在本节中,我们将介绍多步方案[ 27 ]定位为在GPU上并行。
2.1 前期工作 让 \((\Omega,\mathcal{F},\mathbb{P},\{mathcal {F}(F)_ {t} \}_{0\ le t\le t})\) 是一个完整的过滤概率空间。 在这个空间中,一个标准 d日 -维布朗运动 \(W_{t}\) 定义,以便过滤 \(数学 {F}(F)_ {t} }_{0\le-t\le-t}\) 是天然过滤 \(W_{t}\) 。我们定义 \(|\cdot|\) 作为欧氏空间中的标准欧氏范数 \(\mathbb{R}^{m}\) 或 \(\mathbb{R}^{m\乘以d}\) 和 \(L^{2}=L^ {2}_ {\mathcal{F}}(0,T;\mathbb{R}^{d})\) 全套 \(\mathcal {F}(F)_ {t} \) -值为的自适应平方可积过程 \(\mathbb{R}^{d}\) 此外,让 \(\mathcal {F}(F)_ {s} ^{t,x}\) 对于 \(t\le s\le t\) 成为 σ -布朗运动产生的场 \(\{x+W_ {r} -西_ {t} ,t\ le r \ le s \}\) 从时空点开始 \((t,x)\) 。我们定义 \(E_{s}^{t,x}[x]\) 作为随机变量的条件期望 X(X) 在过滤下 \(\mathcal {F}(F)_ {s} ^{t,x}\) ,即。 \(E_{s}^{t,x}[x]=E[x\vert\mathcal {F}(F)_ {s} ^{t,x}]\) 。
一对过程 \(((y_{t},z_{t{):[0,t]\times\Omega\to\mathbb{R}^{m}\times\ mathbb}R}^}m\ timesd}\) 是BSDE的解决方案( 1 )如果是的话 \(\mathcal {F}(F)_ {t} \) -自适应,平方可积,并且满足( 1 )在某种意义上
$$y_{t}=\xi+\int_{t}^{t}f(s,X_{s},y_{s},z_{s})\,ds-\int_{t}^{t}z_{s}\,dW_{s},\ quad t\ in[0,t)$$
(3)
哪里 \(f(t,X_{t},y_{tneneneep,z_{t{}):[0,t]\times\mathbb{R}^{m}\times\ mathbb}R}^}n}\times \ mathbb{R}^{m\ times d}\to\mathbb 是 \(\mathcal {F}(F)_ {t} \) -右边的第三项是Itó型积分。 此解在正则条件下存在[ 20 ]。
让我们考虑半线性PDE
$$\frac{\partialu}{\particalt}+\sum_{i=1}^ {n} 一个_ {i} (t,x)\分形{\部分u}{\部分x{i}}+\分形{1}{2}\sum{i,j=1}^{n}\sum{k=1}^ {d} b条_ {i,k}(t,x)b{j,k}(t,x)\分数{\部分^{2}u}{\部分x_ {i} x个_ {j} }+f\bigl(t,x,u,b(t,x)^{\top}D_{x}u\bigr)=0$$
(4)
与终端条件 \(u(T,x)=g(x)\) .通过直接应用Itó’s引理,可以得到以下定理。
定理1 (非线性Feynman-Kac定理)
让 \(在C^{1,2}中为u\) 令人满意的 ( 4 ) 假设存在一个常数 C类 这样的话 \(|b(t,x)^{\top}D_{x}u(t,x)|\leq C(1+|x|)\) 对于每个 \((t,x)\in[0,t]\times\mathbb{R}^{m}\) , 然后
$$y_{t}=u(t,X_{tneneneep),\qquad z_{t{=b(t,X_{tneneneei)^{top}D_{X}u(t、X_{t})$$
(5)
是唯一的解决方案 ( 1 ).
