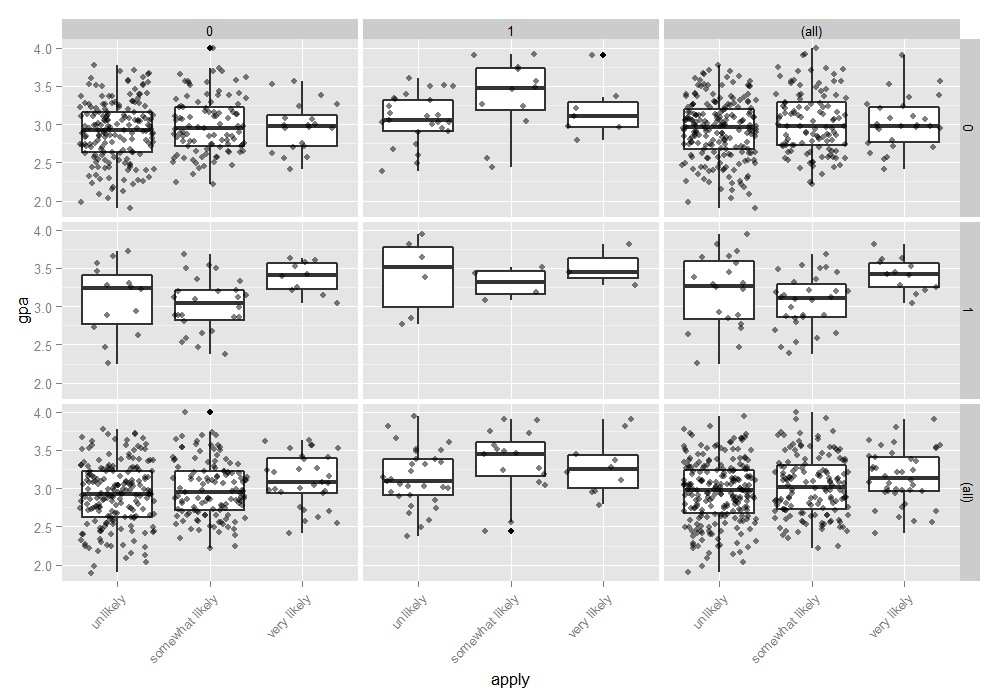
您可能会考虑的分析方法
有序逻辑回归:本页的重点。 OLS回归:此分析存在问题,因为当OLS与非中断使用时,违反了OLS的假设 结果变量。 方差分析:如果你只使用一个连续预测值,你可以“翻转”模型,比如说, gpa公司 是 结果变量和 应用 是预测变量。 然后可以运行单向方差分析。 如果你只有一个预测变量(来自逻辑模型),并且它是连续的,那么这不是一件坏事。 多项式逻辑回归:这与有序逻辑回归类似,只是假设结果变量的类别没有顺序(即类别是标称的)。 这种方法的缺点是,订单中包含的信息会丢失。 有序概率回归:这与运行有序逻辑回归非常类似。 主要区别在于 系数的解释。
有序逻辑回归
定义
##拟合有序logit模型并存储结果“m” 米 <- 波尔 (适用 ~ 削好的 + 公众的 + 平均绩点, 数据 =日期, 赫斯 = 真的 ) ##查看模型摘要 总结 (米)
##致电: ##polr(公式=apply~pared+public+gpa,数据=dat,Hess=TRUE) ## ##系数: ##值标准误差t值 ##对1.0477 0.266 3.942 ##公开-0.0588 0.298-0.197 ##gpa 0.6159 0.261 2.363 ## ##拦截次数: ##值标准误差t值 ##不太可能|有点可能2.204 0.780 2.827 ##有可能|很可能4.299 0.804 5.345 ## ##剩余偏差:717.02 ##AIC:727.02
打电话,我是 R(右) 提醒我们运行的模型类型、指定的选项等。 接下来,我们看到了常见的回归输出系数表,其中包括每个系数的值、标准误差和t值,它只是系数与其标准误差的比值。 默认情况下没有显著性测试。 接下来,我们将看到两个截距的估计值,它们有时被称为切点。 截取显示了潜在变量被切割的位置,以形成我们在数据中观察到的三个组。 请注意,此潜在变量是连续的。 一般来说, 这些都没有用于解释结果。 切入点与其他统计数据包报告的阈值密切相关。 最后,我们看到了模型的剩余偏差-2*对数似然 作为AIC。 偏差和AIC对于模型比较都很有用。
##存储表 (可食用 <- 系数 ( 总结 (m) ))
##值标准误差t值 ##对1.04769 0.2658 3.9418 ##公开-0.05879 0.2979-0.1974 ##谷丙转氨酶0.61594 0.2606 2.3632 ##不太可能|有点可能2.20391 0.7795 2.8272 ##有点可能|很可能4.29936 0.8043 5.3453
##计算并存储p值 第页 <- pnorm(人名) ( 防抱死制动系统 (可检测[, “t值” ]), 下尾翼 = 错误的 ) * 2 ##组合表 (可食用 <- cbind公司 (可卡因, “p值” =p))
##值标准误差t值p值 ##对1.04769 0.2658 3.9418 8.087e-05 ##公开-0.05879 0.2979-0.1974 8.435e-01 ##gpa 0.61594 0.2606 2.3632 1.812e-02 ##不太可能|有点可能2.20391 0.7795 2.8272 4.696e-03 ##有可能|很可能4.29936 0.8043 5.3453 9.027e-08
(ci) <- 限制(confint) (m) ) #默认方法提供配置的CI
