摘要 身高是一个典型的多基因性状,反映了多种未发现的遗传因素的综合影响。 我们对15821名个体身高的全基因组关联研究数据进行了荟萃分析,共有220万个SNP,并对超过10000名受试者的最强发现进行了随访。 十个新发现的和两个先前报道的基因座与身高变异密切相关( P(P) 值为4×10 -7 至8×10 -22 ). 这12个基因座总共约占种群高度变异的2%。 具有≤8个身高增加等位基因和≥16个身高增加等位基因的个体身高相差约3.5厘米。新发现的基因座,以及几个具有强烈暗示关联的额外基因座,包含了强大的生物学候选基因和意外基因,并突出了几个途径( let-7 靶点、染色质重塑蛋白和刺猬信号)是人类身高的重要调节器。 这些结果拓展了人类身高的生物调节以及这一经典复杂性状的遗传结构的图景。
全基因组关联研究的出现 1 通过从HapMap联盟获得的知识 2 以及全基因组基因分型技术和分析方法的最新进展,对人类遗传学领域产生了巨大影响。 最近的全基因组研究已经鉴定出与复杂人类疾病相关的常见遗传变异 三 基因组关联(GWA)研究也已成功用于识别与数量性状相关的遗传变异,如脂质水平 4 和体重指数 5 , 6 这些发现,通过识别以前未知且往往是意料之外的基因,开启了人类复杂特征和常见疾病研究的激动人心的时期。
最近发现的大多数变异体的特征小效应大小对多基因疾病和性状的研究提出了挑战,因为通常需要大样本大小来识别相关的常见变异体。 目前尚不清楚进一步增加样本量是否会加快发现的步伐,以及在多大程度上具有适度影响的多个基因座会揭示以前未知的生物途径。 为了回答这些重要问题,我们将成人身高作为模型表型。 成人身高是一个具有高遗传力的复杂性状( 小时 2 个体内~0.8-0.9) 7 , 8 此外,高度测量准确,在很大一部分寿命内相对稳定 9 数据可供大量个人使用。 因此,对身高的研究是剖析人类高度多基因性状结构的理想机会。 此外,因为身高与几种常见的人类疾病(例如癌症)有关 10 ,与身高相关的基因座可能具有多效性,影响其他疾病的风险或严重程度 11 .
利用GWA研究的数据,我们和同事确定了与成人身高变异密切相关的前两个常见变异: HMGA2型 基因 12 和苏格兰民族党 GDF5-UQCC公司 轨迹 11 这两种多态性解释的身高总体变化很小(占总方差的0.3-0.7%),这表明影响身高的大多数常见变异影响较小。 观察到的适度影响也突出了使用大型数据集来识别“真实”身高变异的重要性: HMGA2型 SNP最初是在DGI和Wellcome Trust Case Control Consortium UKT2D数据集的联合分析中发现的( n个 =4921人),以及 GDF5-UQCC公司 该发现最初是在SardiNIA和FUSION结果分析中确定的( n个 =6669人)。 由于这些发现可能属于与身高相关的常见变异的效应大小上限范围,我们考虑了可能需要逐步扩大样本大小来确定其他身高位点的可能性。
在这些早期成功的鼓舞下,我们对六个GWA数据集进行了更大的荟萃分析,包括约220万SNP的15821个个体的身高关联结果,以找到与身高相关的其他位点。 在这里,我们报告了十个新发现的常见SNP和高度变化之间的关联的识别和验证(每个都有 P(P) < 5 × 10 -7 )以及另外四个具有强烈暗示证据的关联(每个关联都有 P(P) < 5 × 10 -6 ). 我们还确认了之前报告的两种关联( HMGA2型 和 GDF5-UQCC公司 ). 新发现的与身高相关的基因座牵涉到几个生物途径或基因集,包括 let-7 微RNA、染色质重塑蛋白和刺猬信号——是人类身高的重要调节器。 最后,我们检验了与性别的相互作用,检验了基因座之间的上位性相互作用,并估计了每个基因座单独或组合的解释力。 这些结果拓宽了我们对人类生长的生物调控的理解,并为进一步对这一经典复杂性状进行遗传分析奠定了基础。
结果 与身高相关基因座的鉴定 我们对GWA身高数据进行了荟萃分析,其中包括来自六项研究的15821名个体:两个2型糖尿病病例对照数据集(DGI 4 , n个 = 2,978; 融合 13 , n个 =2371),两个嵌套癌症病例对照数据集(NHS 14 , n个 = 2,286; PLCO公司 15 , n个 =2244)和两个基于人群的队列数据集(KORA 16 , n个 = 1,644; 萨迪尼亚 17 , n个 = 4,305)( 补充表1 在线)。 所有参与者都有欧洲血统。 由于这些研究中的全基因组基因分型是在不同的平台上进行的(Affymetrix 500K用于DGI、KORA和SardiNIA,Illumina 317K用于FUSION,Illum 550K用于NHS和PLCO),我们使用程序MACH(Y。 Li和G.R.A.,未发表的数据),从而生成2260683个常染色体SNP的兼容数据集。 在每项研究中,在加性遗传模型下测试成人身高与这些SNP的相关性,并使用加权的meta分析将关联结果结合起来 Z轴 -评分法(方法)。 然而,每个单独GWA研究的测试统计分布与零假设下的预期一致( 图1 ),meta分析结果的分位数-分位数图清楚地显示,低 P(P) 分布右尾的值,尽管总体系统偏差证据极少( λ GC公司 = 1.089; 图2a ). 这一结果表明,在综合分析中揭示了与身高变化的真实关联,而这些关联在个体研究中无法从背景中辨别出来。 事实上,这些身高荟萃分析结果中的第二和第三大关联信号- HMGA2型 1042725卢比( P(P) = 2.6 × 10 -11 )和 GDF5-UQCC公司 6060369卢比( P(P) = 1.9 × 10 -10 )-最近的研究表明,在没有被选为身材高大或矮小的人中,身高与身高有着密切的关系 11 , 12 这些发现验证了我们的荟萃分析方法,并表明与身高相关的其他基因座在我们的结果顶部或接近顶部。
图1。