我们注意到[ 19 ]证明了由具有所有订单矩的Lévy过程驱动的BSDEs解的存在性和唯一性,该解可用于Lév y市场的定价。 一般非马尔可夫BSDE的非线性Feynman-Kac公式已在[ 21 ],其中考虑路径相关的拟线性抛物偏微分方程。 此外,还研究了完全非线性偏微分方程的Feynman-Kac表示,例如[ 23 ]。
2.2 稳定的半离散格式 让 N个 是一个正整数,并且 \(增量t=t/N) 均匀划分时间间隔的步长 \([0,T]\) : \(0=t_{0}<t_{1}<cdots<t_{N-1}<t_{N}=t\) ,其中 \(t_{n}=t_{0}+n\增量t\) , \(n=0,1,点,n) 。
让 k个 和 \(K_{y}\) 是两个正整数,这样 \(1\le-k\le-k_{y}\le-N\) ,分别表示时间层和插值点的数量。 BSDE( 2 )可以表示为
$$y_{t_{n}}=y_{t_n+k}}+\int_{t_n}}^{t_n+k{}f(s,y_{s},z_{s{)\,ds-\int_}n}}^{t_n+k}}z_{s}\,dW{s}$$
(6)
采用条件期望 \(E_{t_{n}}^{x}[\cdot]\) 在( 6 )为了获得解的适应性并使用三次样条多项式逼近被积函数 年 进程读取(请参阅 附录 )
$$y_{t_{n}}=E_{t_{n}}^{x}[y_{t_{n+k}}]+\sum_{j=0}^{k_ {y} -1个 }\biggl[a{j}^{y}\Delta t+\frac{b_{j}^{y{}\Delta t^{2}+\frac{c_{j{}^{y}\ Delta t^3}{3}+\ frac{d_{j}#y}\ Delta t ^{4}}{4}\biggr]+R_{y}^{n}$$
哪里 \(R_{y}^{n}\) 是插值误差。 对于 z(z) 过程,使用 我 和 \(K_{z}\) 而不是 k个 和 \(K_{y}\) ,将两边乘以 \(增量W_{t_{n+l}}) 在( 6 )取条件期望 \(E_{t_{n}}^{x}[\cdot]\) ,使用三次样条插值的参考方程读取(参见 附录 )
$$\开始{对齐}0={}&l\增量tE_{t_{n}}^{x}[z_{t_n+l}}]+\sum_{j=0}^{K_ {z} -1个 }\biggl[a{j}^{z{1}}\增量t+\frac{b_{j}^{z_{1}{\增量t^{2}}{2}+\frac{c_{j{}^{z{1}}\增量t{3}{3}+\frac{d_{j}^{z{1{}}\Delta t^4}{4}\biggr]\\&{}-\sum_{j=0}^{K_ {z} -1个 }\biggl[a{j}^{z{2}}\增量t+\frac{b_{j}^{z_2}}\三角形t^{2}{2}+\frac{c_{j{}^{z{2}}\增量t^{3}{3}+\frac{d_{j}*^{z_2}}\三角t^4}}{4}\biggr]+R{z}^n},\end{对齐}$$
哪里 \(R_{z}^{n}=R_{z_{1}}^{n}+R_{z_{2}}^{n}\) 是插值误差。 在[ 27 ],作者证明了当
$$\begin{aligned}&k=1,\ldot,k_{y},\quad\text{with}k_{y}=1,2,3,\ldots,N,\\&l=1,\ quad\text{with{k_{z}=1、2、3,\ltots,N.\end{alinged}$$
也就是说,该算法允许任意多个时间级别 \(K_{y}\) 和 \(K_{z}\) .利用三次样条插值条件计算未知系数,我们得到
