主要功能
加速学习
表达式操作图API
Fusion支持
深度神经网络
特征
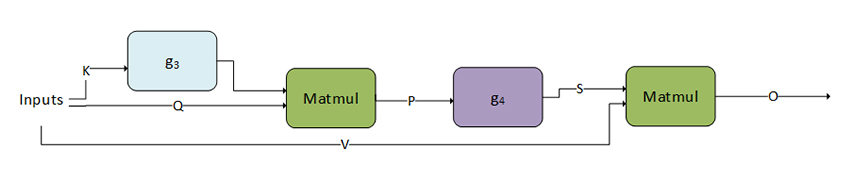
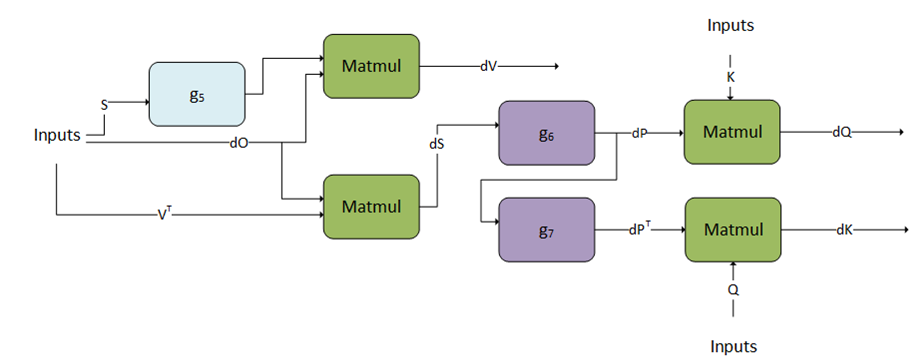
加速的计算机绑定操作,如卷积和matmul 优化了内存绑定操作,如池化、softmax、归一化、激活、逐点和张量变换 计算机绑定和内存绑定操作的融合 运行时融合引擎,在运行时为常见融合模式生成内核 优化融合注意力等重要专业模式 针对给定问题规模选择正确实现的启发式方法
将内存限制操作灵活地融合到数学和卷积的输入和输出中 将注意力和卷积等模式与规范化进行专门融合 支持正向和反向传播 预测给定问题规模的最佳实现的启发式方法 开源C++前端API 序列化和反序列化支持