生成性人工智能 有潜力改变每一个行业。 人类工人已经在使用 大型语言模型 (LLM)解释、推理和解决困难的认知任务。 检索增强生成 (RAG)将LLM连接到数据,通过让LLM访问最新和准确的信息来扩展LLM的用途。
许多企业已经开始探索RAG如何帮助他们自动化业务流程和挖掘数据以获得洞察力。 尽管大多数企业已经启动了多个与生成性人工智能用例相一致的试点, 据估计,在不久的将来,他们中的90%不会超过评估阶段 。将引人注目的RAG演示转化为能够提供真正商业价值的生产服务仍然具有挑战性。
在本博客中,我们将介绍NVIDIA AI如何通过四个步骤帮助您将RAG应用程序从试点转移到生产。
构建企业级RAG管道 开发和部署生产就绪的企业RAG管道存在许多障碍。
IT管理员面临着与LLM安全性、可用性、可移植性和数据治理相关的挑战。 企业开发人员可能会为LLM的准确性和LLM编程框架的整体成熟度而苦苦挣扎。 随着新的LLM模型和RAG技术的出现,开源创新的速度对每个人来说都是势不可挡的。
简化生产RAG开发和部署的构建块 NVIDIA通过为云原生端到端RAG应用程序提供参考体系结构,帮助管理这种复杂性。 参考架构是模块化的,将流行的开源软件与NVIDIA加速相结合。 利用一套全面的模块化构建块提供了几个好处。
首先,企业可以有选择地将新组件集成到现有基础架构中。 其次,他们可以为管道的每个阶段选择商业组件和开源组件。 企业可以为自己的用例自由选择合适的组件,同时避免供应商锁定。 最后,模块化体系结构简化了管道每个阶段的评估、观察和故障排除。
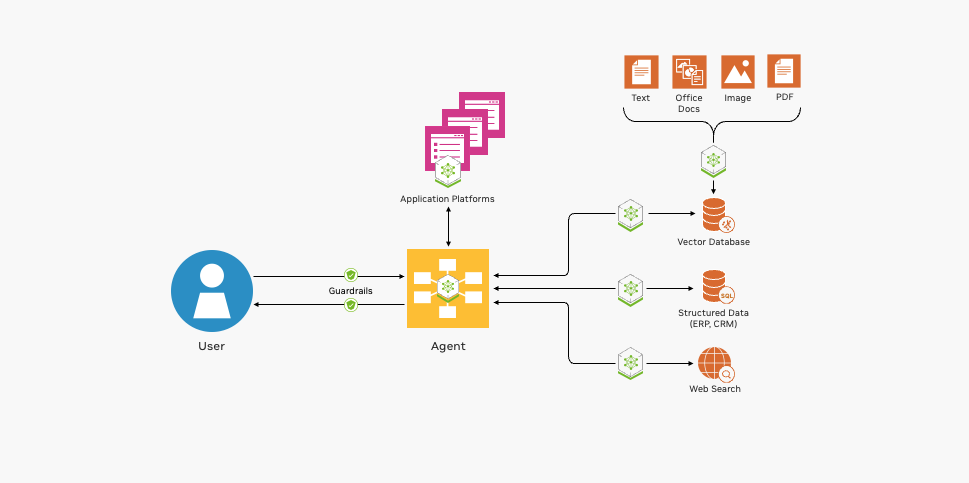
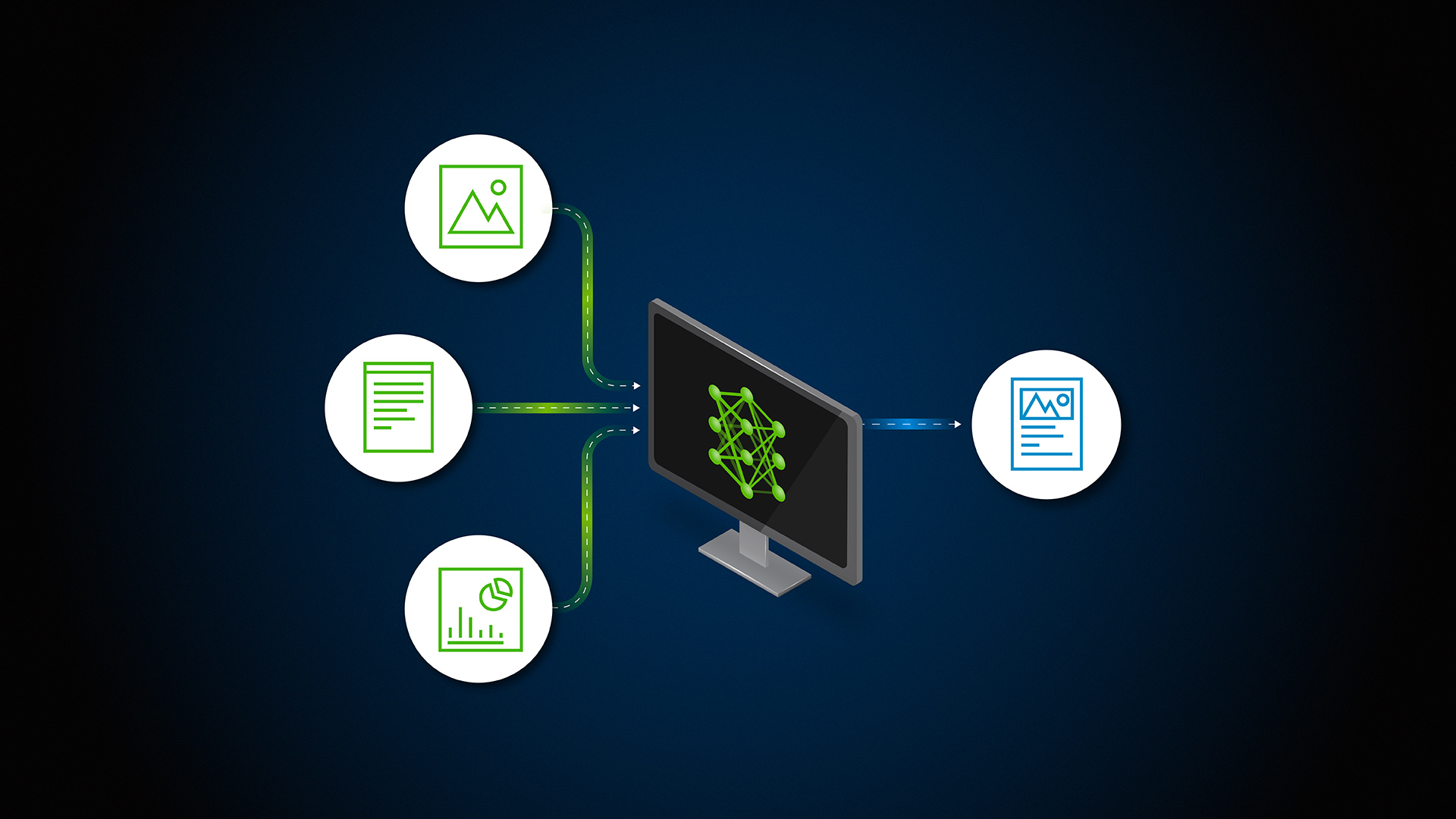
图1显示了部署RAG管道的基本构建块。
图1。 加速RAG应用程序的构建块 NVIDIA提供开源集成、GPU加速容器等,帮助开发您的RAG应用程序。