$$\开始{对齐}y_{t_{n}}={}&E_{t_{n}}^{x}[y_{t_{n+K_{y}}]+\增量tK_y}\和_{j=0}^{K_y{}}\gamma_{K_{y},j}^{K_y}}E_{t_n}}^x}\bigl[f(t_{n+j},y_{t}{n+j}},z{t_{n+j}})\bigr]+R{y}^{n},\\z{t_n}}={}&\Biggl(E_{t_n{}}^x}[z{t_}n+1}}]+\sum{j=1}^{K{z}}\gamma_{K{z},j}^1}E_{t{n}^{x}}\bigl[f(t{n+j},y{t{n+j} }{n}}{\增量t},\结束{对齐}$$
(7)
具有 \(\gamma_{K_{y},j}^{K_}y}) 和 \(\gamma_{K_{z},j}^{1}\) 表示三次样条插值的计算系数(表 1 和表 2 给出最多6个时间级别的值)。 如所示[ 27 ]本地错误( 7 )由提供
$$\bigl\vert R_{y}^{n}\bigr\vert=\mathcal{O}\bigl$$
前提是 (f) 和 克 足够光滑。 在( 7 )我们需要除以Δ 吨 找到的价值 z(z) 过程。 因此,为了平衡时间截断错误,可以设置 \(K{z}=K{y}+1) 。
表1系数 \({\gamma_{K_{y},j}^{K__y}}{j=0}^{K_y}) 直到 \(K_{y}=6\) 表2系数 \({\gamma_{K_{z},j}^{1}{j=0}^{K_}z}}) 直到 \(K_{z}=6\) d维情形的稳定半离散格式如下:我们表示 \((y^{n},z^{n{)\) 近似于 \((y_{t_{n}},z_{t_{n}})\) ,给定随机变量 \((y^{N-i},z^{N-i})\) , \(i=0,1,点,K-1) 具有 \(K=\max\{K_{y},K_{z}\}) .然后 \((y^{n},z^{n{)\) 可以为找到 \(n=n-K,点,0) 这样的话
$$开始{对齐}&y^{n}=E_{t_{n}}^{x}\bigl[y^{n+K_{y}}\bigr]+\Delta tK_{y}\sum_j=0}^{K_y}}\gamma_{K_y},j}^{K_y{}}E_{t_n}}x}\bigl[\bigl(t_{n+j},y^{n+j{,z^{n+j}\bigr)\bigr],\\&z^{n}=\Biggl(E_{t_{n}}^{x}\bigl[z^{n+1}\biger]+\sum_{j=1}^{K{z}}\gamma_{K{z},j}^{1}E_{t{n}{x}\bigl[f\bigl(t_{n+1},y^{n+j},z^{n+j}\较大) \三角洲W_{t_{n+j}}^{\top}\bigr]-\sum_{j=1}^{K_{z}\gamma_{K_}z},j}^{1}E_{t_{n}}^}x}\bigl[z^{n+j}\biger]\Biggr)\Big/\gamma_{K{z},0}^{1}\end{aligned}$$
(8)
哪里 \(y^{n}=(y^}n,\波浪线{m}}){\波浪线}\times1}\) , \(z^{n}=(z^}n,\瓦尔德{m},\瓦尔特{d}){\瓦尔德}m}\乘以d}\) , \(Delta W_{t_{n+j}}^{top}=(W_{t_{n+j}}^}{\tilde{d}})_{\tilde{d}\times1}-(W_}t_{n}}^\\tilde{d\times1}) , \(tilde{m}=1,2,\ldots,m\) 和 \(tilde{d}=1,2,\ldots,d\) 在下文中,我们仅给出了误差分析的结果,以供参考[ 27 ]和[ 32 ]。
引理1 中局部截断误差的局部估计 ( 7 ) 满足
$$\bigl\vert R_{y}^{n}\bigr\vert\le C\Delta t^{min\{K_{y{+2,5\}},\qquad\bigl\overt R_{z}^{n}\biger\vert\leC\Deltat^{min \{K_{z}+2,5\}}$$
哪里 \(C>0\) 是一个常数,取决于 T型 , (f) , 克 和的导数 (f) 和 克 。
