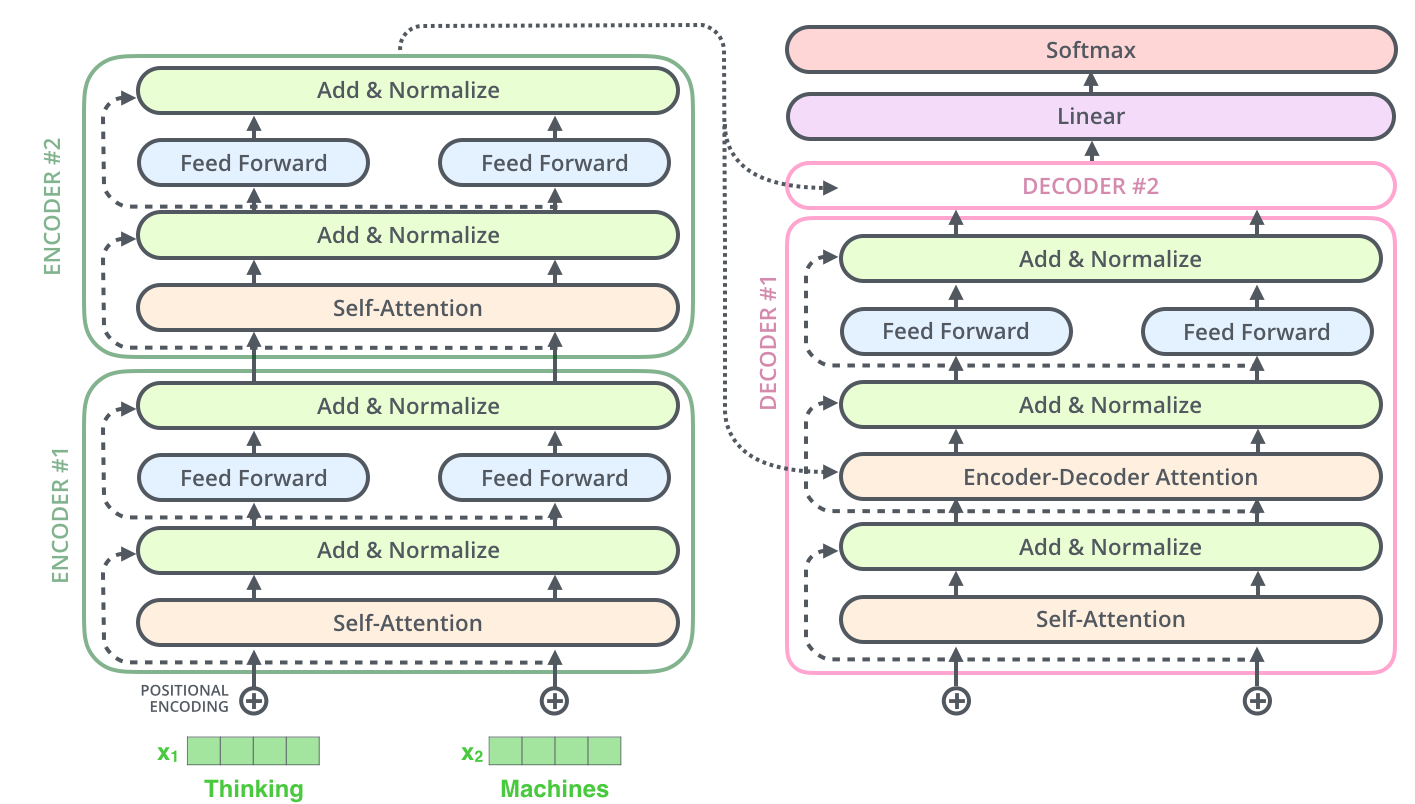
模型体系结构
{kind=link}
班 编码器解码器 ( nn个 . 模块 ):
定义 __初始化__ ( 自己 , 编码器 , 解码器 , 输入_嵌入 , 输出_嵌入 ):
超级的 ( 编码器解码器 , 自己 ). __初始化__ ()
自己 . 编码器 = 编码器
自己 . 解码器 = 解码器
自己 . 输入_嵌入 = 输入_嵌入
自己 . 输出_嵌入 = 输出_嵌入
定义 向前地 ( 自己 , 输入ID , 输出ID ):
返回 自己 . 解码 ( 自己 . 编码 ( 输入ID ), 输出ID )
定义 编码 ( 自己 , 输入ID ):
输入_嵌入 = 自己 . 输入_嵌入 ( 输入ID )
返回 自己 . 编码器 ( 输入_嵌入 )
定义 解码 ( 自己 , 编码器_输出 , 输出ID ):
输出_嵌入 = 自己 . 输出_嵌入 ( 输出_嵌入 )
返回 自己 . 解码器 ( 输出_嵌入 , 编码器_输出 )
1.多头自我关注
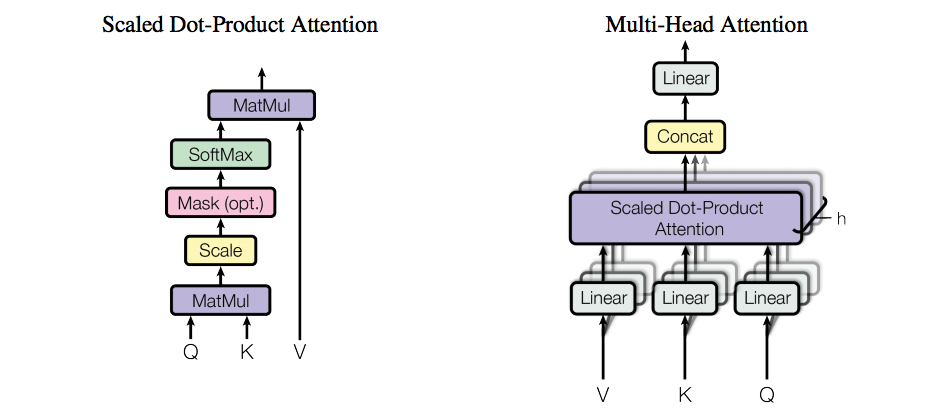
缩放式点产品关注
定义 scaled_dot产品关注 ( 问 , K(K) , V(V) , attn_掩码 ):
#Q:[batch_size,n_heads,L_Q,d_k] #K:[批大小,n_heads,L_K,d_K] #V:[批大小,n_heads,L_k,d_V] 达克 = 问 . 大小 ( 1 )
非标准化attn分数 = 火炬 . 马特姆 ( 问 , K(K) . 转置 ( - 1 , - 2 )) / 净现值 . 平方英尺 ( 达克 ) #分数:[batch_size,n_heads,L_q,L_k] 非标准化attn分数 . 屏蔽填充(_F)_ ( attn_掩码 , - 第1版9 ) #用掩码为1的值填充自张量的元素。 标准化attn_scores = nn个 . Softmax软件 ( 昏暗的 =- 1 )( 未规范化的attn_scores )
输出 = 火炬 . 马特姆 ( 标准化attn_scores , V(V) ) #[批大小,n_heads,L_q,L_v] 返回 输出
多头注意力
班 多头部注意 ( nn个 . 模块 ):
定义 __初始化__ ( 自己 , n个封头 , 隐藏_大小 ):
超级的 ( 多头注意力 , 自己 ). __初始化__ ()
自己 . 隐藏_大小 = 隐藏_大小
自己 . n个封头 = n个封头
自己 . d模型 = 整数 ( 自己 . 隐藏_大小 / 自己 . n个封头 )
自己 . 所有头部大小 = 自己 . n个封头 * 自己 . d模型
自己 . 工作质量(_Q) = nn个 . 线性的 ( 自己 . 隐藏_大小 , 自己 . 所有头部大小 )
自己 . W_K(_K) = nn个 . 线性的 ( 自己 . 隐藏_大小 , 自己 . 所有头部大小 )
自己 . W(V) = nn个 . 线性的 ( 自己 . 隐藏_大小 , 自己 . 所有头部大小 )