荟萃分析的六个全基因组关联扫描中每一个约220万SNP的分位数-分位数图。 ( 一 )DGI公司( n个 = 2,978). ( b条 )融合( n个 = 2,371). ( c(c) )科拉( n个 = 1,644). ( d日 )英国国家医疗服务体系( n个 = 2,286). ( e(电子) )PLCO公司( n个 = 2,244). ( (f) )撒丁岛( n个 = 4,305). 每个黑色圆圈代表一个观察到的统计数据(定义为-log 10 ( P(P) ))与相应的预期统计数据进行比较。 灰色线对应于零分布。
图2。
分位数-分位数图支持与身高相关的其他位点的存在。 ( 一 )六次GWA扫描荟萃分析中2260683个SNP的绘图( n个 = 15,821). 每个黑色三角形表示观察到的统计数据(定义为-log 10 ( P(P) ))与相应的预期统计数据进行比较。 删除与12个高度信号相关的标记后,黑色方块对应测试统计数据的分布 P(P) < 5 ×10 -7 中描述的 表1 。灰线对应于零分布。 ( b条 )Weedon的关联结果 等 . 18 提供独立证据,证明我们荟萃分析中的前10000个SNP超过了零预期(灰色线)。 我们从荟萃分析中选择了前10000个SNP(黑色三角形)和后10000个SNPs(黑色正方形),删除了标记已知高度位点的SNPs P(P) 来自Weedon的值 等。 我们展示了单尾 P(P) 值,因为如果需要,我们会对效果的方向进行校正。 通货膨胀因素异常高,因为分析仅限于前10000个SNP,这些SNP可能会因真正与高度变化相关的SNP而丰富。
将与身高相关的真正变异与其他可能达到较低水平的SNP区分开来 P(P) 我们建立了一个两阶段随访策略,以收集直接的基因型数据,并根据插补基因型进行关联( 补充图1 在线)。 在第一阶段,我们选择了78个代表顶级关联信号的SNP(按 P(P) 值,并考虑连锁不平衡(LD)以最小化冗余); 然后我们在一组欧美人中对这78个SNP进行了基因分型( n个 =2189)从正常身高分布的近端确定(短,5-10百分位;高,90-95百分位)( 补充表2 在线)。 此面板以前曾被用来非常有力地复制 HMGA2型 rs1042725协会 12 为了减少进入第二阶段的假阳性数量,并保持与身高的真正关联,我们选择了29个SNP进行进一步研究,这些SNP在欧美小组中的优势比与荟萃分析中观察到的效果方向一致(方法)。 我们在四个大型验证(复制)小组中对这些SNP进行了基因分型:所有29个SNP均在基于人群的FINRISK97队列中进行基因分型( n个 =7803),并且在基于人群的KORA S4中进行了基因分型( n个 =4130)和购买力平价( n个 =3402)队列和2型糖尿病病例对照FUSION 2期小组( n个 = 2,466) ( 补充表3-6 在线)。 由于后勤和技术问题,并不是所有29个SNP都能在所有四个DNA面板中进行基因分型,因此导致我们后续战略中的一些SNP功率下降。 然而,这些共同努力导致了12个SNP的识别 P(P) < 5 × 10 -7 (使用来自荟萃分析和验证小组的证据,除了欧美小组,因为其具体的确定性),显著性水平强烈暗示了真实的关联( 表1 ; 中给出了详细的关联结果和LD图 补充表7 和 补充图2 分别在线) 三 三个位点中 P(P) 值在5×10之间 -7 和5×10 -8 ,两份在随附的手稿中得到确认 18 ( SH3GL3-ADAMTSL3 和 川东北6 )其中一人在欧美身高短跑(USHT)小组中有强有力的独立证据( CHCHD7-RDHE2,第页 = 9 × 10 -6 ; 表1 ). 这表明带有 P(P) 这个范围内的值至少对于与高度有有效关联的位点是丰富的。 此外,四个基因座显示了总体暗示证据(组合 P(P) < 5 × 10 -6 )与成人身高相关( 表1 ). 尽管SNP rs2730245位于 WDR60型 轨迹有一个组合 P(P) = 3 × 10 -7 ,我们选择将该标记纳入我们的暗示关联列表,因为与 表1 ,这个信号有一个后续 P(P) > 0.05.
表1。 随访组中29个SNP基因型的关联结果摘要。
染色体(位置) SNP公司 MAF(等位基因) 一 荟萃分析 P(P) β(s.e.m.) b条 荟萃分析异质性 我 2 c(c) (%) 后续行动 P(P) β(s.e.m.) b条 随访异质性 我 2 c(c) (%) 组合 P(P) β(s.e.m.) d日 美国高温试验 P(P) OR(95%置信区间) e(电子) 附近的基因 (f)
验证的关联(组合 P(P) < 5 × 10 -7 )
3 (142588268) 724016卢比 0.48(G) 5.0 × 10 -12 0.461 (0.070) 0 2.5 × 10 -11 0.307 (0.051)
71
8.3 × 10 -22 0.365 (0.038) 7.8 × 10 -8 1.4 (1.2-1.6)
ZBTB38型
12 (64644614) 1042725卢比 0.49(吨) 2.6 × 10 -11 -0.403 (0.070) 8 1.7 × 10 -10 -0.493 (0.077) 0 2.7 × 10 -20 -0.484 (0.051) 4.2 × 10 -6 0.8 (0.7-0.9)
HMGA2型
6 (142745570) 4896582卢比 0.27(A) 3.2 × 10 -8 -0.397 (0.077) 0 6.3 × 10 -12 -0.365 (0.058) 24 2.4 × 10 -18 -0.378 (0.051) 2.2 × 10 -5 0.8 (0.7-0.9)
126加仑
6 (26341366) 10946808卢比 0.28(G) 3.3 × 10 -8 -0.448 (0.083) 40 1.9 × 10 -10 -0.314 (0.058)
63
3.8 × 10 -17 -0.358 (0.045) 3.4 × 10 -8 0.7 (0.7-0.8)
HIST1H1D公司