定理2 假设初始值满足
$$\textstyle\begin{cases}\max_{N-K_{y}+1\len\leN}E[\verty_{t_N}}-y^{N}\vert]=\mathcal{O}(\Delta t^{K_y}+1}),\\max_{N-K_{y}+1 \len\le N}E[\vert y_{t_{N}-y_{N{}\vert]=\mathcal{0}(\ Delta t_{4}),\结束{cases}$$
哪里 \(K_{y}=1,2,3\) 对于第一个方程和 \(K_{y}>3\) 对于第二个 。 对于足够小的时间步长 Δ 吨 可以看出
$$\sup_{0\len\leN}E\bigl[\bigl\vert y_{t_{n}}-y^{n}\bigr\vert\bigr]\leC\Delta t^{min\{K_{y}+1,4\}}$$
哪里 \(C>0\) 是一个常数,取决于 T型 , (f) , 克 和的导数 (f) 和 克 。
定理3 假设初始值满足
$$\textstyle\begin{cases}\max_{N-K_{z}+1\len\leN}E[\vertz_{t_N}}-z^{N}\vert]=\mathcal{O}(\Delta t^{K_{z}}),\\max_{N-K_{z}+1 \len\le N}E[\vert z_{t{N}}-z^}\vert]=\mathcal{0}(\ Delta t|3}),\结束{案例}$$
哪里 \(K_{z}=1,2,3\) 对于第一个方程和 \(K_{z}>3\) 对于第二个 , 定理中初值的条件 2 已实现 。 对于足够小的时间步长 Δ 吨 可以看出
$$\sup_{0\len\leN}E\bigl[\bigl\vert z_{t_{n}}-z^{n}\bigr\vert\bigr]\leC\Delta t^{min\{K_{y}+1,K_{z},3\}}$$
哪里 \(C>0\) 是一个常数,取决于 T型 , (f) , 克 和的导数 (f) 和 克 。
备注1 如果 (f) 不依赖于过程 z(z) ,的最大收敛阶 年 过程是4和3 z(z) 过程; 如果 (f) 取决于过程 z(z) ,的最大收敛阶 年 和 z(z) 过程为3。
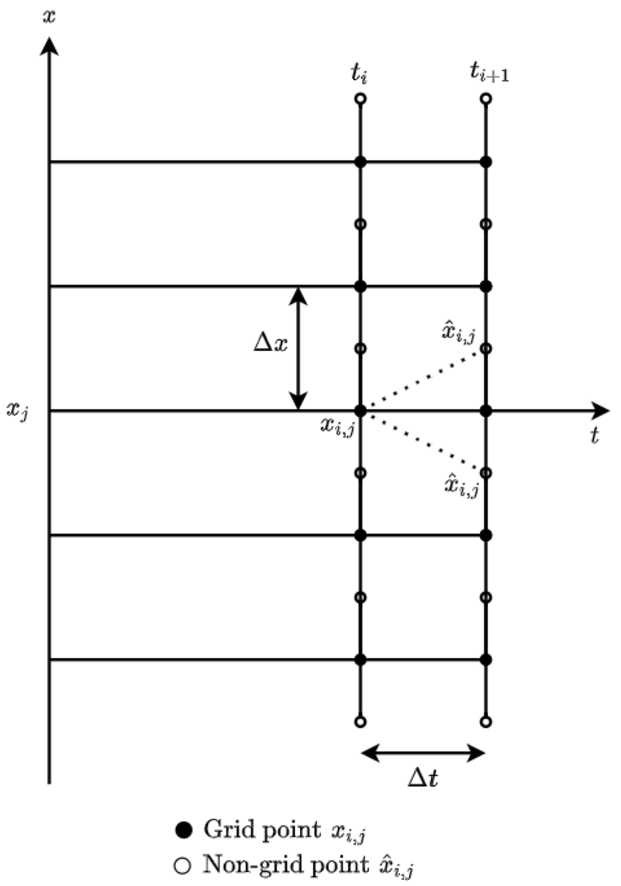
2.3 全离散方案 让Δ x个 表示均匀分区中的步长 d日 -尺寸实轴,即。
$$\mathbb{R}^{\tilde{d}}=\Bigl\{x_{i}^{\ tilde{d\}}\big\vertx_{i}^{\\tilde{d}}\in\mathbb{R},i\in\mathbb{Z},x_{i}^\\tilde}{d}-x_{i}^{\tilde{d}},\lim_{i\to\pm\infty}x_{i}^{\ tilde{d}}=\pm\infty\Bigr\}$$
哪里
$$\mathbb{R}^{\tilde{d}}=\mathbb{R}^{1}\times\mathbb}R}^}2}\times\cdots\times\mathbb{R{^{d}\quad\text{和}\qua2\tilde{d}=1,2,\ldots,d$$
让 \(x{\mathbf{i}}=(x^ {1}_ {i{1}},x^ {2}_ {i_{2}},\ldot,x^ {d}_ {i{d}})\) 对于 \(\mathbf{i}=(i{1},i{2},\ldots,i{d})\in\mathbb{Z}^{d}\) .我们表示 \(年)^ {无}_ {\mathbf{i}},z^ {无}_ {\mathbf{i}})\) 近似于 \((y_{t_{n},x_{\mathbf{i}}},z_{t_{n},x_{\mathbf{i}})\) ,给定随机变量 \(年^ {北}_ {\mathbf{i}},z^ {北}_ {\mathbf{i}})\) , \(l=0,1,点,K-1) 具有 \(K=\max\{K_{y},K_{z}\}) .然后 \(年)^ {无}_ {\mathbf{i}},z^ {无}_ {\mathbf{i}})\) 可以为找到 \(n=n-K,点,0) 这样的话
