由于采用了多摄像机输入和深度卷积骨干网络,用于训练自动驾驶感知模型的GPU内存占用量很大。现有的减少内存使用的方法通常会导致额外的计算开销或不平衡的工作负载。
这篇文章描述了NVIDIA和NIO之间的联合研究,NIO是智能电动汽车的开发商。 具体来说,我们探索了张量并行卷积神经网络(CNN)训练如何帮助减少GPU内存占用。我们还演示了NIO如何提高自主车辆感知模型的训练效率和GPU利用率。
自主车辆感知模型训练 自动驾驶感知任务以多摄像机数据为输入,以CNN为主干提取特征。 CNN的正向激活是形状的特征映射(N、C、H、W),其中N、C,H、W分别是图像数量、通道数量、高度和宽度。 需要保存激活以进行反向传播,因此主干的训练通常会消耗大量内存。
例如,假设有六个摄像头RGB输入,分辨率为720像素,批大小设置为1,则主干网络的输入形状为(6,3,720,1280)。 对于RegNet或ConvNeXt等骨干网络,激活的内存占用量远远大于模型权重和优化器状态的内存使用量,并且可能超过GPU内存大小的限制。
NIO自主驾驶团队的研究表明,采用更深层次的模型和更高的图像分辨率可以显著提高感知精度,特别是对于识别小目标和远距离目标。 NIO Aquila超级感应系统由11个800万像素高清摄像头提供动力,每秒生成8 GB的图像数据。
GPU内存优化需求 深度模型和高分辨率输入对GPU内存优化提出了更高的要求。 当前解决激活过多GPU内存占用的技术包括渐变检查点,它在正向传播期间仅保留部分层的激活。 对于其他层,在反向传播期间重新计算激活。
尽管节省了GPU内存,但它增加了计算开销并降低了模型训练的速度。 此外,设置渐变检查点通常需要开发人员根据模型结构进行选择和调试,这给模型培训带来了额外的成本。
NIO还使用了流水线并行,其中神经网络根据GPU内存开销平均分割,并部署到多个GPU进行训练。 此方法在多个GPU之间平均分配存储需求。 然而,它会导致GPU之间的负载不平衡以及一些GPU的利用率不足。
基于PyTorch DTensor的张量并行CNN训练 考虑到这些因素,NVIDIA和NIO联合设计并实施了张量并行CNN训练,将输入和中间激活划分为多个GPU。 模型权重和优化器状态在每个GPU上复制,就像数据并行训练的实践一样。 这种方法减少了单个GPU的GPU内存占用和带宽压力。
在PyTorch 2.0中引入的DTensor提供原语来表示张量分布,例如切分和复制。 由于DTensor的底层实现已经封装了诸如 NVIDIA集体通信库(NCCL) .
通过对DTensor的抽象,用户可以轻松构建各种并行训练策略,包括张量并行、分布式数据并行和完全分片数据并行。
实施 将CNN模型用于视觉任务, ConvNeXt-XL型 作为示例,我们将演示张量并行CNN训练。 按如下方式放置D传感器:
模型参数: 复制
在每个GPU上重复放置。 该模型包含3.5亿个参数,在FP32中存储时消耗1.4GB的GPU内存。
