最终决定取决于该公司组件技术与开发集团副总裁兼总经理Albert Y.C.Yu。几年来,俞敏洪一直被科恩建造超高速RISC微处理器的热情所吸引,但他觉得英特尔缺乏资源来投资这样一个项目。由于这个非常新颖的想法出自工程团队,余告诉Spectrum,他发现一些英特尔高管犹豫不决。然而,在1985年底,他决定,尽管他的不确定性,RISC芯片的时代已经到来。“很大程度上取决于直觉,”他说。“你要在这些事情上冒险。”
1986年1月,当做出这一决定的那一刻,热度就开始了。英特尔的RISC芯片必须在竞争激烈之前进入市场,而随着该项目与486设计一起启动,这两个集团可能不得不争夺计算机时间和支持人员。科恩通过确保N10的努力持续领先于486,解决了这场冲突。为了减少官僚作风和通信开销,他决定N10团队将拥有尽可能少的工程师。
人员配备
在俞敏洪批准该项目后,希尔斯伯勒项目的工程师赛维福(Sai Wai Fu)就搬到了圣克拉拉(Santa Clara),加入科恩(Kohn)担任团队的共同经理。傅和科恩在帕萨迪纳加州理工学院(California Institute of Technology in Pasadena)上学时就认识了,在英特尔(Intel)重聚,并在科恩早先的RISC尝试中合作过。傅急于再找一次机会,接手了招聘工作,争相组建一支由优秀工程师组成的兼容团队。他不仅激发了突破百万晶体管壁垒的激情,还激发了自己的管理哲学:通过挑战工程师的专业领域之外的知识来拓宽他们的视野。
为了减少官僚主义和通信开销,[莱斯利·科恩]决定N10团队将拥有尽可能少的工程师。该项目吸引了公司内许多经验丰富的工程师。Piyush Patel曾是80386的首席逻辑设计师,他加入了N10团队,而不是486项目。
“这很冒险,”他说,“但更具挑战性。”
设计工程师P.Sit议员也选择了N10而不是486,因为他说:“有了486,我会研究控制逻辑,我知道怎么做。我以前就做过。N10需要人来处理浮点单元,我对浮点知之甚少,所以我很有兴趣学习。”
正如486名团队经理约翰·克劳福德(John Crawford)所说,N10团队除了吸引“逃犯”外,还从英特尔技术开发团队请来了三名内存设计专家,这很重要,因为将有大量的片上内存。最后,科恩和傅聘请了一些刚从大学毕业的工程师。工程师人数增加到20人,比他们最初认为需要的人数多了8人,但还不到486人团队人数的三分之二。
把它写在纸上
1986年初,他在NEC问题上没有与英特尔的律师联系版权诉讼(英特尔起诉NEC,指控其8086的微代码侵犯版权),Kohn完善了他对N10将包含什么以及如何将其整合在一起的想法。他非正式地咨询了克劳福德。
克劳福德说:“预计N10和486都将超过400英里,我对其尺寸有点紧张。”。“但[科恩]说,‘嘿,如果不是450,我们可以忘记它,因为我们在模具上没有足够的功能。所以我们应该选择450,并认识到这些东西几乎不会缩小。’”
