块编辑器post是post的适当块软件表示:每个块是什么及其基本数据是什么的语义一致描述的集合。这种表示只存在于内存中。它是追逐在排字工人的车间里种类已附加并重新定位。
块编辑器帖子不是它生成的工件,即帖子_内容后者是打印页面,针对读者进行了优化,但保留了其不可见的标记,以便以后编辑。
块编辑器的输入和输出是具有当前格式的块对象树:
常量值=[块1,块2,块3];
每个块对象都有一个id、一组属性,可能还有一个子块列表。
常量块={clientId,//唯一字符串标识符。type,//块类型(段落、图像…)attributes,//(key,value)表示当前块的直接属性/内容的属性集。innerBlocks,//子块或内部块的数组。};
请注意属性键和类型,允许的内部块由块类型定义。例如,核心报价块具有引用表示引用内容的字符串属性,而标题块具有数字水平属性,表示标题的级别(1到6)。
在编辑器中块的生命周期中,块对象可以接收额外的元数据:
是否有效:表示块是否有效的布尔值;原始内容:块的原始HTML序列化。
示例
//一个简单的段落块。常量段落块1={clientId:'51828be1-5f0d-4a6b-8099-f4c6f897e0a3',type:'核心/段落',属性:{content:'这是段落块的<strong>内容</strong>',dropCap:为真,},};//分隔块。常量分隔符块={客户端ID:“51828be1-5f0d-4a6b-8099-f4c6f897e0a4”,type:'磁芯/分离器',属性:{},};//列块,每列上有一个段落块。常量列块={客户端ID:“51828be1-5f0d-4a6b-8099-f4c6f897e0a7”,type:'核心/列',属性:{},内部块:[{客户端ID:“51828be1-5f0d-4a6b-8099-f4c6f897e0a5”,type:'核心/列',属性:{},innerBlocks:[段落Block1],},{客户端ID:“51828be1-5f0d-4a6b-8099-f4c6f897e0a6”,type:'核心/列',属性:{},innerBlocks:[paragraphBlock2],},],};
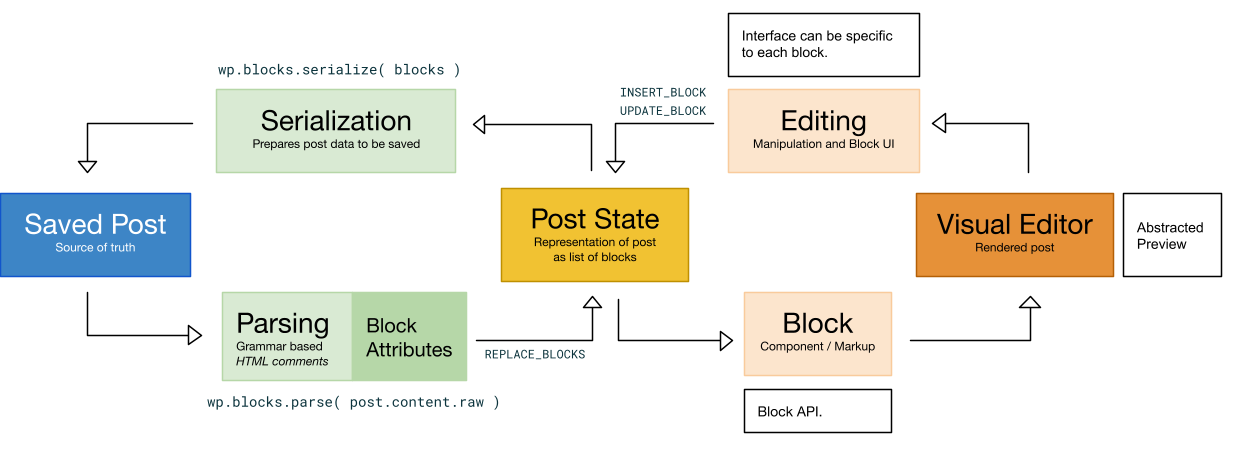
然而,这种数据模型是在编辑帖子时保存在内存中的。它在呈现时对页面查看器不可见,就像打印的页面没有印刷中产生的字母结构的痕迹一样。
由于整个WordPress生态系统都期望在呈现或编辑帖子时接收HTML,因此块编辑器将其数据转换为可以保存的内容帖子_内容通过序列化。这确保了内容只有一个真实来源,并且该来源保持可读性,并与目前与WordPress内容交互的所有工具兼容。如果我们单独存储对象树,我们将面临以下风险帖子_内容以及树不同步和两地的数据复制问题。
因此,序列化过程将块树转换为HTML,使用HTML注释作为显式块分隔符,其中可以包含非HTML形式的属性。这是在打印页面上打印不可见的标记,留下原始结构化意图的痕迹。
