基于油藏计算的状态表示的POMDP环境强化学习
Kodai Yamashita公司 * 和滨上智树 **

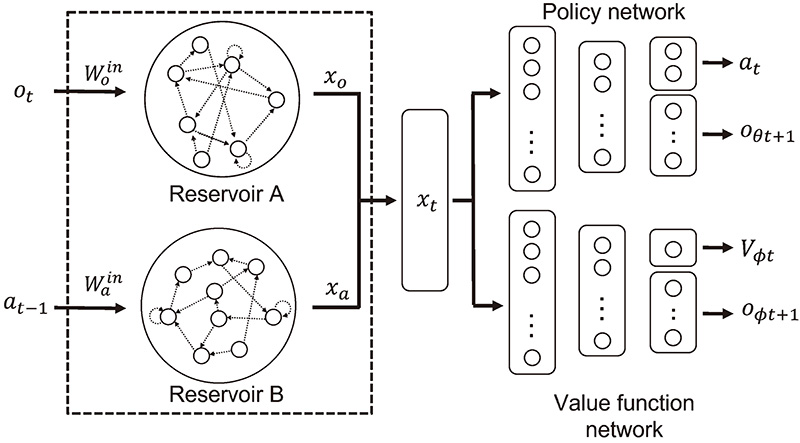
[1] S.Gu、E.Holly、T.Lillicrap和S.Levine,“利用异步非策略更新进行机器人操作的深度强化学习”,IEEE机器人与自动化国际会议(ICRA),第3389-3396页,2017年。 [2] D.Isele、R.Rahimi、A.Cosgun、K.Subramanian和K.Fujimura,“使用深度强化学习通过自动车辆导航闭塞交叉口”,IEEE机器人与自动化国际会议(ICRA),第2034-2039页,2018年。 [3] S.Kapturowski、G.Ostrovski、W.Dabney、J.Quan和R.Munos,“分布式强化学习中的重复体验回放”,《学习表征国际会议程序》,2019年。 [4] S.Hochreiter和J.Schmidhuber,“长-短期记忆”,《神经计算》,第9卷,第8期,第1735-1780页,1997年。 [5] H.Jaeger,“分析和训练递归神经网络的“回声状态”方法——附勘误表,”德国国家研究中心信息技术。, 第148卷,第34期,第13条,2001年。 [6] H.Jaeger和H.Haas,“利用非线性:预测混沌系统和无线通信节能”,《科学》,第304卷,第5667号,第78-80页,2004年。 [7] H.Chang和K.Futagami,“卷积油藏计算的强化学习”,《应用智能》,第50卷,第2400-2410页,2020年。 [8] Y.Wang和X.Tan,“POMDP的深度递归信念传播网络”,Proc。 AAAI人工智能大会,第35卷,第11期,第10236-102442021页。 [9] B.Bakker,“长短期记忆强化学习”,Proc。 神经信息处理系统进展14(NIPS 2001),第1475-1482页,2001年。 [10] T.Ni、B.Eysenbach和R.Salakhutdinov,“递归无模型RL是许多POMDP的强大基线”,arXiv预印arXiv:2110.05038,2021年。 [11] C.Gallicchio和A.Micheli,“深层储层计算网络的回声状态特性”,认知计算,第9卷,第337-350页,2017。 [12] J.Schulman、F.Wolski、P.Dhariwal、A.Radford和O.Klimov,“近似策略优化算法”,arXiv预打印arXiv:1707.063472017。 [13] X.Ma、J.Li、M.J.Kochenderfer、D.Isele和K.Fujimura,“利用潜在状态推理和时空关系进行自主驾驶的强化学习”,Proc。 IEEE机器人与自动化国际会议(ICRA),第6064-6071页,2021年。 [14] 松木(T.Matsuki)和柴田(K.Shibata),“使用多层读出的回声状态网络强化记忆任务的学习”,Proc。 第五届机器人智能技术与应用国际会议,2019年第17-26页。 [15] I.Szita、V.Gyenes和A.Lörincz,“回声状态网络的强化学习”,Proc。 第16届国际人工神经网络会议(ICANN),第1卷,第830-8392006页。 [16] A.Chattopadhyay、P.Hassanzadeh和D.Subramanian,“使用机器学习方法对多尺度Lorenz 96混沌系统进行数据驱动预测:水库计算、人工神经网络和长短期记忆网络”,《地球物理中的非线性过程》,第27卷,第3期,第373-3892020页。 [17] E.López、C.Valle、H.Allende-Cid和H.Allinde,“风电预测递归神经网络的比较”,Proc。 墨西哥模式识别会议(MCPR),第35-34页,2020年。 [18] K.Zheng,B.Qian,S.Li,Y.Xiao,W.Zhuang,和Q.Ma,“用于时间序列预测的长短期回波状态网络”,IEEE Access,第8卷,第91961-919742020页。 [19] L.Manneschi、M.O.A.Ellis、G.Gigante、A.C.Lin、P.D.Giudice和E.Vasilaki,“在分层回声状态网络中利用多个时间尺度”,《应用数学与统计学前沿》,2021年第6卷。 [20] T.Lesort、N.Díaz-Rodríguez、J.-F.Goudou和D.Filliat,“控制的状态表征学习:概述”,《神经网络》,第108卷,第379-392页,2018年。 [21]K.Ota、T.Oiki、D.K.Jha、T.Mariyama和D.Nikovski,“增加输入维度能改善深层强化学习吗?”。 第37届国际机器学习大会(ICML),第7424-74332020页。 [22]J.Munk、J.Kober和R.Babuška,“深度actor-critic控制的学习状态表征”,Proc。 IEEE第55届决策与控制大会(CDC)第4667-4673页,2016年。