定义 向前地 ( 自己 , 问 , K(K) , V(V) , attn_掩码 ):
#dk=dv=d模型 #q:[批次大小,L_q,d_model] #k:[批次大小,L_k,d_model] #v:[批次大小,L_k,d_model] 残留物 , 批处理大小 = 问 , 问 . 大小 ( 0 )
q秒 = 自己 . 工作质量(_Q) ( 问 ). 看法 ( 批处理大小 , - 1 , 自己 . n个封头 , 自己 . d模型 ). 转置 ( 1 , 2 ) #[批次大小,n头,长度q,d模型] k秒 = 自己 . W_K(_K) ( K(K) ). 看法 ( 批处理大小 , - 1 , 自己 . n个封头 , 自己 . d模型 ). 转置 ( 1 , 2 ) #[batch_size,n_heads,len_k,d_model]批量_尺寸,n_heads,len_k,d_model] v_s(秒) = 自己 . W(V) ( V(V) ). 看法 ( 批处理大小 , - 1 , 自己 . n个封头 , 自己 . d模型 ). 转置 ( 1 , 2 ) #[批大小,n头,lenk,d模型]
attn_掩码 = attn_掩码 . 不挤压 ( 1 ). 重复 ( 1 , 自己 . _头 , 1 , 1 ) #attn_mask:[batch_size,n_heads,L_q,L_k]
上下文 = scaled_dot产品关注 ( q秒 , k秒 , v_s(秒) , attn_掩码 ) #[批次大小,n头,长度q,d模型] 上下文 = 上下文 . 转置 ( 1 , 2 ). 相邻的 (). 看法 ( 批处理大小 , - 1 , 自己 . 所有头部大小 ) #[批次大小,长度q,n头*d模型] 输出 = nn个 . 线性的 ( 自己 . 所有头部大小 , 自己 . 隐藏_大小 )( 上下文 )
返回 输出
三种注意机制
在编码器和解码器之间的注意层中,查询来自解码器,键值对来自编码器。 这使得解码器中的每个位置都能注意到编码器中的所有位置。 编码器中的注意层起到了自我注意的作用,在后者中的每个位置都会注意到前一层编码器中的所有位置。 解码器中的注意层也是自注意层。 为了防止向左的信息流动并保持自动累进特性( 新输出会消耗左边的先前输出,而不是相反 ),输入中与非法连接对应的所有值都被屏蔽为$-\infty$。
2.位置-方向前馈网络
班 位置前馈 ( nn个 . 模块 ):
定义 __初始化__ ( 自己 , d模型 , d_ff(关闭) , 辍学 = 0.1 ):
超级的 ( 位置前馈 , 自己 ). __初始化__ ()
自己 . 第1周 = nn个 . 线性的 ( d模型 , d_ff(关闭) )
自己 . w_2型 = nn个 . 线性的 ( d_ff(关闭) , d模型 )
自己 . 辍学 = nn个 . 辍学 ( 辍学 )
定义 向前地 ( 自己 , x个 ):
返回 自己 . w_2型 ( 自己 . 辍学 ( F类 . relu公司 ( 自己 . w_1 ( x个 ))))