$$\开始{对齐}(&y)^ {无}_ {\mathbf{i}}=\hat {电子}_ {t_{n}}^{x_{mathbf{i}}\bigl[\hat{y}^{n+K_{y}}\bigr]+\Delta tK_{y}\sum_{j=1}^{K_y}}\gamma_{K_y},j}^{K_{y{}}\hat {电子}_ {t{n}}^{x{mathbf{i}}\bigl[f\bigl(t{n+j},what{y}^n+j{,what{z}^{n+j}\bigr)\bigr]+\Delta tK{y}\gamma_{K{y{,0}^{K{y}}f\bigle(t}n},y^ {无}_ {\mathbf{i}},z^ {无}_ {\mathbf{i}\bigr),\\&z^ {无}_ {\mathbf{i}}=\Biggl(\hat {E}_ {t{n}}^{x{mathbf{i}}\bigl[\hat{z}^{n+1}\bigr]+\sum_{j=1}^{K{z}}\gamma_{K{z},j}^{1}\hat {电子}_ {t{n}}^{x{mathbf{i}}\bigl[f\bigl(t{n+j},what{y}^{n+j},hat{z}^{n+j}\bigr)\Delta W{t{n+j}}^{top}\biger]-\sum_{j=1}^{K{z}}\gamma_{K{z},j}^{1} {电子}_ {t_{n}}^{x_{mathbf{i}}\bigl[\hat{z}^{n+j}\bigr]\Biggr)\big/\gamma_{K{z},0}^{1},\end{aligned}$$
(9)
哪里 \(帽子 {电子}_ {t{n}}^{x{i}}[\cdot]\) 用于表示条件期望的近似值。 每个空间网格点的计算 \(x{\mathbf{i}}\) 在( 9 )每个时间层都是独立的 \(t{n}\) 因此,并行化策略与空间离散化完全相关,这将在以下章节中讨论。
条件期望中的函数包括 d日 -布朗运动的维数概率密度函数,可以选择例如高斯-埃尔米特求积规则,以仅用几个空间点实现高精度。 条件期望可以通过巧妙的表格插值得到足够精确的近似值
$$\帽子 {电子}_ {t_{n}}^{x_{mathbf{i}}\bigl[\hat{y}^{n+k}\bigr]=\frac{1}{\pi^{\frac}{d}{2}}\sum_{\Lambda=1}^{L}\omega_{\Lambda}\hat}(x_{\mathbf}i}+\sqrt{2k\Delta t}a_{\Lambda})$$
(10)
哪里 \({y}^{n+k}\) 是在空间点处插值 \(((x_{\mathbf{i}}+\sqrt{2k\Delta t}a{\Lambda})\) 基于 \(y^{n+k}\) 值, \((\omega{\Lambda},a{\Lambeda})\) 对于 \(\Lambda=(\Lambda_{1},\Lambda _{2},\ ldots,\ Lambda_{d})\) 是Hermite次多项式的权重和根 我 (请参见[ 12 ]), \(\omega{\Lambda}=\prod_{\tilde{d}=1}^{d}\omega_{\Lambda{\tilde{d}}\) , \(a{\Lambda}=(a{Lambda{1}}、a{\Lambda}},\ldots,a{\Lambda{d}}) 和 \(\sum_{\Lambda=1}^{L}=\sum_{\Lambda{1}=1,\ldots,\Lambda{d}=1}^}L,\ldot,L}\) 以类似的方式,可以在( 9 ).