CUDA图 可以显著提高性能,因为驱动程序能够使用任务和依赖项的完整描述来优化执行。 图形为静态工作流提供了难以置信的好处,在静态工作流中,图形创建的开销可以在多次连续启动中分摊。
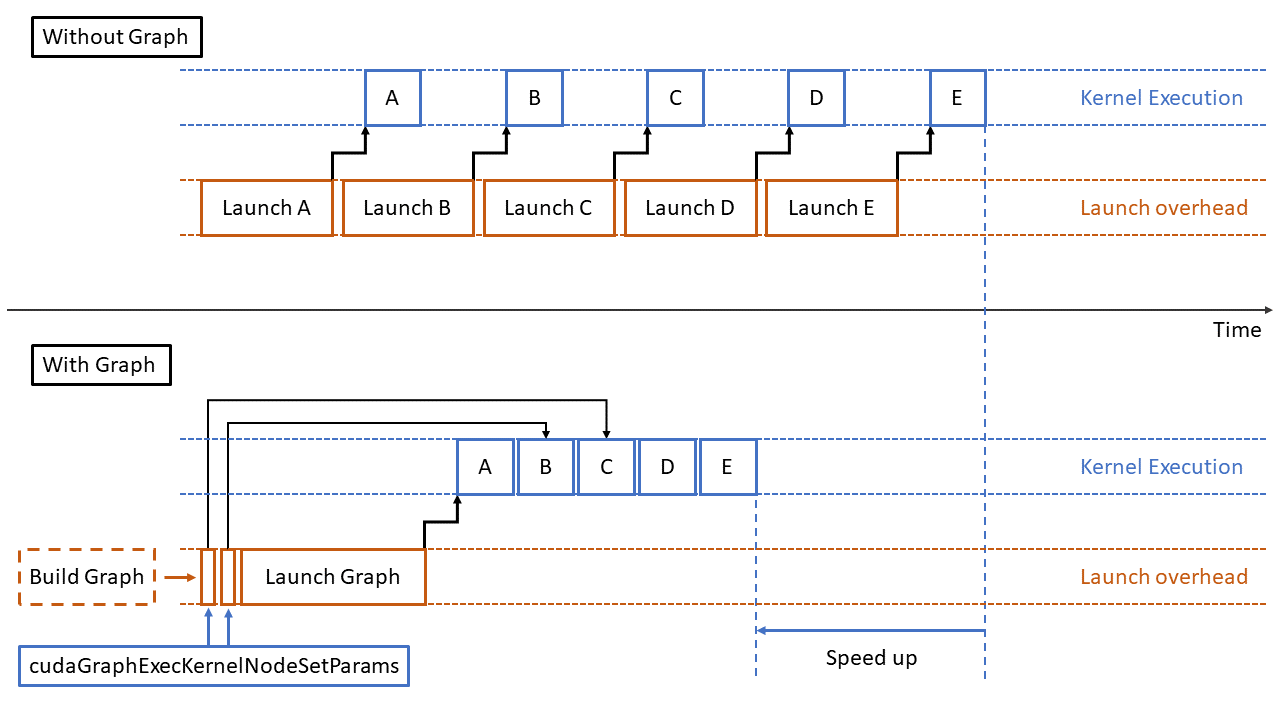
然而,几乎所有的问题都涉及某种形式的决策,这可能需要拆分图形并将控制权返回给CPU来决定下一步要启动的工作。 这样分解工作会影响CUDA的优化能力,占用CPU资源,并增加每次图形启动的开销。
从CUDA 12.4开始,CUDA Graphs支持 条件节点 ,它可以有条件地或重复地执行图形的某些部分,而无需将控制权返回给CPU。 这释放了CPU资源,允许在单个图形中表示更多工作流。
条件节点 条件节点有两种类型:
IF节点:如果条件值为true,则每次计算节点时都会执行一次主体。 WHILE节点:只要条件值为true,则在计算节点时重复执行主体。
条件节点是容器节点,类似于子图形节点,但节点中包含的图形的执行取决于条件变量的值。 与节点关联的条件值由必须在节点之前创建的句柄访问。 可以通过调用在CUDA内核中设置条件值 cuda图形设置条件 。也可以在创建句柄时指定在图形的每个开头应用的初始化。
创建条件节点时,还会创建一个空图,并将句柄返回给用户。 此图绑定到节点,并将根据条件值执行。 可以使用 图形应用程序接口 或使用捕获异步CUDA调用 cudaStream开始捕获到图形 .