与流行框架和工具的开放源代码集成 NVIDIA提供了示例管道来帮助启动RAG应用程序开发。 NVIDIA RAG管道示例向开发人员展示了如何将流行的开源LLM编程框架(包括LangChain、LlamaIndex和Haystack)与NVIDIA加速软件相结合。 通过使用这些示例作为起点,企业开发人员可以享受这两个世界中最好的东西——将开源创新与加速的性能和规模相结合。
这些示例还演示了与流行的开源工具的集成,这些工具用于评估、管道可观察性和数据摄取,使两天的管道操作更容易、更具成本效益。
GPU加速容器,快速准确响应 LLM驱动的企业RAG应用程序必须具有响应能力和准确性。 基于CPU的系统无法在企业级提供可接受的性能。 这个 NVIDIA API目录 包括为RAG管道的每个阶段提供动力的容器,这些容器可从GPU加速中受益。
支持多模式输入、输出和数据处理 RAG应用程序正迅速从基于文本的聊天机器人发展到复杂的事件驱动工作流,涉及图像、音频和视频等多种形式。 NVIDIA AI软件增强了RAG管道的可用性和功能,以解决这些新出现的用例。
企业开发人员可以利用 NVIDIA AI企业 为生产部署这些AI软件组件。 NVIDIA AI Enterprise为企业级生成性AI应用程序提供了最快、最高效的运行时。
RAG应用程序从试运行到生产的四个步骤 构建生产RAG应用程序需要许多利益相关者之间的协作。
数据科学家评估LLM的性能和准确性。 企业AI开发人员编写、测试和改进RAG应用程序。 数据工程师连接和转换企业数据以进行索引和检索。 MLOp、DevOp和现场可靠性工程师(SRE)部署和维护生产系统。
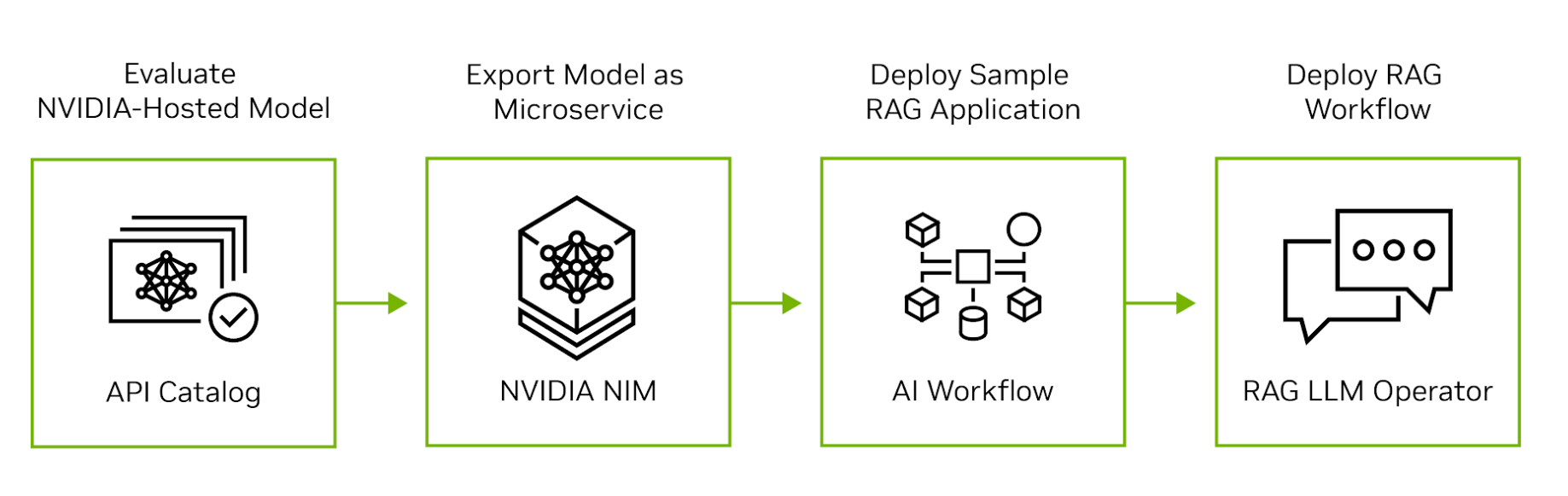
NVIDIA AI从云扩展到硅,以支持RAG应用程序开发、部署和操作的每个阶段。 图2显示了将RAG应用程序从评估转移到生产的四个步骤。
图2。 部署RAG应用程序的四个步骤 步骤1。 评估NVIDIA API目录中的LLM 首先访问 NVIDIA API目录 体验在NVIDIA GPU上运行的领先开源和商业模式。 开发人员可以通过用户界面与模型交互,然后查看由交互生成的后端API调用。 API调用可以导出为Python、Go或TypeScript代码段,也可以导出为shell脚本。