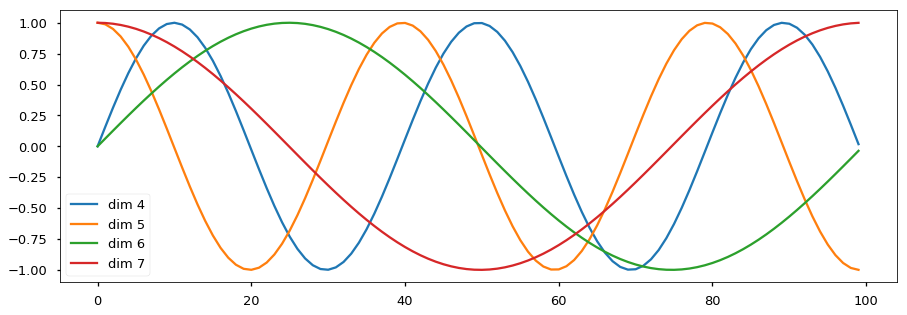
3.位置编码
{kind=link}
班 位置编码 ( nn个 . 模块 ):
定义 __初始化__ ( 自己 , 嵌入_大小 , 最大长度(_len) = 64 ):
超级的 ( 位置编码 , 自己 ). __初始化__ ()
#在日志空间中计算一次位置编码。 体育课 = 火炬 . 零点 ( 最大长度(_len) , 嵌入_大小 )
位置 = 火炬 . 阿兰奇 ( 0 , 最大长度(_len) ). 不挤压 ( 1 )
分词(_T) = 火炬 . 经验 ( 火炬 . 阿兰奇 ( 0 , 嵌入_大小 , 2 ) *
- ( 数学 . 日志 ( 10000 ) / 嵌入_大小 ))
体育课 [:, 0 :: 2 ] = 火炬 . 罪 ( 位置 * 分词(_T) )
体育课 [:, 1 :: 2 ] = 火炬 . 余弦 ( 位置 * 分词(_T) )
体育课 = 体育课 . 不挤压 ( 0 )
自己 . 寄存器缓冲区 ( “pe” , 体育课 )
定义 向前地 ( 自己 , x个 ):
返回 变量 ( 自己 . 体育课 [:, : x个 . 大小 ( 1 )], 要求_等级 = False(错误) )
关于自我注意的讨论
复杂性 是每层所需的总计算量。 顺序操作 是所需的最小顺序操作数。 这些操作不能并行化,因此很大程度上决定了层的实际复杂性。 最大路径长度 是网络中前进和后退信号必须穿越的路径长度。这些路径越短,越容易学习到长程相关性。

递归层
卷积层
自我关注层
限制性自我注意层
培训
培训时间 :完整型号需要3.5天才能在8个NVIDIA P100 GPU上进行训练。: 0 优化器 :亚当。 提高第一名的学习率 预热_步骤 训练步骤,然后减少。 类似 循环学习率 或倾斜三角形LR ULMFiT公司 正规化 : 剩余丢失:在剩余连接和层规范化$P_{drop}=0.1之前将丢失应用于输出层$ 嵌入丢弃:将丢弃应用于嵌入和位置编码$P_{drop}=0.1的总和$ 标签平滑 $\epsilon_{ls}的=0.1$。 这伤害了困惑,但提高了BLEU分数。
PyTorch实施
班 添加和规范 ( nn个 . 模块 ):
定义 __初始化__ ( 自己 , 隐藏_大小 , 辍学 = 0.1 ):
超级的 ( 添加和规范 , 自己 ). __初始化__ ()
自己 . 辍学 = nn个 . 辍学 ( 辍学 )
自己 . 规范 = nn个 . 图层规格 ( 隐藏大小(_S) )
定义 向前地 ( 自己 , x个 , 子层 ):
返回 自己 . 规范 ( x个 + 自己 . 辍学 ( 子层 ( x个 )))
班 嵌入 ( nn个 . 模块 ):
定义 __初始化__ ( 自己 , 嵌入_大小 , 声音_大小 , 最大长度(_len) , 使用位置编码 = False(错误) ):
超级的 ( 嵌入 , 自己 ). __初始化__ ()
自己 . 使用位置编码 = 使用位置编码