20 (33370575) rs6060369型 0.36(C) 1.9 × 10 -10 0.454 (0.077) 0 1.3 × 10 -7 0.410 (0.077) 0 1.4 × 10 -16 0.435 (0.051) 0.012 1.2 (1.0-1.3)
GDF5-uccc公司
4 (146007626) rs1492820美元 0.48(G) 3.6 × 10 -8 -0.435 (0.077) 0 3.9 × 10 -5 -0.218 (0.051) 0 1.2 × 10 -11 -0.288 (0.038) 0.002 0.8 (0.7-0.9)
HHIP公司
14 (91529711) 8007661卢比 0.30(吨) 8.9 × 10 -8 -0.486 (0.090) 0 0.0015 -0.326 (0.102) 不适用。 5.5 × 10 -10 -0.416 (0.064) 0.64 1.0 (0.9-1.1)
行程11-ATXN3
6 (105514355) 314277卢比 0.13(安) 5.9 × 10 -9 0.608 (0.109) 0 0.035 0.230 (0.102) 0 1.1 × 10 -8 0.410 (0.077) 0.26 1.1 (0.9-1.3)
LIN28B系列
19 (2121954) 12986413卢比 0.45(吨) 2.0 × 10 -5 0.333 (0.077) 23 3.7 × 10 -4 0.275 (0.077) 60 2.9 × 10 -8 0.307 (0.051) 0.20 1.1 (1.0-1.2)
DOT1L公司
15 (82077496) 2562784卢比 0.17(克) 2.9 × 10 -5 0.307 (0.083) 三 5.5 × 10 -4 0.397 (0.115) 不适用。 6.4 × 10 -8 0.339 (0.064) 0.28 1.1 (1.0-1.2)
SH3GL3-ADAMTSL3
8 (57318152) 9650315卢比 0.13(吨) 9.6 × 10 -6 -0.474 (0.102) 46 0.010 -0.352 (0.134) 26 3.8 × 10 -7 -0.429 (0.083) 9.0 × 10 -6 0.7 (0.6-0.8)
CHCHD7-RDHE2
7 (91901556) 2040494卢比 0.50(C) 4.8 × 10 -5 -0.288 (0.077) 29 0.0020 -0.237 (0.077) 0 3.8 × 10 -7 -0.262 (0.051) 0.18 0.9 (0.8-1.0)
川东北6
暗示联想(5×10 -6 >合并 P(P) > 5 × 10 -7 )
7 (158224265) 2730245卢比 0.33(克) 2.6 × 10 -7 0.410 (0.083) 4 0.082 0.179 (0.102) 23 3.0 × 10 -7 0.320 (0.064) 0.99 1.0 (0.9-1.1)
WDR60型
9 (130493638) 7466269卢比 0.33(克) 1.2 × 10 -5 -0.339 (0.077) 0 0.011 -0.198 (0.077) 0 7.5 × 10 -7 -0.269 (0.058) 0.48 1.0 (0.9-1.1)
FUBP3型
9 (116214350) 7869550卢比 0.24(G) 9.5 × 10 -6 -0.429 (0.090) 0 0.18 -0.218 (0.090) 2 1.2 × 10 -6 -0.326 (0.064) 0.58 1.0 (0.8-1.1)
PAPPA公司
17 (51785154) 12449568卢比 0.47(C) 4.7 × 10 -6 0.333 (0.077) 19 0.047 0.153 (0.077) 35 2.4 × 10 -6 0.250 (0.051) 0.49 1.0 (0.9-1.2)
ANKFN1
其他(合并 P(P) > 1×10 -5 )
16 (615681) 763014卢比 0.43(C) 2.5 × 10 -5 0.307 (0.077) 41 0.033 0.166 (0.077) 59 5.1 × 10 -6 0.237 (0.058) 0.05 1.1 (1.0-1.3)
RAB40C型
14 (36069800) rs17104630 0.04(G) 1.4 × 10 -5 -0.621 (0.141) 0 0.062 -0.250 (0.128) 2 8.1 × 10 -6 -0.422 (0.096) 0.02 0.8 (0.6-1.0)
NKX2-1型
8 (41596148) 11786297卢比 0.05(克) 4.9 × 10 -5 0.544 (0.128) 20 0.10 0.320 (0.186) 52 3.9 × 10 -5 0.474 (0.102) 0.39 1.1 (0.9-1.4)
AGPAT6公司
14 (91477446) 3783937卢比 0.28(吨) 5.5 × 10 -5 -0.326 (0.083) 35 0.15 -0.128 (0.090) 0 8.2 × 10 -5 -0.237 (0.064) 0.02 0.9 (0.8-1.0)
FBLN5型
16 (2225358) 26840卢比 0.43(吨) 1.6 × 10 -4 0.326 (0.077) 0 0.29 -0.128 (0.186) 46 1.5 × 10 -4 0.269 (0.064) 0.02 1.2 (1.0-1.3)
E4F1系列
5 (4573856) 1450822卢比 0.48(A) 4.1 × 10 -4 0.282 (0.077) 10 0.43 0.141 (0.186) 6 3.3 × 10 -4 0.262 (0.070) 0.21 1.1 (1.0-1.2)
8 (129118629) 13249999卢比 0.05(吨) 2.8 × 10 -4 -0.768 (0.198) 18 0.30 -0.205 (0.198) 不适用。 3.6 × 10 -4 -0.480 (0.141) 0.59 0.9 (0.8-1.2)