条件节点也可以嵌套。 例如,可以使用包含条件IF节点的体图创建条件WHILE节点。
条件节点正文图可以包含以下任何内容:
内核节点(CNP,当前不支持协作) 空节点 子图节点 Memset节点 Memcopy节点 条件节点
这递归地应用于子图和条件体。 所有内核,包括嵌套条件或任何级别的子图中的内核,都必须属于同一CUDA上下文。 成员副本和成员集必须作用于条件节点上下文中可访问的内存。
完整的样本可在 CUDA样本库 。下一节将运行一些示例,展示如何使用条件节点。
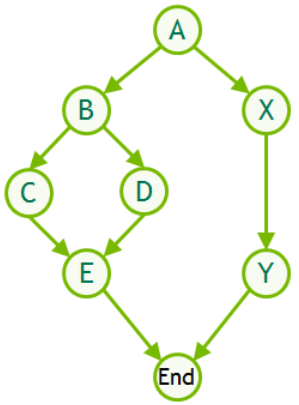
条件IF节点 当IF节点被求值时,如果条件为非零,则IF节点的体图将执行一次。 图1描述了一个图,其中中间节点B是包含四节点图的IF条件节点:
图1。 条件IF节点 为了演示如何创建此图,以下示例使用节点A(条件节点B的上游内核)根据该内核所做的工作的结果设置条件的值。 使用图形API填充条件体。
首先,定义节点A内核。 此内核根据用户执行的某些任意计算的结果设置条件句柄。
__global__void setHandle(cudaGraphConditionalHandle句柄) { 无符号int值=0; //我们可以在这里执行一些工作,并根据工作结果设置值。 if(someCondition){ //如果希望执行条件体,请将“value”设置为非零 值=1; } cudaGraphSetConditional(句柄,值); } 接下来,定义一个函数来构造图形。 此函数分配条件句柄,创建节点,并填充条件图的主体。 为了清楚起见,省略了启动和执行图形的代码。
cudaGraph_t创建图形(){ cudaGraph_t图; cudaGraphNode_t节点; void*kernelArgs[1]; cudaGraphCreate(&graph,0); cudaGraphConditionalHandle句柄; cudaGraphConditionalHandleCreate(&handle,graph); //使用条件的内核上游来设置句柄值 cudaGraphNodeParams kGrams={cudaGraph节点类型内核}; kParams.kernel.func=(void*)设置句柄; kParams.kernel.gridDim.x=kParams.kernel.gridDim.y=kParams.kernel.gridDim.z=1; kParams.kernel.blockDim.x=kParams.kernel.blockDim.y=kPagrams.kernel/blockDim.z=1; kParams.kernel.kernelParams=kernelArgs; kernelArgs[0]=&handle; cudaGraphAddNode(&node,graph,NULL,0,&kParams); cudaGraphNodeParams cParams={cudaGraph节点类型条件}; cParams.conditional.handle=句柄; cParams.conditional.type=cudaGraphCondTypeIf; cParams.conditional.size=1; cudaGraphAddNode(&node、graph、&node,1,&cParams); cudaGraph_t bodyGraph=cParams.conditional.phGraph_out[0]; //填充条件节点的主体 cudaGraphNode_t主体节点[4]; cudaGraphNodeParams参数[4]={…};// 根据需要设置内核参数。 cudaGraphAddNode(&bodyNodes[0],bodyGraph,NULL,0,¶ms[0]); cudaGraphAddNode(&bodyNodes[1]、bodyGraph和bodyNodes[0]、1、¶ms[1]); cudaGraphAddNode(&bodyNodes[2]、bodyGraph和bodyNodes[0]、1、¶ms[2]); cudaGraphAddNode(&bodyNodes[3]、bodyGraph和bodyNodes[1]、2、¶ms[3]); 返回图; } 条件WHILE节点 只要条件不为零,WHILE节点的体图就会重复执行。 在执行节点时以及每次完成体图后,都将评估条件。 下图描述了一个三节点图,其中中间节点B是一个包含三节点图的WHILE条件节点。