第2步。 将模型导出为微服务 接下来,将模型导出为NVIDIA NIM。 NIM是一种易于使用、自托管的微服务,旨在加速生成性AI的部署。该微服务可以作为容器在任何主要云上的虚拟机中运行,也可以通过Helm安装到Kubernetes集群中。 如果您担心数据隐私或安全,可以在自己的数据中心或虚拟私有云中评估模型。
步骤3。 开发RAG应用程序示例 评估自托管模型后,请探索 NVIDIA生成人工智能示例 编写示例RAG应用程序。 这些例子说明了NVIDIA微服务如何与流行的开源LLM编程框架集成,以产生端到端的RAG管道。 数据科学家可以使用这些示例调整应用程序的性能并评估其准确性。 NVIDIA AI Enterprise客户还可以访问NVIDIA AI工作流,该工作流演示了如何将生成性AI示例应用于特定行业的用例。
步骤4。 将RAG管道部署到生产 开发应用程序后,MLOps管理员可以使用NVIDIA RAG LLM操作员将其部署到测试或生产名称空间。 现在可用于 提前进入 RAG LLM操作员可以快速、轻松地将RAG应用程序部署到Kubernetes集群中,而无需重写任何应用程序代码。
RAG LLM操作员在 NVIDIA GPU操作员 是一种流行的基础设施软件,可自动在Kubernetes上部署和管理NVIDIA GPU。 它降低了生命周期管理的复杂性,并实现了RAG管道的无缝部署、扩展和管理。
提高生产力的生产RAG管道
生产RAG系统可以通过减少工作量、更容易找到相关数据以及自动化事件来提高工人的生产率。
NVIDIA使用RAG管道帮助构建安全的企业软件。 NVIDIA CVE分析工具结合了NVIDIA-NIM、NeMo Retriever和Morpheus网络安全AI框架,以识别和分类NGC容器中的常见漏洞和暴露(CVE)。 这一关键的业务流程确保了发布到NGC容器注册处的所有容器的完整性,现在需要数小时而不是数天。
视频1。 使用事件驱动检索增强生成应用程序在几秒钟内分析软件安全漏洞 包括Deepset、Sandia National Laboratories、Infosys、Quantiphi、Slalom和Wipro在内的组织正在通过NVIDIA生成性AI支持企业数据语义搜索来释放宝贵的见解。