20 (5034939) 6116651卢比 0.10(吨) 4.8 × 10 -5 -0.531 (0.122) 36 0.46 -0.122 (0.147) 0 4.7 × 10 -4 -0.371 (0.096) 0.004 0.8 (0.6-0.9)
C20或30
4 (4394990) 2916448卢比 0.13(C) 3.9 × 10 -7 -0.531 (0.102) 0 0.67 0.070 (0.160) 23 5.5 × 10 -4 -0.358 (0.090) 0.25 0.9 (0.8-1.1)
利亚尔
4 (82511461) 1662845卢比 0.35(吨) 5.7 × 10 -5 0.326 (0.083) 0 0.60 0.038 (0.077) 77 9.1 × 10 -4 0.179 (0.058) 8.5 × 10 -6 1.3 (1.2-1.5)
PRKG2系列
15 (77391837) 11858942卢比 0.37(克) 8.2 × 10 -6 0.339 (0.077) 0 0.86 -0.013 (0.083) 0 0.0015 0.173 (0.058) 0.54 1.0 (0.9-1.2)
TMED3公司
7 (50439131) 12540874卢比 0.29(G) 7.3 × 10 -5 -0.288 (0.077) 0 0.91 0.006 (0.083) 0 0.0027 -0.160 (0.058) 0.98 1.0 (0.9-1.1)
GRB10级
18 (48613000) 12958987卢比 0.23(吨) 8.8 × 10 -6 -0.339 (0.083) 0 0.16 0.154 (0.109) 不适用。 0.0045 -0.160 (0.064) 0.69 1.0 (0.9-1.1)
DCC公司
与高度相关的信号特征 人口分层可能是高度和其他人类表型关联研究的一个强烈混淆因素 19 我们采取了几个步骤,以确保我们研究中确认的身高相关信号不是由于人口分层。 使用主成分方法对NHS和PLCO数据集中的关联检验进行了剩余人口结构校正 20 ; 对DGI不相关成分的类似分析没有改变 表1 ( 补充表8 在线)。 对芬兰境内地理来源分层的FINRISK97复制小组的分析没有改变与身高相关的强度 表1 ( 补充表9 在线)。 最后,使用已知的279个变异与欧洲衍生人群的主要祖先轴相关 21 ,我们计算了一个小的通货膨胀系数( λ )我们的身高荟萃分析结果为1.09,表明即使通过为此目的选择的标记也没有显示出实质性分层。 综上所述,这些结果表明,在我们的研究中发现的与身高的遗传关联不太可能是由于人口分层。
对于识别出的16个SNP P(P) < 5 ×10 -6 ( 表1 ),在FINRISK97小组中,没有证据表明偏离了加性遗传模型( P(P) >加性与无约束两自由度检验的似然比检验为0.05),男女之间的影响大小没有显著差异( P(P) >0.05),并且位点之间没有强烈的上位性相互作用(在SNP rs1492820和SNP rs10946808之间观察到最显著的相互作用( P(P) =0.001),在对120个相互作用的成对测试进行校正后,该值不显著)。
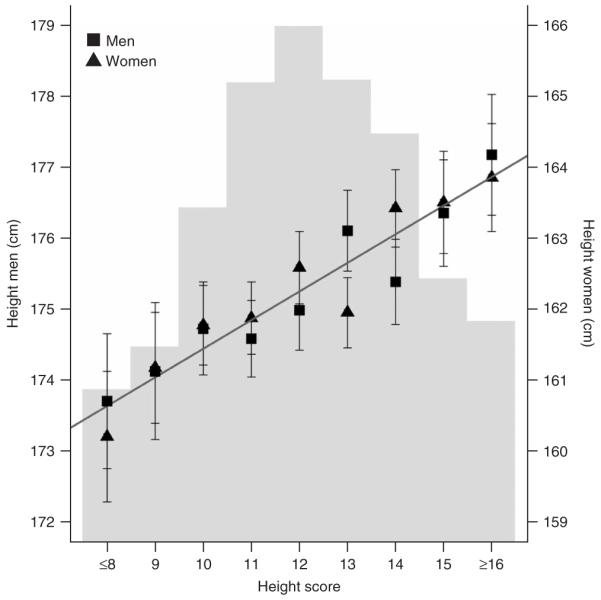
与身高相关的基因座的解释力 这里报告的每个常见身高SNP解释了身高中残留表型变异的一小部分(0.1-0.8%; 补充表7 ). 当综合分析时,12个SNP与 P(P) < 5 × 10 -7 在FINRISK97面板中,只有2.0%的高度变化是由基因变异引起的,远低于估计的80-90%。 为了评估这组初始变异体的累积预测值,我们通过计算FINRISK97面板中具有这12个SNP的完整基因型的每个参与者的身高增加等位基因数(12个SNPs;身高得分0-24),创建了一个“身高得分”( n个 = 7,566). 平均而言,具有≤8个“高”等位基因的男性和女性(占FINRISK97的4.7%)分别比具有≥16个“高”等位基因的男性和女性(占FINRISK97的7.1%)短3.5厘米和3.6厘米( 图3 ). 每个T等位基因的个体效应大小为0.3 cm 川东北6 rs2040494到0.5厘米每C等位基因 HMGA2型 1042725卢比( 表1 ).
图3。
综合效应分析。 对于FINRISK97小组中的每个参与者,在12个SNP中具有完整的基因型 P(P) < 5 × 10 -7 在里面 表1 ( n个 =7566),我们计算了身高增加等位基因的数量,以得出身高分数。 将≤8或≥16个“高”等位基因的个体分组。 对于每个身高评分组,分别绘制男性和女性的平均±95%置信区间。 男性轴在左侧,女性轴在右侧(比例相同)。 深灰色的回归线表明,对于男性和女性来说,每增加一个“高”等位基因,身高就会增加0.4厘米。背景中的浅灰色直方图表示每个身高分数组中个体的相对分数(身高分数≤8:4.7%;身高分数9:6.2%;身高分数10:11.1%;身高分数11:15.5%; 身高评分12:17.5%; 身高得分13:15.6%; 身高得分14:13.7%; 身高得分15:8.6%; 身高得分≥16:7.1%)。
讨论 这里报道的一些SNP属于或接近强候选身高基因,例如最近描述的与 HMGA2型 (参考。 12 )和 GDF5-UQCC公司 11 而其他人则发现了以前未知的基因座。 总之,这些联系突出了在调节人类生长方面非常重要的生物途径。
刺猬相互作用蛋白( HHIP公司 ; rs1492820)是Hedgehog信号传导的转录靶点和拮抗剂; 它与三种哺乳动物刺猬蛋白具有高亲和力 22 .小鼠同源物, 髋关节 表达于软骨膜,包括印度刺猬侧翼的区域( Ihh公司 )在阑尾和轴骨中的表达。 异位过度表达 髋关节 小鼠软骨会导致严重的骨骼缺陷,包括短肢侏儒症,这一特征让人联想到 小时 无鼠标 22 , 23 .