他们意识到,芯片的侧面可能会超过450密耳。实际的i860是396乘602密耳。
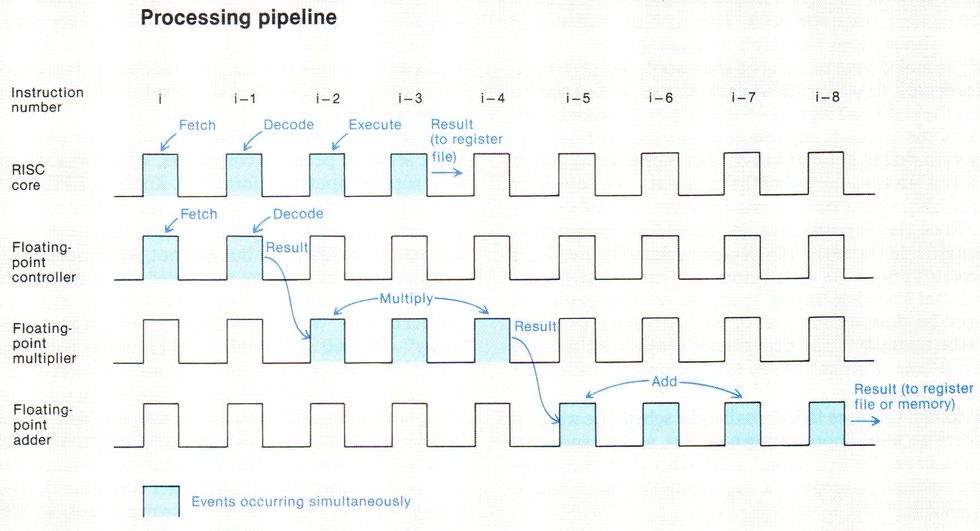
Kohn首先呼吁RISC内核具有快速整数性能、用于指令和数据的大型缓存以及用于快速浮点计算的专用电路。大多数微处理器执行浮点操作需要5到10个时钟周期,Kohn的目标是通过流水线将其缩短为一个周期。他还希望总体上有一条64位的数据总线,但在数据缓存和浮点段之间有一条128位的总线,这样浮点段在访问数据时就不会遇到瓶颈。就像超级计算机一样,芯片必须执行向量运算,并并行执行不同的指令。
浮点加法器和乘法器单元的设计者使舍入数字的逻辑符合IEEE标准,从而降低了性能。(例如,克雷研究公司(Cray Research Inc.)的计算机拒绝采用这些标准来提高性能。)虽然一些N10工程师想要更高的性能,但他们发现客户更喜欢符合标准。
然而,他们确实发现了一种方法,可以快速绘制工程师和科学家要求的三维图形,而不需要任何痛苦的权衡。设计者能够通过在浮点硬件上搭载少量额外电路来添加此功能,仅增加芯片尺寸的3%,但将图形计算的处理速度提高了10倍,达到每秒1600万个16位图像元素。
使用RISC处理器,在一个时钟周期内从高速缓存执行加载通常需要额外的寄存器写入端口,以防止加载信息与算术逻辑单元返回的结果之间的干扰。N10团队找到了一种方法,可以在一个周期内对两条信息使用相同的端口,从而在不损失速度的情况下节省电路。快速访问指令和数据是RISC处理器的关键:因为指令很简单,所以可能需要更多的指令。设计者开发了新的电路设计技术,并已申请专利,允许通过仅消耗2.5瓦的超大总线对大型缓存进行单周期访问。
科恩说:“现有的SRAM部件可以在相当长的时间内访问数据,但它们消耗了大量电量。”。
没有爬行的优雅
这一百万个晶体管意味着这两年半的发展中有很大一部分时间花在了电路设计上。负责芯片不同部分的八个小组呼吁进行仔细管理,以确保每个部分在组装后能够与其他所有部分无缝协作。
首先,N10的设计理念是:没有爬行的优雅。该团队的电路设计经理Roland Albers说:“令人毛骨悚然的优雅扼杀了许多芯片。”。他说,电路设计师应该避免重新发明轮子。如果一个典型的周期是20毫微秒,而一种既定的技术会导致一条需要15毫微秒的路径,那么工程师应该接受这一点并继续进行下一个电路。
“如果你让人们投入其中,尝试他们想要的任何东西,尝试他们在杂志上读到的任何技巧,你最终会得到许多边缘化和片状的电路”
-罗兰·阿尔伯斯
路径计时记录在初始项目规范中,并在电路的实际设计开始后,在阿尔伯斯召集的每周会议上进行更新。
阿尔伯斯说:“如果你让人们投入其中,尝试他们想要的任何东西,尝试他们在一些杂志上读到的任何技巧,你最终会得到很多边缘化和片状的电路。”。“相反,我们只是把它推到必须推的地方。这就产生了一个可制造且可靠的部件,而不是一个用于一大堆新电路的测试芯片。”
除了提高可靠性外,禁止爬行优雅也加快了整个过程。