模型输入: 碎片(3)
切片(N,C,H,W)的W尺寸。 将输入片放置在每个GPU上。 例如, 碎片(3) 对于在四个GPU上输入形状(7、3、512、2048),生成四个形状切片(7、5、512和512)。
激活: 碎片(3)
切片(N,C,H,W)的W尺寸。 将激活片放在每个GPU上。
模型参数的梯度: 复制
优化器状态: 复制
上述配置可以通过DTensor提供的API完成。 用户只需指定模型参数和模型输入的位置,其他张量的位置将自动生成。
为了启用张量并行训练,应该为卷积算子注册传播规则 aten.卷积 和 aten.卷积_向后 这将根据输入DTensor的位置确定输出DTensor位置:
aten.卷积
输入位置为 碎片(3) ,重量和偏差位置为 复制 ,输出位置为 碎片(3)
aten.卷积_向后
梯度输出 位置是 碎片(3) ,重量和偏差位置为 复制 , 渐变_输入 位置是 碎片(3) , 坡度_重量 和 梯度_偏差 放置位置是 _部分
D传感器 _部分 当使用其值且默认的约简运算符为sum时,placement会自动执行约简操作。
接下来是张量并行卷积算子的正向和反向实现。 由于激活是跨多个GPU切片的,因此一个GPU上的本地卷积可能需要来自相邻GPU的激活边缘数据,这需要GPU之间的通信。 在ConvNeXt-XL模型中,此问题在其下采样层的卷积中不存在,而必须在Block中的深度卷积中处理。
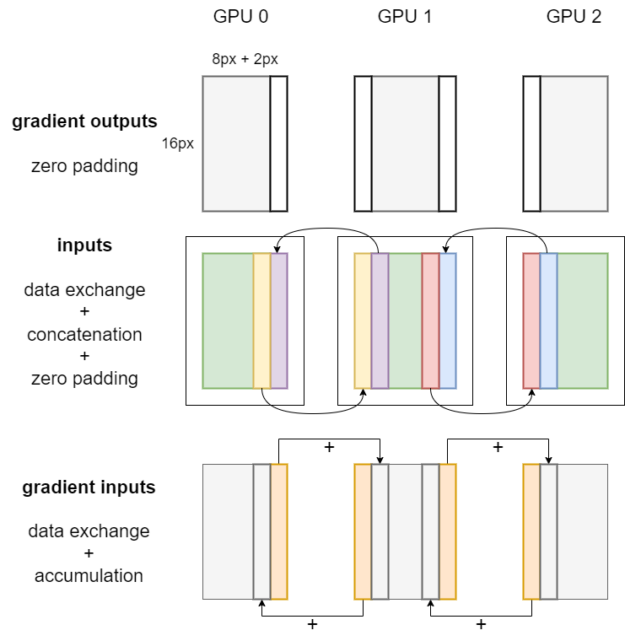
如果不需要进行数据交换,用户可以直接调用卷积的正向和反向算子,并传入局部张量。 如果需要交换局部激活的张量边缘数据,请使用图1和图2所示的卷积正向和反向算法。 我们省略了图中的N维和C维,并假设卷积核大小为5×5,填充为2,步幅为1
图1。 张量并行卷积正演算法
如图1所示,当卷积核大小为5×5,填充为2,步幅为1时,每个GPU上的本地输入应从其相邻的GPU获取宽度为2的输入边,并将接收到的边数据连接到自身。 换句话说,需要在GPU之间进行数据交换,以确保张量并行卷积的正确性。 可以通过调用封装在PyTorch中的NCCL发送接收通信操作符来启用此数据交换。
值得一提的是,当激活被分割到多个GPU上时,卷积操作符的一些填充是不需要的。 输出中不需要的填充引入的无效像素应在完成本地卷积正向传播后进行裁剪,如图1中的蓝色条纹所示。
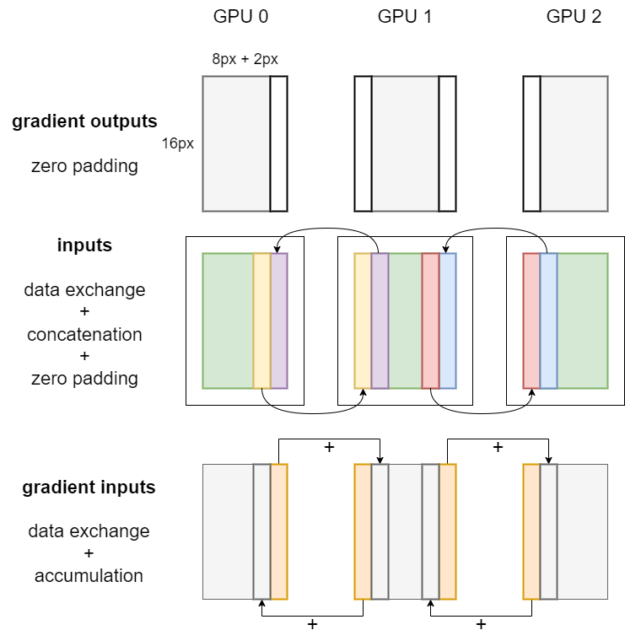
图2显示了张量并行卷积的反向传播工作流程。 首先,对梯度输出应用零填充,这与正向传播期间对输出的裁剪操作相对应。 对于本地输入,执行相同的数据交换、串联和填充过程。
然后,通过在每个GPU上调用卷积反向算子,可以获得权重梯度、偏置梯度和梯度输入。
图2。 张量并行卷积的反向传播工作流程 权重梯度和偏差梯度的位置为 _部分 ,因此在使用多个GPU时,它们的值将自动减少。 梯度输入的位置为 碎片(3) .