## 2.5 % 97.5 % ##对0.5282 1.5722 ##公众-0.6522 0.5191 ##平均绩点0.1076 1.1309
限制.默认 (米) #假设正常的CI
## 2.5 % 97.5 % ##对0.5268 1.569 ##公众-0.6426 0.525 ##gpa 0.1051 1.127
##优势比 经验 ( 系数 (m) )
##削减公共gpa ## 2.8511 0.9429 1.8514
##OR和CI 经验 ( cbind公司 ( 或 = 系数 (m) ,ci))
##或2.5%97.5% ##对2.8511 1.6958 4.817 ##公开0.9429 0.5209 1.681 ##gpa 1.8514 1.1136 3.098标准
解释比值比
父母教育
(*) 适用于家长 做了 上大学的几率 更多 可能(即。, 非常 或 有点 可能与不可能)申请人数是父母没有上过大学的学生的2.85倍,其他所有变量保持不变。 对于父母这样做的学生 不 上大学的几率 较少的 可能适用(即。, 不可能的 与一些或很可能)相比,这是父母上过大学的学生的2.85倍,所有其他变量保持不变。
学校类型
对于公立学校的学生来说 更多 可能(即。, 非常 或 有点 可能与不可能)申请人数比私立学校学生低5.71%(即(1-0.943)x 100%),其他所有变量保持不变。 (*) 对于私立学校的学生来说 更多 在所有其他变量(正比值比)不变的情况下,适用的可能性是公立学校学生的1.06倍(即1/0.943)。
对于私立学校的学生来说 更少 可能适用(即。, 不可能的 与有点或很可能的)相比,比公立学校学生低5.71%,保持所有其他变量不变。 对于公立学校的学生来说 更少 可能适用的是私立学校学生的1.06倍,所有其他变量(正比值比)保持不变。
平均绩点
(*) 每台机组 在里面 折痕 在学生的GPA中 更多 可能适用( 非常 或 有点 可能性与不可能性)相乘1.85倍(即增加85%),保持所有其他变量不变。 每台机组 减少 在学生的GPA中 较少的 可能适用( 不可能的 与一些或很可能的)相乘1.85倍,保持所有其他变量不变。
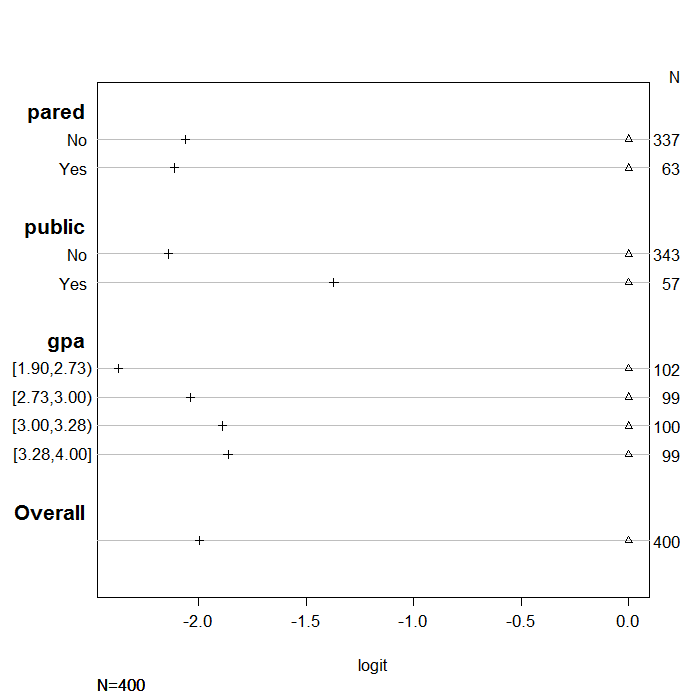
比例赔率假设
平方英尺 <- 功能 ( 年 ) { c(c) ( 'Y>=1' = qlogis公司 ( 意思是 (年) >= 1 )), “Y>=2” = qlogis公司 ( 意思是 (年) >= 2 )), “Y>=3” = qlogis公司 ( 意思是 (年) >= 三 ))) } (个) <- 具有 (日期:, 总结 ( as.数字 (适用) ~ 削好的 + 公众的 + 平均绩点, 乐趣 =平方英尺))
##作为数字(应用)N=400 ## ## +-------+-----------+---+----+--------+------+ ##||N|Y>=1|Y>=2|Y>=3| ## +-------+-----------+---+----+--------+------+ ##|pared |否|337|Inf|-0.37834|-2.441| ##||是|63|Inf|0.76547|-1.347| ## +-------+-----------+---+----+--------+------+ ##|公共|否|343|Inf|-0.20479|-2.345| ##||是|57|Inf|-0.17589|-1.548| ## +-------+-----------+---+----+--------+------+ ##|gpa|[1.90,2.73)|102|Inf|-0.39730|-2.773| ##||[2.73,3.00)|99|Inf|-0.26415|-2.303| ##||[3.00,3.28)|100|Inf|-0.20067|-2.091| ##||[3.28,4.00]|99|Inf|0.06062|-1.804| ## +-------+-----------+---+----+--------+------+ ##|整体||400|Inf|-0.20067|-2.197| ## +-------+-----------+---+----+--------+------+
glm公司 ( 我 ( as.数字 (适用) >= 2 ) ~ 削皮, 家庭 = “二项式” , 数据 =日期)
## ##调用:glm(公式=I(如数字(应用)>=2)~pared,family=“二项式”, ##数据=dat) ## ##系数: ##(截距)准备 ## -0.378 1.144 ## ##自由度:总计399(即零); 398残留物 ##零偏差:551 ##剩余偏差:534 AIC:538
glm公司 ( 我 ( as.数字 (适用) >= 三 ) ~ 精简, 家庭 = “二项式” , 数据 =日期)
## ##调用:glm(公式=I(如数字(应用)>=3)~pared,family=“二项式”, ##数据=dat) ## ##系数: ##(截距)准备 ## -2.44 1.09 ## ##自由度:总计399(即零); 398残留物 ##零偏差:260 ##剩余偏差:252 AIC:256
s[, 4 ] <- s[, 4 ] - s[, 三 ] s[, 三 ] <- s[, 三 ] - s[, 三 ] 秒 #打印
##作为数字(应用)N=400 ## ## +-------+-----------+---+----+----+------+ ##||N|Y>=1|Y>=2|Y>=3| ## +-------+-----------+---+----+----+------+ ##|pared |否|337|Inf|0|-2.062| ##||是|63|Inf|0|-2.113| ## +-------+-----------+---+----+----+------+ ##|公共|否|343|Inf|0|-2.140| ##||是|57|Inf|0|-1.372| ## +-------+-----------+---+----+----+------+ ##|gpa|[1.90,2.73)|102|Inf|0|-2.375| ##||[2.73,3.00)|99|Inf|0|-2.038| ##||[3.00,3.28)|100|Inf|0|-1.890| ##||[3.28,4.00]|99|Inf|0|-1.864| ## +-------+-----------+---+----+----+------+ ##|整体||400|Inf|0|-1.997| ## +-------+-----------+---+----+----+------+
情节 (s,), 哪一个 = 1 : 三 , 多氯联苯 = 1 : 三 , xlab公司 = “logit” , 主要的 = ' ' , xlim公司 = 范围 (s[, 三 : 4 ]))