自己 . 标记嵌入(_E) = nn个 . 嵌入 ( 声音_大小 , 嵌入_大小 ) #标记嵌入 自己 . 规范 = nn个 . 图层规格 ( 嵌入_大小 )
如果 自己 . 使用位置编码 :
自己 . 位置_嵌入 = 位置编码 ( 嵌入_大小 , 最大长度(_len) )
其他的 :
自己 . 位置_嵌入 = nn个 . 嵌入 ( 最大长度(_len) , 嵌入_大小 ) #位置嵌入
定义 向前地 ( 自己 , 输入id ):
#(批次,序列) seq_len = 输入id . 大小 ( 1 )
销售时点情报系统 = 火炬 . 阿兰奇 ( seq_len , 数据类型 = 火炬 . 长的 )
销售时点情报系统 = 销售时点情报系统 . 不挤压 ( 0 ). 展开as ( 输入id ) #(seq_len,)->(批大小,seq_ren) 嵌入 = 自己 . 标记嵌入(_E) ( 输入id ) + 自己 . 位置_嵌入 ( 销售时点情报系统 )
返回 自己 . 规范 ( 嵌入 )
班 编码器层 ( nn个 . 模块 ):
定义 __初始化__ ( 自己 , n个封头 , 隐藏_大小 , 关闭(_d) , 辍学 = 0.1 ):
超级的 ( 编码器层 , 自己 ). __初始化__ ()
自己 . 自我关注 = 多头部注意 ( n个封头 , 隐藏_大小 )
自己 . 快速傅里叶变换网络 = 位置前馈 ( 隐藏_大小 , d_ff(关闭) )
自己 . 标准_1 = 添加和规范 ( 隐藏_大小 )
自己 . 标准2 = 添加和规范 ( 隐藏_大小 )
定义 向前地 ( 自己 , x个 , 面具 ):
att_输出 = 自己 . 标准_1 ( x个 , λ x个 : 自己 . 自我注意 ( x个 , x个 , x个 , 面具 ))
ffn输出 = 自己 . 标准2 ( att_输出 , 自己 . 快速傅里叶变换网络 )
返回 ffn输出
班 解码器层 ( nn个 . 模块 ):
定义 __初始化__ ( 自己 , n个封头 , 隐藏_大小 , d_ff(关闭) , 辍学 = 0.1 ):
超级的 ( 解码器层 , 自己 ). __初始化__ ()
自己 . 自我关注 = 多头部注意 ( n个封头 , 隐藏_大小 )
自己 . 编码器_解码器_注意 = 多头部注意 ( n个封头 , 隐藏_大小 )
自己 . 快速傅里叶变换网络 = 位置前馈 ( 隐藏_大小 , d_ff(关闭) )
自己 . 标准_1 = 添加和规范 ( 隐藏_大小 )
自己 . 标准2 = 添加和规范 ( 隐藏_大小 )
自己 . 标准值3 = 添加和规范 ( 隐藏大小(_S) )
定义 向前地 ( 自己 , x个 , 编码器_输出 , src掩码 , 目标任务(_M) ):
#x:输出嵌入 #encoder_outputs:最后一个编码器的输出 seq_len = x个 . 大小 ( 1 )
解码器掩码 = 自己 . 子序列掩码 ( seq_len ) & 目标任务(_M)
自拍 = 自己 . 标准_1 ( x个 , λ x个 : 自己 . 自我关注 ( x个 , x个 , x个 , 解码器_解码器_掩码 ))