我们在与染色质结构相关的基因中或其附近鉴定了几个相关SNP。 除了 HMGA2型 编码染色质结合蛋白,我们发现与第6染色体组蛋白簇中的SNP(rs10946808)相关,与组蛋白甲基转移酶中的SNPs(rs12986413)相关 DOT1L公司 甲基-DNA结合转录抑制因子基因内含子中的基因和SNP(rs724016) ZBTB38型 目前尚不清楚这些基因座的遗传变异是如何调节身高的,但染色质结构的调节与身高之间存在联系的先例:以极高身高为特征的Sotos综合征(MIM117550)是由组蛋白甲基转移酶基因的突变和缺失引起的 NSD1号机组 。测试 HMGA2型 ,6号染色体组蛋白簇, DOT1L公司 和 ZBTB38型 改变Sotos综合征的临床结局,或这些基因是否发生严重突变,尤其是 DOT1L公司 ,可能导致Sotos综合征样表型。
变异rs1042725与成人和儿童身高密切相关 12 ,位于的3′UTR HMGA2型 值得注意的部分原因是 HMGA2型 是经验证的人类基因数量最多的 第7列 microRNA结合位点 24 , 25 事实上,rs1042725距离 let-7 位点,提示SNP通过改变microRNA结合从而改变 HMGA2型 。当我们检查我们的12个身高基因座列表时,我们有点惊讶地发现之前描述的另外三个目标 let-7 :细胞周期调节器 川东北6 (参考。 26 )组蛋白甲基转移酶 DOT1L公司 27 和基因 LIN28B系列 28 . PAPPA公司 ,一个结合了 P(P) = 1.2 × 10 -6 在我们的研究中,还包含一个预测 let-7 结合位点 27 因此,影响身高的基因似乎在验证或潜在方面得到了丰富 let-7 目标:16个(31%)已证实或提示的与身高相关的基因座中有5个 let-7 结合位点,与人类基因组中2%的基因相比(Fisher精确测试 P(P) = 3 × 10 -5 ). 因为microRNAs可以共同调节参与同一生物过程的基因,所以测试其他靶点 let-7 ,或 出租- 7本身就是成人身高的调节器。
在我们对GWA研究和复制队列的荟萃分析中,变异体中也有值得注意的候选基因,这些变异体在与身高相关方面表现出强烈但尚未达到决定性的显著水平。 SNP上游28 kb PRKG2系列 编码cGMP-依赖性蛋白激酶II(cGKII)的(rs1662845),在我们对GWA扫描的荟萃分析中显示出与身高密切相关( P(P) = 5.7 × 10 -5 )和欧美高度面板中的方向相同( P(P) = 8.5 × 10 -6 )和FUSION第2阶段样品( P(P) =0.001),但不在FINRISK97中( P(P) =0.93,相反方向)和PPP( P(P) =0.16,相反方向)面板。 a该基因座是高度变异中非常有力的候选基因。 第一, 项目2 -/- 小鼠出现侏儒症,这是由生长板软骨内骨化严重缺陷引起的 29 第二,自然产生的Komeda微型大鼠石川突变体具有一般的纵向生长迟缓,是由于编码cGKII的大鼠基因缺失所致 30 因此,在啮齿动物中,cGKII显然在骨骼生长中起作用,在软骨细胞增殖和分化之间起分子开关的作用。 我们预测,更大规模的复制研究将证明 PRKG2系列 该基因座确实对人类的身高变异有贡献,但似乎也可能存在研究间的异质性。
一些新发现的与身高相关的基因座位于与身高关系不太明显的基因附近,包括G蛋白偶联受体基因 126加仑 ,一个包含甲状腺激素受体相互作用物的位点 行程11 和ataxin ATXN3型 基因,一个带有亨廷顿相互作用基因的位点 SH3GL3型 糖蛋白金属蛋白酶基因 适配器3 (后者在结肠癌中经常发生突变 31 ),一个带有基因的位点 第7页 ,经常与 广场1 涎腺腺瘤中的癌基因 32 和表皮视网膜脱氢酶2基因 RDHE2号机组 .因为LD( 补充图2 ),这些位点上的因果等位基因可能不位于这些基因中; 可能需要在较大的队列或不同祖先的群体中进行精细的定位,以精确定位相关的基因和功能变体。 或者,这些基因本身可能会影响身高,需要进一步研究来阐明相关的途径和机制。
我们注意到随附的Weedon的手稿 等 . 18 确定我们研究中报告的几个位点与身高的关系( ZBTB38、HMGA2、GDF5-UQCC、HHIP、SH3GL3-ADAMTSL3、CDK6 )和我们一样,报告了一个在 FUBP3型 轨迹( P(P) = 7.5 × 10 -7 在我们的研究中; P(P) = 2.0 × 10 -5 在Weedon 等。 ). FUBP3型 ,一个与 c-myc公司 因此,调节可能代表一个与身高相关的额外位点。
我们验证的与高度相关的变量没有足够强的影响来产生可检测的联动信号 33 .我们的三个基因座位于先前报道的高度连锁峰下 8 : ZBTB38型 lod评分2.03; 行程11-ATXN3 lod评分2.01; 和 川东北6 ,lod得分2.26。 然而,由于17.6%的基因组与lod评分>2的高度连锁峰重叠,因此这种共定位的数量并不比偶然预期的多(观察到的3个,而预期的2.12个)。 一些基因可能同时含有影响身高的常见和罕见变异,因此在具有真正遗传基础的相关和连锁位点之间可能会出现一些重叠。 此外,连锁区域可能指示稀有变异或其他类型的遗传变异的位置,而我们当前的关联方法没有很好地捕捉到这些变异。
正如预期的那样,由于众所周知的“赢家诅咒”现象,GWA荟萃分析中估计的效应大小通常大于复制样本中观察到的效应大小 34 也许不太受重视的是,胜利者诅咒效应的大小取决于效应大小的潜在分布:小效应变量的数量越多, 更有可能的是,这些变体中的一个或多个将接近全基因组意义,即使是在一项没有很好检测到这些非常轻微影响的研究中 35 。这样的变体将很难令人信服地进行复制,除非使用非常大的复制队列。 因此,即使是我们未能复制的一些初始关联最终也可能得到验证。