最后,将局部梯度输入的边缘像素发送到相邻的GPU,并在相应的位置进行累加,如图2中的橙色条所示。
除了卷积层之外,ConvNeXt-XL还有几个需要处理的层,以支持张量并行训练。 例如,应该为 阿滕·伯努利 由使用的运算符 DropPath(放置路径) 层。 此运算符应放置在随机数生成跟踪器的分布区域中,以确保GPU之间的一致性。
所有代码都已合并到 PyTorch GitHub回购 ,因此用户可以通过直接调用DTensor的高级API来实现张量并行CNN训练。
利用张量并行性训练ConvNeXt的基准结果 我们对 NVIDIA DGX公司 AI平台,探索ConvNeXt XL训练的速度和GPU内存占用。 梯度检查点技术和DTensor技术是兼容的,结合这两种技术可以更显著地减少GPU内存使用。
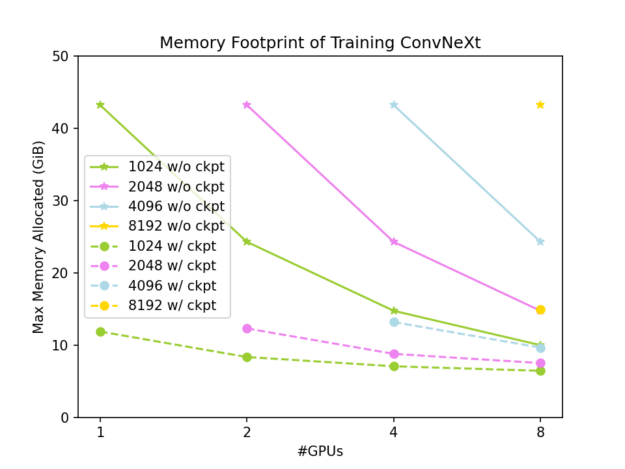
这个基准测试的基准是在一个输入大小为(7,3,512,1024)的NVIDIA GPU上使用PyTorch本机张量。 如果没有梯度检查点,GPU内存占用量为43.28 GiB,单个训练迭代需要723 ms。如果使用梯度检查点的话,这两个值分别为11.89 GiB和934 ms。
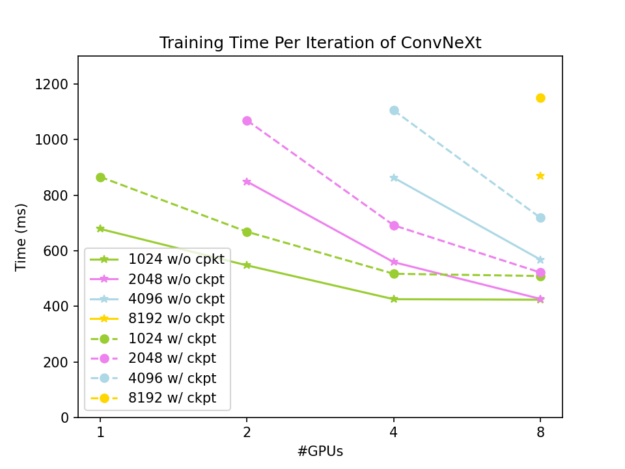
完整结果如图3和图4所示。 全局输入形状为(7,3,512,W),其中W在1024到8192之间变化。 实线是没有渐变检查点的结果,而虚线是渐变检查点结果。
图3。 不同测试条件下的GPU内存占用 图4。 不同测试条件下每次迭代的训练时间 如图3所示,使用DTensor对激活进行切片可以有效地减少ConvNeXt-XL训练的GPU内存占用,当我们同时应用DTensor和梯度检查点时,可以将其降低到非常低的水平。 如图4所示,张量并行方法具有良好的弱可伸缩性,并且在问题规模足够大时提供良好的强可伸缩性。 这将调查未使用渐变检查点的情况:
在两个GPU上全局输入形状(7,3,512,2048)的情况下,单个迭代需要937ms。 在四个GPU上全局输入形状(7、3、512、4096)的情况下,一次迭代需要952 ms。 在八个GPU上全局输入形状(7、3、512、4096)的情况下,一次迭代需要647毫秒。
结论 利用DTensor实现张量并行CNN训练,为有效提高NADP(NIO Autonomous Driving Development Platform,NIO自主驾驶开发平台)上的训练效率提供了解决方案,NADP是NIO核心自主驾驶服务的研发平台。 NADP提供高性能计算和全链工具,处理数十万日常推理和训练任务,确保主动安全和驾驶员辅助功能的不断发展。
这一关键方法使NADP能够以10000-GPU的规模执行并行计算。 它提高了GPU的利用率,降低了模型训练的成本,并使模型结构更加灵活。 基准测试表明,该方法在NIO的自动驾驶场景中表现良好,并有效解决了培训大型视觉模型的挑战。
基于PyTorch DTensor的CNN张量并行训练可以显著减少内存占用并保持良好的可扩展性。 我们预计,通过充分利用多个GPU的计算能力和互连,这种方法将使感知模型训练更容易获得。
有关更多详细信息,请访问 PyTorch GitHub回购 .