编码器_解码器_附件 = 自己 . 标准2 ( 自拍 , λ x个 : 自己 . 编码器_解码器_注意 ( x个 , 编码器_输出 , 编码器_输出 , src掩码 ))
ffn输出 = 自己 . 标准值3 ( 编码器_解码器_附件 , 自己 . 快速傅里叶变换网络 )
返回 ffn输出
定义 后续任务 ( 自己 , 大小 ):
“掩盖后续位置。”
attn_形状 = ( 1 , 大小 , 大小 )
子序列掩码 = 净现值 . 三个 ( 净现值 . 个 ( attn_形状 ), k个 = 1 ). astype类型 ( “uint8” )
返回 火炬 . 来自numpy ( 子序列掩码 ) == 1
班 输出分类器 ( nn个 . 模块 ):
定义 __初始化__ ( 自己 , 隐藏_大小 , 人声 ):
超级的 ( 输出分类器 , 自己 ). __初始化__ ()
自己 . 稠密的 = nn个 . 线性的 ( 隐藏_大小 , 人声 )
定义 向前地 ( 自己 , x个 ):
返回 F类 . 日志软最大值 ( 自己 . 稠密的 ( x个 ), 昏暗的 =- 1 )
班 变压器 ( nn个 . 模块 ):
定义 __初始化__ ( 自己 , n层 , n个封头 , 隐藏大小(_S) , d_ff(关闭) , 最大长度(_len) , 输入_声音_大小 , 输出_声音_大小 , 嵌入_大小 , 辍学 = 0.1 ):
超级的 ( 变压器 , 自己 ). __初始化__ ()
自己 . 输入_嵌入 = 嵌入 ( 嵌入_大小 , 输入_声音_大小 , 最大长度(_len) , 使用位置编码 = False(错误) )
自己 . 输出_嵌入 = 嵌入 ( 嵌入_大小 , 输出_声音_大小 , 最大长度(_len) , 使用位置编码 = False(错误) )
自己 . 编码器堆栈 = nn个 . 模块列表 ([ 复制 . 深度复制 ( 编码器层 ( n个封头 , 隐藏_大小 , d_ff(关闭) )) 对于 _ 在里面 范围 ( n层 )])
自己 . 解码器堆栈 = nn个 . 模块列表 ([ 复制 . 深度复制 ( 解码器层 ( n个封头 , 隐藏_大小 , d_ff(关闭) )) 对于 _ 在里面 范围 ( n层 )])
自己 . 输出分类器 = 输出分类器 ( 隐藏_大小 , 输出_声音_大小 )
定义 向前地 ( 自己 , 输入ID , 输出ID , 输入掩码 ):
输入_嵌入 = 自己 . 输入_嵌入 ( 输入ID )
编码器_输出 = 输入_嵌入
对于 编码器 在里面 自己 . 编码器堆栈 :
编码器_输出 = 编码器 ( 编码器输出 , 输入_任务 )
输出_嵌入 = 自己 . 输出_嵌入 ( 输出ID )
解码器_输出 = 输出_嵌入
对于 解码器 在里面 自己 . 解码器堆栈 :
解码器_输出 = 解码器 ( 解码器_输出 , 编码器_输出 , 输入_任务 )
logits公司 = 自己 . 输出分类器 ( 解码器_输出 )
返回 logits公司