新数据 <- 数据帧 ( 削过的 = 代表 ( 0 : 1 , 200 ), 公众的 = 代表 ( 0 : 1 , 每个 = 200 ), 普通合伙人 = 代表 ( 序列 ( 从 = 1.9 , 到 = 4 , 长度.out = 100 ), 4 )) 新数据 <- cbind公司 (新日期, 预测 (m,新日期, 类型 = “问题” )) ##显示前几行 头 (新日期)
##削减公共gpa不太可能有点可能非常可能 ## 1 0 0 1.900 0.7376 0.2205 0.04192 ## 2 1 0 1.921 0.4932 0.3946 0.11221 ## 3 0 0 1.942 0.7325 0.2245 0.04299 ## 4 1 0 1.964 0.4867 0.3985 0.11484 ## 5 0 0 1.985 0.7274 0.2285 0.04407 ## 6 1 0 2.006 0.4802 0.4023 0.11753
lnewdat(新数据) <- 熔化 (新日期, 标识.vars = c(c) ( “已修剪” , “公共” , “gpa” ), 变量名称 = “级别” , 值名称 = “概率” ) ##查看前几行 头 (新数据)
##公共gpa水平概率 ##1 0 0 1.900不太可能0.7376 ##2 1 0 1.921不太可能0.4932 ##3 0 0 1.942不太可能0.7325 ##4 1 0 1.964不太可能0.4867 ##5 0 0 1.985不太可能0.7274 ##6 1 0 2.006不太可能0.4802
ggplot图 (lnewdat, 原子发射光谱 ( x个 =gpa, 年 =概率, 颜色 =级别) + 地理线 () + 面_网格 (已修剪 ~ 公众, 贴标机 = “标签_两者” )

需要考虑的事项
完美预测:完美预测意味着预测变量的一个值是 仅与响应变量的一个值关联。 如果是这样 发生这种情况时,Stata通常会在输出的顶部发出注释 删除案例以便模型可以运行。 样本量:订购物流和订购probit,使用 最大似然估计需要足够的样本量。 有多大 大是一个有争议的话题,但它们几乎总是需要比OLS回归更多的案例。 空单元格或小单元格:您应该检查是否为空或小单元格 通过在分类预测因子和 结果变量。 如果一个细胞只有很少的病例 模型可能变得不稳定或根本无法运行。 伪R平方:找不到R平方的精确模拟 在OLS中。 伪R平方有很多种版本。 请参阅 Long和Freese 2005,了解更多细节和各种解释 伪R平方。 诊断:对非线性模型进行诊断很困难,有序logit/probit模型甚至比二进制模型更困难。 有关逻辑回归模型诊断的讨论,请参见Hosmer和Lemeshow(2000年,第5章)。 注意,逻辑回归的诊断与概率回归的诊断类似。
工具书类
Agresti,A.(1996) 分类数据简介 分析 纽约:John Wiley&Sons,Inc Agresti,A.(2002) 分类数据分析, 第二版 新泽西州霍博肯:John Wiley&Sons,Inc。 哈雷尔,F.E(2001) 回归建模策略 纽约:Springer-Verlag。 廖天凤(1994) 解释概率 模型:Logit、Probit和其他广义线性模型 加利福尼亚州千橡树市:Sage Publications,Inc。 Powers,D.和Xie,Yu。 分类数据分析的统计方法。 英国宾利:Emerald Group Publishing Limited。