为了确保芯片不同块的电路能够干净地啮合,阿尔伯斯和他的电路设计师编写了一本手册,介绍他们的工作。与英特尔CAD部门的工程师一起,他开发了一个基于图形的电路模拟环境,工程师可以使用该环境输入模拟原理图,包括设备寄生电容和互连的图形化而非字母数字化。然后在工作站上以图形波形的形式检查输出。
在每周的会议上,每一位完成一项设计的工程师都会提交他的结果。其他人将确保它不承担不必要的风险,坚持既定的方法,并且其信号将与芯片的其他部分集成。
英特尔有直接从模拟芯片逻辑的高级语言生成布局设计的工具。团队是否应该使用它们?这样的工具可以节省时间并消除人类设计者引入的错误,但往往不会生成非常紧凑的电路。与手工电路设计相比,英特尔自己用于布局设计的自动放置工具将密度降低了约一半,速度减慢了三分之一。英特尔工程师表示,商用工具的表现更糟。
决定何时何地使用这些工具非常简单:操作数据的浮点逻辑和RISC核心的那些部分必须手动设计,缓存也是如此,因为它们涉及大量重复。一些单元被重复数百次,甚至数千次(SRAM单元被重复100000次),因此手工封装所涉及的电路所获得的空间远远超过两倍。然而,在控制逻辑很少或没有重复的情况下,节省时间被认为是值得的,特别是因为电路的自动生成允许在最后一刻进行更改以纠正芯片的操作。
在芯片的一百多万个晶体管中,约有40000个是自动布局的,而大约10000个是手动生成并复制的,以生产剩余的980000个晶体管。
在芯片的一百多万个晶体管中,约有40000个是自动布局的,而大约10000个是手动生成并复制的,以生产剩余的980000个晶体管。该团队的工程师之一罗伯特·威洛纳(Robert G.Willoner)表示:“如果我们必须手动完成这40000个步骤,那么就会增加几个月的进度,并引入更多错误,因此我们可能无法对第一块硅进行取样。”。
这些布局生成工具以前曾在英特尔公司使用过,该团队相信它们会起作用,但他们不太确定自动设计的电路会占用多少空间。
阿尔伯斯说:“这比我们想象的要多花一点时间,最终导致了一些问题,所以我们不得不稍微增加模具尺寸。”
未经授权使用工具
即使采用自动布局,控制逻辑的一部分,即总线控制器,也开始落后于计划。由于担心控制器会成为整个设计的瓶颈,团队尝试了几种新技术。RISC处理器通常被设计为与快速SRAM系统接口,该系统充当外部高速缓存,并依次与DRAM主存储器接口。然而,这里的计划是让用户能够绕过SRAM,将处理器直接连接到DRAM,这将允许芯片设计成低成本系统,并处理非常大的数据结构。
因此,总线在从DRAM返回第一个数据之前可以管道化多达三个周期,并且数据有时间在缓慢的DRAM内存中传输,而不会占用处理器。总线还必须使用静态列模式,这是最新DRAM的一项功能,允许顺序地址访问内存中的同一页,通过单独的引脚告诉系统该位与前一位位于同一页。