Deepset与NVIDIA NIM和NeMo Retriever的全新Haystack 2.0集成 帮助组织有效检查GPU加速的LLM,以支持RAG应用程序的快速定型。
桑迪亚国家实验室(Sandia National Laboratories)和NVIDIA正在合作评估新兴的生成性人工智能工具,以最大限度地提高数据洞察力,同时提高准确性和性能。
Infosys扩大了与NVIDIA配对的战略合作 Infosys生成人工智能 ,属于 Infosys Topaz公司 与NVIDIA NeMo合作,为各个行业创建企业级RAG应用程序。 这些应用程序破坏了规范并为用例提供了价值,从自动化生物制药临床试验报告到从100000多个专有财务文档中发现见解。
Quantiphi整合了NVIDIA加速生成的人工智能,以开发基于RAG的解决方案,该解决方案可以从大量药物发现文档库中提取见解,并通过优化针对人口统计和地理位置定制的零售供应链,帮助实现突破性成果。
Slalom正在帮助组织驾驭生成性人工智能和RAG的复杂性,包括设计、实施和治理,以及一个强大的框架,以降低风险并确保负责任地应用人工智能
Wipro使用生成性人工智能工具,通过改善向美国数百万患者提供的服务,帮助医疗机构提高成果。
开始 企业越来越多地转向生成性人工智能,以解决复杂的业务挑战并提高员工生产力。 许多公司还将把生成性人工智能纳入其产品中。 企业可以依靠NVIDIA AI Enterprise提供的安全性、支持和稳定性,将其RAG应用程序从试验阶段转移到生产阶段。 而且,通过对NVIDIA AI进行标准化,企业可以获得一个坚定的合作伙伴,帮助他们跟上快速发展的LLM生态系统的步伐。
体验NVIDIA NeMo Retriever微服务,包括检索嵌入模型 API目录 。或者,探索 NVIDIA生成人工智能示例 开始构建一个聊天机器人,它可以使用最新信息用自然语言准确回答特定领域的问题。
要了解构建RAG应用程序的最新创新和最佳实践,请查看 检索增强的生成会话 从 NVIDIA GTC 2024年 .