考虑到与身高相关的验证变量观察到的适度影响大小( 表1 ; 平均值=0.4cm每增加一个等位基因),单个GWA研究的分位数-分位数图与零期望基本上无法区分,这并不奇怪( 图1 ). 事实上,我们计算出,一项对3000名无关个体的研究有1%的能力检测到一种变异(次要等位基因频率10%),这种变异在统计阈值为 P(P) = 1 × 10 -5 相比之下,一项针对16000人的研究有72%的能力识别相同的变体(事实上,当使用元分析方法组合结果时,能力会略有损失)。 我们通过将个别研究与几乎为零的研究相结合来发现有效关联 P(P) -值分布强调了使用大型数据集查找影响较小的常见变量的重要性。 当我们从荟萃分析结果中删除12个经验证的身高变异(以及附近的相关SNP)时 P(P) 值仍超过空期望值( 图2a ,填充方块)。 此外,10000个SNP P(P) 在一项独立的meta分析中,这些数值也显示了过多的相关性证据 18 ,即使排除了所有已知与身高相关的基因座( 图2b ). 这些结果表明,还有其他与常见等位基因的关联尚待发现,但我们的荟萃分析没有足够的力量来确定这些关联,因为影响大小很小。
我们的结果有几个含义。 首先,他们概述了以前未知的多个基因和生物途径在调节身高方面的作用,证实了无偏见的遗传方法产生新生物学见解的能力。 这些基因的鉴定不仅扩大了我们对人类生长的认识,而且还促进了这些基因成为尚未解释的严重身高或身材矮小综合征的候选基因。 其次,这些发现令人信服地证实了身高的多基因性,这是一个典型的复杂性状,并表明,至少对于这一性状,越来越多的GWA研究可以发现越来越多的相关基因座。 第三,每个变异体对表型变异的贡献很小(尽管确定此处报告的每个位点的总贡献需要更全面的重新测序和基因分型); 因此,数百个共同变异影响复杂性状,如身高和/或其他遗传贡献者(例如,基因-基因或基因-环境相互作用、具有较大影响的罕见变异或结构多态性等未捕获的基因组特征),其中之一将发挥重要作用。 特别是,因为这里分析的GWA研究中使用的质量控制标准会删除受拷贝数多态性影响的SNP,所以我们无法得出任何关于这些变异对成人身高的作用的结论。 随着适用于大型队列的新平台和改进的分析工具的开发,很可能很快就会阐明常见结构变体在人类复杂特征(如成人身高)中的作用。 最后,如果身高确实是其他复杂性状的一个很好的模型,这些结果表明,GWA研究的大型荟萃分析不仅可以深入了解人类的生长,还可以深入了解常见疾病的潜在生物学机制。
方法 全基因组关联研究样本的描述 糖尿病遗传学研究所(DGI)分析的个体在其他地方也有描述 4 总共有1464例2型糖尿病患者,1467例来自芬兰和瑞典的欧洲血统对照。 芬兰-美国非胰岛素依赖型糖尿病遗传学(FUSION)GWA研究的调查包括1161例芬兰2型糖尿病(T2D)病例、1174例正常糖耐量(NGT)对照组和122对病例对照组的后代 13 根据芬兰境内的年龄、性别和出生省份,病例和对照组进行了匹配,如前所述。 KORA全基因组关联研究样本是从KORA S3调查中招募的,该调查是来自德国南部奥格斯堡地区普通人群的基于人群的样本。 1644名研究参与者持有德国护照,并且来自欧洲 16 护士健康研究(NHS)GWA扫描包括2286名欧洲血统注册护士的DNA:1145名绝经后浸润性乳腺癌患者和1142名配对对照 14 前列腺癌、肺癌、结直肠癌和卵巢癌筛查试验(PLCO)GWA扫描包括1172例欧洲血统的非西班牙裔前列腺癌病例和1105例匹配的对照 15 。SardiNIA GWAS对参与意大利撒丁岛Ogliastra地区aging-related数量性状纵向研究的4305名相关个体进行了检测 17 。有关更多详细信息,请参阅 补充方法 在线。
后续样品说明 欧裔美国人( n个 =2189)样本是一项身高-身高研究,受试者在成人身高中的排名为5-10百分位(矮女性,152-155厘米;矮男性,164-168厘米),在成人身高的90-95百分位中的排名(高女性,170-175厘米;高男性,185-191厘米) 19 所有人都是自我描述的“白人”或“欧洲血统”。 所有受试者都出生在美国,他们的祖父母都出生在欧洲或美国。 使用遗传功率计算器 36 假设在整个表型分布中存在纯加性遗传效应,我们计算出,欧美高短板的研究设计提供了33.0、79.0和98.6%的检测能力,以检测分别解释≥0.1、0.25和0.5%表型高度变异的变异(在 α -阈值0.01),与meta分析中观察到的效果相比,在同一方向上满足我们对任何比值比的不太严格的筛选标准的能力更大。 FINRISK 1997是芬兰国家公共卫生研究所每五年进行一次的基于人群的风险因素调查之一 37 经国家公共卫生研究所伦理委员会批准(第38/96号决定)。 样本来自五个地理区域的国家人口登记册。 FUSION第2阶段研究包括一系列病例和对照,以考虑芬兰的年龄、性别和出生省份 13 KORA S4样本来自德国南部奥格斯堡,与KORA S3种群不重叠。 Botnia研究中的糖尿病患病率、预测和预防(PPP)是一项始于2004年的基于人群的研究,旨在研究2型糖尿病的流行病学。 有关更多详细信息,请参阅 补充方法 这些研究得到了相应的道德审查委员会的批准。
基因型插补 由于GWA扫描使用了不同的基因分型平台,我们在每次扫描中使用MACH中实现的隐马尔可夫模型估算了所有多态性HapMap SNPs的基因型(Y.Li和G.R.a.,未发表的数据)。 这种方法使我们能够在所有扫描中评估相同SNP的相关性。 插补方法将每个样本的基因型数据与HapMap CEU样本(2006年7月阶段性单倍型释放)相结合,然后概率推断未观察到的基因型。 该推断依赖于在HapMap CEU参考小组中研究样本和个体之间共享的单倍型延伸的识别。 对于每个个体的每个SNP,插补结果总结为“等位基因剂量”,定义为该SNP处次要等位基因的预期拷贝数(介于0.0和2.0之间的分数)。 如前所述, 第页 2 在每个输入的基因型和真正的潜在基因型之间进行估计,并作为质量控制指标(rsqhat in 补充表7 ). 我们选择了一个估计 第页 2 >0.3作为标记和丢弃低质量插补SNP的阈值(参考。 13 以及Y.Li和G.R.A.,未公布数据)。