这两个功能都带来了意想不到的设计复杂性,第一个原因是控制逻辑必须跟踪杰出公交车循环的各种组合。虽然芯片的其余部分已经布局好了,但总线设计者仍在努力进行逻辑模拟。甚至没有时间进行手动电路设计,然后进行自动布局,然后根据布局检查设计。
其中一位设计师从英特尔CAD部门的一位朋友那里听说了一种工具,它可以从逻辑模拟级别进行设计,优化电路设计,并生成优化布局。该工具消除了电路示意图所占用的时间,以及检查示意图错误。然而,它仍在开发中,尽管当时486团队正在对其进行测试和调试(他们比N10团队在截止日期前还有几个月的时间),但它还没有准备好使用。
N10设计师通过内部计算机网络访问CAD部门的主机并复制程序。它起到了作用,解决了总线控制瓶颈。
CAD经理Nave谨慎地说:“在那个阶段,一个工具肯定会有问题。使用它的特定工程师有能力自己解决大多数问题,所以它没有任何可能产生的负面影响。在N10的情况下,它可能工作得很好,但作为一种常规做法,我们并不宽恕。”
可测试性设计
N10的设计者从一开始就担心如何测试一个拥有一百万个晶体管的芯片。为了确保芯片能够得到充分的测试,1987年初,在项目进行到一半时,一名产品工程师被调往N10团队。起初,Beth Schultz只是与其他人一起进行电路设计,熟悉芯片的功能。后来,她编写了诊断程序,现在,她回到产品工程部门,负责监督i860向英特尔制造业务的转移。
第一次测试芯片的尝试证明了产品工程早期参与的重要性。在正常情况下,设计部门的一个小型测试仪,一个带有个人计算机接口的逻辑分析仪,在产品工程中的大型测试仪介入之前很久就在研究一种新芯片的电路。设计部门的测试人员依次调试产品工程部运行的测试程序。这一次,由于一位产品工程师对芯片已经非常熟悉,所以她所在部门的测试员比设计部门的测试员先操作。
产品工程师在团队中的出现也让其他设计师更加关注可测试性问题,i860从几个方面反映了这一点。当逻辑设计师设置总线的引脚定时时,会咨询产品工程师,以确保它不会超出测试仪的能力。生产工程师不断提醒N10团队,需要将信号管脚的数量限制在128个:即使超过一个,也需要花费数百万美元购买新的测试仪。(i860有120个信号引脚,以及48个电源和接地引脚。)
芯片的控制逻辑由水平敏感扫描设计(LSSD)形成。开拓者IBM公司.,这种可测试性设计技术通过专用引脚发送信号来测试单个电路,而不是依赖于指令序列。然而,LSSD并没有被用于数据通路电路,因为设计者认为它会占用太多空间,而且会降低芯片的速度。相反,少量的附加逻辑可以让指令缓存的两个32位段相互测试。边界扫描功能允许系统设计者检查芯片的输入和输出连接,而无需运行指令。
通常,设计和工艺工程师“不会说同一种语言。因此,将技术与体系结构紧密结合是独一无二的。”
-阿尔伯特Y.C.于
规划i860的老化需要设计团队和可靠性工程师进行大量谈判。i860通常使用64位指令;对于老化,可靠性工程师希望尽可能少的连接:64个太多了。
“最初,”傅说,“他们从零线开始。他们想让我们进行自检。所以我们说,‘15或20条怎么样?’”