图2。 条件WHILE节点
为了查看如何创建此图,下面的示例将句柄的默认值设置为非零值,以便在默认情况下执行WHILE循环。 将默认值设置为非零,并将条件值保留在条件上游的内核中,这样可以有效地生成do-while循环,其中条件体始终至少执行一次。 创建WHILE循环(其中循环体仅在条件为true时执行)需要执行一些计算并在节点a中适当设置条件句柄。
在前面的示例中,条件体使用图形API填充。 在本例中,使用流捕获填充条件体。
第一步是定义一个内核,该内核在条件体的每次执行期间设置条件值。 在本例中,句柄是基于向下计数器的值设置的。
__global__void loopKernel(cudaGraphConditionalHandle句柄) { 静态int计数=10; cudaGraphSetConditional(句柄,--count?1:0); } 接下来,定义一个函数来构造图形。 此函数分配条件句柄,创建节点,并填充条件图的主体。 为了清楚起见,省略了启动和执行图形的代码。
cudaGraph_t创建图形(){ cudaGraph_t图; cudaGraphNode_t节点[3]; cudaGraphCreate(&graph,0); //插入内核节点A cudaGraphNodeParams参数=。。。; cudaGraphAddNode(&nodes[0],graph,NULL,0,¶ms); cudaGraphConditionalHandle句柄; cudaGraphConditionalHandleCreate(&handle,graph,1,cudaGraph CondAssignDefault); //插入条件节点B cudaGraphNodeParams cParams={cudaGraph节点类型条件}; cParams.conditional.handle=句柄; cParams.conditional.type=cudaGraphCondTypeWhile; cParams.conditional.size=1; cudaGraphAddNode(&nodes[1]、graph、&nodes[0]、1、&cParams); cudaGraph_t bodyGraph=cParams.conditional.phGraph_out[0]; cudaStream_t captureStream; cudaStreamCreate(&captureStream); //用流捕获填写身体图。 cudaStreamBeginCaptureToGraph(捕获流, bodyGraph、, 空指针, 空指针, 0, cudaStreamCaptureModeRelaxed); myKernel1<<<。。。, captureStream>>>(…); myKernel2<<<。。。, captureStream>>>(…); loopKernel<<<1,1,0,captureStream>>>(句柄); cudaStreamEndCapture(captureStream,nullptr); cudaStreamDestroy(captureStream); //插入内核节点C。 参数=。。。; cudaGraphAddNode(&nodes[2],graph,&nodes[1],1,¶ms); 返回图; } 此示例使用 cudaStreamBeginCaptureToGraph ,CUDA 12.3中添加了一个新的API,使流捕获能够将节点插入到现有的图中。 使用此API,可以将多个单独的捕获组合到单个图形对象中。 此API还支持填充条件体图对象,该对象与条件节点一起创建。
结论 CUDA图形为静态工作流提供了难以置信的好处,在静态工作流中,图形创建的开销可以在多次连续启动中摊销。 消除拆分图并将控制权返回给CPU以决定优先启动有助于减少CPU开销和延迟。 将CUDA图与条件节点一起使用,可以有条件地或重复地执行图的某些部分,而无需将控制权返回给CPU。 这释放了CPU资源,并使单个图形能够表示更复杂的工作流。
有关条件节点的详细信息,请参阅 CUDA编程指南 。要探索简单完整的示例,请访问 NVIDIA/cuda-样品 在GitHub上。 并加入到 NVIDIA开发者CUDA论坛 .