关联分析 对于所有研究,除了欧美身高小组,我们将身高转换为 Z轴 评分,适当时考虑性别、年龄和疾病状态。 对于DGI、KORA S3、NHS、PLCO、FINRISK97、KORA S4和PPP队列,我们使用PLINK中实现的回归框架进行了关联测试 38 对于基因型标记,以及在MACH2QTL(Y.Li和G.R.A.,未发表的数据)中,其中考虑了输入SNP的剂量信息(0.0-2.0)。 对于DGI,我们使用基因组控制方法来纠正相关个体的存在。 在FUSION和SardiNIA数据集中,使用一种允许相关性的方法对基因型SNP和插补SNP进行关联测试,在方差分量模型的背景下估计回归系数 39 使用Cochran-Mantel-Haenszel(CMH)检验对欧美高短板进行统计分析 38 按祖父母的欧洲地区划分。
荟萃分析 本手稿中的关联结果考虑了每个输入基因型的后验概率。 为了合并结果,我们使用加权 Z轴 -评分方法:
z(z) w个 是加权的 Z轴 荟萃分析双尾的得分 P(P) 计算值, z(z) 我 是 Z轴 研究得分 我 (计算为相应单尾的累积正态概率密度 P(P) 值,如果需要,通过减去 P(P) 当效果方向反转时,值从1开始), N个 我 是研究的样本量 我 和 N个 总数 是总样本量。 总的来说,我们综合了15821名个体中2260683个常染色体SNP的关联结果(DGI、, n个 = 2,978; 融合, n个 = 2,371; 科拉, n个 = 1,644; NHS中, n个 = 2,286; 巴基斯坦石油公司, n个 = 2,244; 萨迪尼亚, n个 = 4,305). 这个 我 2 统计的 40 采用Cochran的Q检验评估异质性。
基因分型和质量控制 初始GWA研究的基因分型在其他地方描述 4 , 11 , 13 - 15 ,但KORA除外,其在 补充方法 使用Sequenom MassARRAY iPLEX平台在欧美高度面板和复制面板FINRISK97、PPP、FUSION阶段2和KORA S4中进行基因分型。 从荟萃分析中,我们选择了78个SNP(三个iPLEX池;六个SNP失败),用于欧美高短板的基因分型( n个 =2189):SNP通过荟萃分析排名第一 P(P) 值,然后使用HapMap Phase II CEU群体(具有 第页 2 >0.5比SNP低 P(P) 值与该SNP组合在一起)。 当一个基因座有多个高级bin时,我们只对最显著的SNP进行基因分型,这样每个基因座或基因就只有一个SNP进行了基因分型。 由于这个DNA面板的特殊设计(高度分布的近端),也因为对高度的影响大小很小(并且在荟萃分析中被胜利者诅咒夸大了), 我们提倡在更大的随访队列标记中进行基因分型,这些标记的比值比与荟萃分析中观察到的效应方向一致(不考虑欧美CMH的大小 P(P) 值)。 对于FINRISK97面板,尝试了29个SNP,其中两个失败。 对于PPP小组,尝试了23个SNP,其中两个失败。 对于FUSION 2级面板,尝试了27个SNP,其中一个失败。 对于KORA S4面板,尝试了五个SNP,一个失败。 对于所有通过的SNP,基因分型成功率>96%,根据重复数据估计一致性错误率<0.1%。
致谢 我们感谢实验室成员的有益讨论,并感谢所有参与研究的人员。 DGI、FUSION、KORA和SardiNIA GWA扫描的贡献成员列于 补充说明 作者感谢生物信息咨询服务公司的C.Chen提供的专家编程,以及L.Qi的协助。 作者感谢国家癌症研究所癌症预防科的C.Berg和P.Prorok、前列腺、肺、结直肠和卵巢(PLCO)癌症筛查试验的筛查中心研究人员和工作人员、T.Riley和信息管理服务公司的工作人员,以及B.O'Brien和Westat公司的员工。 KORA感谢T.Meitinger和GSF基因分型工作人员的所有其他成员在生成SNP数据集方面所做的贡献。 我们感谢拉努西市市长和政府提供和布置诊所场地; 以及伊尔博诺、阿尔扎纳和埃利尼市长,当地公共卫生部门负责人ASL4。 以下机构为这项工作提供了支持:美国国立卫生研究院拨款5P01CA087969和CA49449(S.E.Hankinson),5UO1CA098233(D.J.H.),DK62370(M.B.),DK72193(K.L.M.),HG02651和HL084729(G.R.A.); 诺华生物医学研究院(D.Altshuler); 2004年6月至61日财政年度Dimes拨款(J.N.H.); 欧盟项目GenomEUtwin拨款QLG2-CT-2002-01254和芬兰科学院复杂疾病遗传学卓越中心(L.P.); Sigrid Juselius基金会(L.C.G.、V.S.和PPP); 芬兰糖尿病研究基金会和Folkhaälsan研究基金会及HUCH临床研究所(L.C.G.); 这项研究(部分)得到了美国国立卫生院国家老龄研究所内部研究计划的支持; PLCO的研究得到了癌症流行病学和遗传学司的内部研究计划以及DHHS国家癌症研究所癌症预防司的合同的支持; KORA/MONICA-Augsburg研究由德国慕尼黑/纽赫堡GSF-国家环境与健康研究中心资助,并由德国联邦教育与研究部(BMBF)资助; KORA的部分工作得到了德国国家基因组研究网络(NGFN)、慕尼黑健康科学中心(MC Health)(作为LMUinnovativ的一部分)以及NIH/NIDDK向GSF国家环境与健康研究中心(J.N.H.)分包5 R01 DK 075787的支持。
接入号码。 Genbank Entrez基因:与身高相关的验证基因座数据可通过登录码253461获得( ZBTB38型 ), 8091 ( HMGA2型 ), 57211 ( 126加仑 ) 3007 ( HIST1H1D公司 ), 8200 ( GDF5型 ), 55245 ( UQCC公司 ), 64399 ( HHIP公司 ), 9321 ( 行程11 ), 4287 ( ATXN3型 ), 389421 ( LIN28B系列 ), 84444 ( DOT1L公司 ), 6457 ( SH3GL3型 ), 57188 ( 金刚砂3 ), 79145 ( CHCHD7公司 ), 195814 ( RDHE2号机组 ), 1021 ( 川东北6 ).