他们采用了仅用于烧录的8位模式,但有了这一功能,i860用户可以从8位宽的可擦除可编程ROM启动系统。
设计人员还与该小组密切合作,开发了1微米制造工艺,首次用于1988年初出现的80386芯片的压实。英特尔副总裁余表示,通常情况下,设计和工艺工程师“不会说同一种语言。因此,将技术与架构紧密联系在一起是独一无二的。”
英特尔Hillsboro工厂工艺开发工程经理William Siu表示:“该工艺设计的寄生电容非常低,这使得电路可以制造出高性能、低功耗的电路。我们必须与设计人员合作,向他们展示我们的局限性。”
工艺工程师对片上缓存的影响最大。“最初,”设计师帕特尔说,“我们不确定这些缓存有多大。我们认为我们不能放入我们想要的那么大的缓存,但他们告诉我们,这个过程足够好,可以做到这一点。”
时机问题
i860最独特的架构特性可能是其片上并行性。指令缓存的两个32位段同时发出两条32位指令,一条到RISC核心,另一条到浮点部分。更进一步,某些浮点指令同时调用加法器和乘法器。结果是在一个时钟周期内总共有三个操作被执行。
该体系结构提高了芯片的速度,但由于它使时序复杂化,因此实现起来存在问题。例如,如果两个或三个并行操作请求相同的数据,则必须串行提供。芯片设计中发现的许多错误都与这种同步有关。
当需要的数据暂时不可用时,冻结单元的逻辑是最大的计时难题之一。最初,设计者认为这种情况不会出现得太频繁,但芯片上的并行性导致这种情况的发生频率比预期的要高。
Patel说,冻结逻辑一直在增长,直到“它变得如此笨拙,我们决定坐下来重新设计整个冻结逻辑。”这不是一个微不足道的决定——芯片的设计进度大约完成了一半,一次修改需要四名工程师一个多月的时间。
即使在大型主机上运行,电路模拟也陷入了困境。工程师们会设置一个在周末运行,当他们周一到达时发现它不完整。
随着晶体管的数量接近100万个大关,曾经帮助很大的CAD工具开始出现故障。英特尔公司已经在内部开发了CAD工具,相信自己的工具将与流程和设计技术紧密结合,从而提高效率。但N10代表着80386的巨大进步,80386是英特尔迄今为止最大的微处理器,CAD系统从未应用于任何接近新芯片大小的项目。事实上,由于i860的并行性导致了大量可能的组合(已经测试了数千万;总数是这个数字的许多倍),因此其复杂性是惊人的。
即使在大型主机上运行,电路模拟也陷入了困境。工程师们会设置一个在周末运行,当他们周一到达时发现它不完整。等待时间太长了,所以他们使用CAD工具来更改模拟程序。一个通过布局来定位短路的工具运行了几天,然后放弃了。威洛纳说:“我们必须进去改变程序的算法。”。
该团队最初计划绘制整个芯片布局,以帮助调试,但发现绘制器需要一周多的时间全天候运行。他们放弃了,而是在工作站上检查芯片的各个区域。
但现在,运行所有这些工具的大型机开始停滞不前。工程师们开始设置闹钟,使其在夜间响几次,然后通过家里的终端登录系统,重新启动任何崩溃的计算机运行。
网络列表软件完全失败;示意图太大了。
在a之前芯片设计被移交给制造部门进行其第一次硅运行,这是一种称为tape-out的转移-计算机执行全芯片验证,将原理图与布局进行比较。要做到这一点,它需要一个网络列表,一个以字母数字形式表示的示意图的中间版本。网络列表通常只在下线前几天创建,此时设计是最终的。但N10团队知道486团队紧跟其后,很快就会有需求,而且作为优先项目,他们得到了制造部门的资源,因此提前两个月进行了完整的芯片验证试运行,设计不完整。
而网络列表软件完全失败了;示意图太大了。阿尔伯斯说:“我们当时正接近退出,突然发现我们无法将这件事上网。”。“三天之内,我们的一位工程师想出了一个解决办法,但这让我们有一段时间感到害怕。”
变成硅
8月中旬之后,当芯片被移交给产品工程部门准备生产时,设计团队所能做的一切就是等待、担心和调整测试程序,希望第一次硅运行能够证明其功能足以完全测试。六周后,当第一批晶圆到达时,它们已经足够完整,可以进行测试,但还不足以进行包装。通常,设计和产品工程团队会等到晶圆完成生产过程后再进行测试,但这次不会。
设计工程师拉杰夫·巴拉德瓦吉(Rajeev Bharadhwaj)周一飞往俄勒冈州(Oregon),提取第一批热下生产线的晶圆。晚上9点30分,他回到了圣克拉拉,整个设计团队以及产品工程师和营销人员都在那里等待,而第一个测试序列的频率不超过10 MHz,远低于33 MHz的目标。这看起来像是一场灾难,但在工程师们花了20分钟紧张地检查芯片中的关键路径以寻找瓶颈后,有人注意到电源插脚没有连接,芯片只从时钟信号及其I/O系统中获取电力。一旦连接了电源插脚,芯片就可以轻松地在40 MHz下运行。
到凌晨3点,大约8000个测试向量已经通过了产品工程师花了六个月时间创建的芯片向量机。这足以让团队自信地宣布:“它奏效了!”