这是过程的一端。另一个是如何在文章再次编辑时重新创建块集合。正式语法定义了块编辑器帖子的序列化表示应该如何加载,就像一些基本规则定义了如何将树转换为类似HTML的字符串一样。块编辑器的帖子不是设计为手动编辑的;它们不是被设计成HTML文档,因为块编辑器帖子本质上不是HTML。
顺便提一下,它们正好被存储在帖子_内容在某种程度上,它们不需要进行任何转换,就可以被任何遗留系统查看。确实,在没有相应机制的情况下将存储的HTML加载到浏览器中可能会降低体验,如果其中包含动态内容块,则可能无法加载动态元素,服务器生成的内容可能不会出现,交互式内容可能保持静态。然而,它至少可以防止无法查看关于不知道块的主题和安装的块编辑器帖子,并且它提供了最容易访问的内容方式。换句话说,即使保存的HTML按原样呈现,帖子也基本保持不变。
相反,我们选择了一种方法来保持现有HTML语法的正式性、明确性和明确性。在HTML中有许多选项。
在这些选项中,有人提出了一种新颖的方法:通过在HTML注释中存储数据,我们将知道我们不会破坏文档中的其余HTML,浏览器应该忽略它,并且我们可以简化解析文档的方法。
HTML注释的独特之处在于,它们不能合法地存在于模糊的位置,例如HTML属性内部,例如<img alt='data-id=“14”'>。评论也很随意。虽然HTML属性很难正确解析,但注释很容易由前导<!--后面跟除--直到第一次-->。这种简单性和允许性意味着解析器可以通过多种方式实现,而无需正确理解HTML,而且我们可以在注释中自由使用更方便的语法,只需转义双连字符序列。我们在如何将块属性存储为注释中的JSON文本时,就利用了这一点。
在通过解析器运行之后,我们只剩下一个简单的对象,可以用惯用的方式进行操作,我们不必担心对数据进行转义或取消转义。它是通过序列化过程为我们处理的。因为注释与其他HTML标记如此不同,而且我们可以执行第一次遍历来提取顶级块,所以我们实际上并不依赖于拥有完全有效的HTML!
这对我们制作解析器的简单性和性能有着显著的影响。这些明确的边界还可以保护单个块中的损坏,防止其渗入其他块或使整个文档失去光泽。它还允许系统在渲染之前识别未识别的块。
注意:块的定义方面是它们的语义和它们提供的隔离机制:换句话说,它们的标识。另一方面,他们的数据存储在哪里是一个更自由的方面。块不仅支持静态本地数据(通过HTML注释内或块的HTML内的JSON文本),还支持更多机制(例如、全局块或以其他方式诉诸互补存储WP_支柱对象)。请参阅属性了解详细信息。
当块在编辑会话后保存到内容中时,其属性取决于块的性质,并被序列化为这些显式的注释分隔符。
<!-- wp:图像--><figure class=“wp-block-image”><img src=“source.jpg”alt=“”/></figure><!-- /wp:图像-->
在显示之前需要服务器重新渲染的纯动态块可能如下所示:
<!-- wp:latest-posts{“postsToShow”:4,“displayPostDate”:true}/-->
总之,块编辑器工作流使用标记分隔符来帮助将保存的文档解析为内存中的块树。在编辑期间,所有操作都发生在块树中。该过程通过将块序列化回帖子_内容.
工作流过程依赖于序列化/解析器对来持久化帖子。假设,post数据结构可以使用插件存储,也可以从远程JSON文件中检索以转换为块树。