工具书类
1 Hirschorn JN,Daly MJ。 常见疾病和复杂性状的全基因组关联研究。 Genet国家牧师。 2005; 6:95–108. doi:10.1038/nrg1521。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
2 国际单体型图联盟人类基因组的单倍型图。 自然。 2005; 437:1299–1320. doi:10.1038/nature04226。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
三。 惠康信托病例控制联合会对14000例七种常见疾病和3000例共享对照进行全基因组关联研究。 自然。 2007; 447:661–678. doi:10.1038/nature05911。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
4 Saxena R等。全基因组关联分析确定了2型糖尿病和甘油三酯水平的位点。 科学。 2007; 316:1331–1336. doi:10.1126/science.1142358。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
5 Frayling TM等人。FTO基因的一个常见变体与体重指数和儿童和成人肥胖倾向有关。 科学。 2007; 316:889–894. doi:10.1126/science.1141634。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
6 Scuteri A等人。全基因组关联扫描显示FTO基因中的遗传变异与肥胖相关性状相关。 公共科学图书馆-遗传学。 2007; 3:e115。 doi:10.1371/journal.pgen.0030115。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
7 费希尔RA。 孟德尔遗传假设下的亲属关系。 《爱丁堡皇家学会会刊》,1918年; 52:399–433. [ 谷歌学者 ]
8 Perola M等人,6602对欧洲双胞胎身高的联合基因组扫描:常见白人基因座的证据。 公共科学图书馆-遗传学。 2007; 3:e97。 doi:10.1371/journal.pgen.0030097。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
9 Mathias RA等人,《弗雷明翰心脏研究数据中对遗传力的年份和年龄匹配估计值的比较》。 BMC基因。 2003; 4(增刊1):S36。 doi:10.1186/1471-2156-4-S1-S36。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
10 Gunnell D等人,《身高、腿长和癌症风险:一项系统综述》。 流行病。 2001年修订版; 23:313–342. doi:10.1093/oxfordjournals.epirev.a000809。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
11 Sanna S等。GDF5-UQCC区域的常见变异与人类身高的变化有关。 自然基因。 2008; 40:198–203. doi:10.1038/ng.74。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
12 Weedon MN等人。HMGA2的一种常见变体与普通人群中的成人和儿童身高有关。 自然基因。 2007; 39:1245–1250. doi:10.1038/ng2121。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
13. Scott LJ等。芬兰人2型糖尿病全基因组关联研究检测到多种易感性变体。 科学。 2007; 316:1341–1345. doi:10.1126/science.1142382。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
14 Hunter DJ等。一项全基因组关联研究确定了FGFR2中与散发性绝经后乳腺癌风险相关的等位基因。 自然基因。 2007; 39:870–874. doi:10.1038/ng2075。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
15 Yeager M等人。前列腺癌的全基因组关联研究在8q24确定了第二个风险位点。 自然基因。 2007; 39:645–649. doi:10.1038/ng2022。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
16 Wichmann HE、Gieger C、Illig T.KORA-gen-resource,用于人群遗传学、控制和广泛的疾病表型。 Gesundheitswesen先生。 2005; 67(补充1):S26–S30。 doi:10.1055/s-2005-858226。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
17 Pilia G等人。6148名撒丁岛人心血管和人格特征的遗传性。 公共科学图书馆-遗传学。 2006; 2:e132。 doi:10.1371/journal.pgen.0020132。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
18 Weedon MN等。全基因组关联分析确定了20个影响成人身高的基因座。 自然基因。 2008年4月6日; doi:10.1038/ng.121。 高级在线出版物,doi:10.1038/ng.121。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
19 Campbell CD等人。展示欧美人口的分层。 自然基因。 2005; 37:868–872. doi:10.1038/ng1607。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
20 Price AL等。主成分分析纠正了全基因组关联研究中的分层。 自然基因。 2006; 38:904–909. doi:10.1038/ng1847。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
21 Price AL等。在遗传关联研究中识别欧美血统。 公共科学图书馆-遗传学。 2008; 4:e236。 doi:10.1371/journal.pgen.0030236。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
22 Chuang PT,美联社麦克马洪。 通过诱导刺猬结合蛋白调节脊椎动物刺猬信号传导。 自然。 1999; 397:617–621. doi:10.1038/17611。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
23 St-Jacques B、Hammerschmidt M、McMahon AP。 印度刺猬信号调节软骨细胞的增殖和分化,对骨形成至关重要。 基因开发1999; 13:2072–2086. doi:10.101/gad.13.16.2072。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
24 Mayr C、Hemann MT、Bartel DP。 破坏let-7和Hmga2之间的配对可以增强致癌转化。 科学。 2007; 315:1576–1579. doi:10.1126/science.1137999。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
25 Lee YS,Dutta A.肿瘤抑制剂microRNA let-7抑制HMGA2癌基因。 基因开发2007; 21:1025–1030. doi:10.1101/gad.1540407。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
26. Johnson CD等。let-7 microRNA抑制人类细胞的细胞增殖途径。 癌症研究2007; 67:7713–7722. doi:10.1158/0008-5472.CAN-07-1083。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
27 Krek A等人。组合微RNA靶预测。 自然基因。 2005; 37:495–500. doi:10.1038/ng1536。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
28 郭毅,等。人肝癌中lin-28同源物B(LIN28B)的鉴定和表征。 基因。 2006; 384:51–61. doi:10.1016/j.gene.2006.07.011。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
29 Pfeifer A等。缺乏cGMP依赖性蛋白激酶II的小鼠的肠道分泌缺陷和侏儒症。 科学。 1996; 274:2082–2086. doi:10.1126/science.274.5295.2082。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
30 Chikuda H等。环GMP依赖性蛋白激酶II是软骨细胞从增殖到肥大分化的分子开关。 基因开发2004; 18:2418–2429. doi:10.1101/gad.1224204。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
31 Sjoblom T等人。人类乳腺癌和结直肠癌的一致编码序列。 科学。 2006; 314:268–274. doi:10.1126/science.1133427。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
32 Asp J、Persson F、Kost-Alimova M、Stenman G.CHCHD7-PLAG1和TCEA1-PLAG1基因融合是由多形性涎腺腺瘤中的隐匿、染色体内8q重排引起的。 基因染色体。 癌症。 2006; 45:820–828. doi:10.1002/gcc.20346。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
33 Hirschhorn JN等人对多个群体身高的全基因组连锁分析揭示了几个区域与成年身高有连锁的证据。 Am.J.Hum.遗传学。 2001; 69:106–116. doi:10.1086/321287。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
34 Lohmueller KE、Pearce CL、Pike M、Lander ES、Hirschorn JN。 遗传关联研究的荟萃分析支持常见变异对常见疾病易感性的贡献。 自然基因。 2003; 33:177–182. doi:10.1038/ng1071。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
35 Zollner S,Pritchard JK。 克服胜利者的诅咒:根据病例对照数据估计外显率参数。 Am.J.Hum.遗传学。 2007; 80:605–615. doi:10.1086/512821。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
36 Purcell S,Cherny SS,Sham PC。遗传功率计算器:复杂性状的连锁和关联遗传作图研究的设计。 生物信息学。 2003; 19:149–150. doi:10.1093/bioinformatics/19.1.149。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
37 Vartiainen E等人,《芬兰心血管危险因素的变化》,1972年至1997年。 国际流行病学杂志。 2000; 29:49–56. doi:10.1093/ije/29.1.49。 [ 内政部 ] [ 公共医学 ] [ 谷歌学者 ]
38 Purcell S等人PLINK:一套用于全基因组关联和基于人群的连锁分析的工具。 Am.J.Hum.遗传学。 2007; 81:559–575. doi:10.1086/519795。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
39 Chen WM,Abecasis GR.全基因组关联扫描的家族关联测试。 Am.J.Hum.遗传学。 2007; 81:913–926. doi:10.1086/521580。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
40 Higgins JP、Thompson SG、Deeks JJ、Altman DG。 测量荟萃分析中的不一致性。 英国医学杂志2003; 327:557–560. doi:10.1136/bmj.327.7414.557。 [ 内政部 ] [ PMC免费文章 ] [ 公共医学 ] [ 谷歌学者 ]
关联数据 本节收集本文中包含的任何数据引用、数据可用性声明或补充材料。