这个i860名称选择该芯片是为了表明新芯片确实与80486有轻微的关系,因为芯片的数据结构具有相同的字节顺序,并且具有兼容的内存管理系统,它们可以在一个系统中协同工作并交换数据。
这个小芯片上市了
英特尔预计,到今年第四季度,33 MHz芯片的售价为750美元,40 MHz版本的售价为1037美元,并且已经向客户发货了样品。(386的外围芯片可以与i860一起使用,并且已经上市。)由于i860具有与386相同的数据存储结构,386的操作系统可以轻松适应新产品。
英特尔宣布将联合开发一款用于i860的多处理版本UnixAT&T公司。(Unix Software Operation,Morristown,N.J.)、Olivetti Research Center(加利福尼亚州Menlo Park)、Prime Computer(马萨诸塞州Natick市Commercial Systems Group)和Convergent Technologies(加利福尼亚州圣何塞,Unisys Corp.的一个分公司)。泰克数控和Kontron Elektronik股份有限公司计划为芯片制造调试器(逻辑分析仪)。
英特尔为软件开发人员开发了一个基本工具包(汇编程序、模拟器、调试器等)以及Fortran和C编译器。此外,英特尔还有一个Fortran矢量器,这是一个自动将标准Fortran代码重组为矢量进程的工具,该技术以前只适用于超级计算机。
国际商用机器公司计划将i860用作PS/2系列个人电脑的加速器,这将使其性能接近超级计算机。康特隆,SPEA软件公司第九计算机公司将在个人电脑图形板中使用i860。微软公司。已认可该架构,但尚未发布产品。
微型计算机供应商对该芯片感到兴奋,因为该芯片的整体性能远远高于项目开始时的预期。
科恩说:“我们今天在微处理器上有了Dhrystone记录”——85000,频率为40 MHz。(Dhrystne是代表平均整数程序的合成基准,用于测量微处理器或计算机系统的整数性能。)Olivetti是一家将在小型计算机中使用N10的公司,PCS Computer Systems Inc.也是如此。
Megatek公司是第一家宣布计划在市场上生产基于i860的工作站的公司,该芯片将与Sun公司的SPARC、摩托罗拉公司的88000、Integraph公司的Clipper和MIPS计算机系统公司的R3000等其他RISC微处理器竞争。
英特尔认为其芯片超越了当前32位微处理器。该公司的工程师认为i860还有另一个优势:虽然必须在其他微处理器中添加浮点芯片、图形芯片和缓存才能构建完整的系统,但i860是完全集成的,因此消除了通信开销。然而,一些评论家认为这是一个缺点,因为它限制了系统设计者的选择。这一功能是否能够克服其他芯片在市场上的领先优势,还有待观察。
i860团队希望其他微处理器制造商也能仿效他们自己的64位产品,除了集成到单个芯片上的RISC整数处理之外,还有其他功能。然而,作为新一代RISC的领导者,英特尔希望i860能为工作站设定一个标准,就像8086为个人电脑设定的标准一样。
进一步探究
英特尔第一篇描述i860的论文,作者Leslie Kohn和Sai Wai Fu-“1000000晶体管微处理器”-发表于1989年国际固态电路会议技术论文摘要,1989年2月,第54-55页。
精简指令集计算(RISC)的优点在“朝向更简单、更快的计算机Paul Wallich著(IEEE Spectrum,1985年8月,第38-45页)。
编者按2022年6月:i860(N10)微处理器并没有在市场上掀起轩然大波。尽管它处理图形的速度令人印象深刻,并找到了作为图形加速器的利基,但它在通用应用程序上的性能令人失望。英特尔在20世纪90年代中期停止了该芯片。