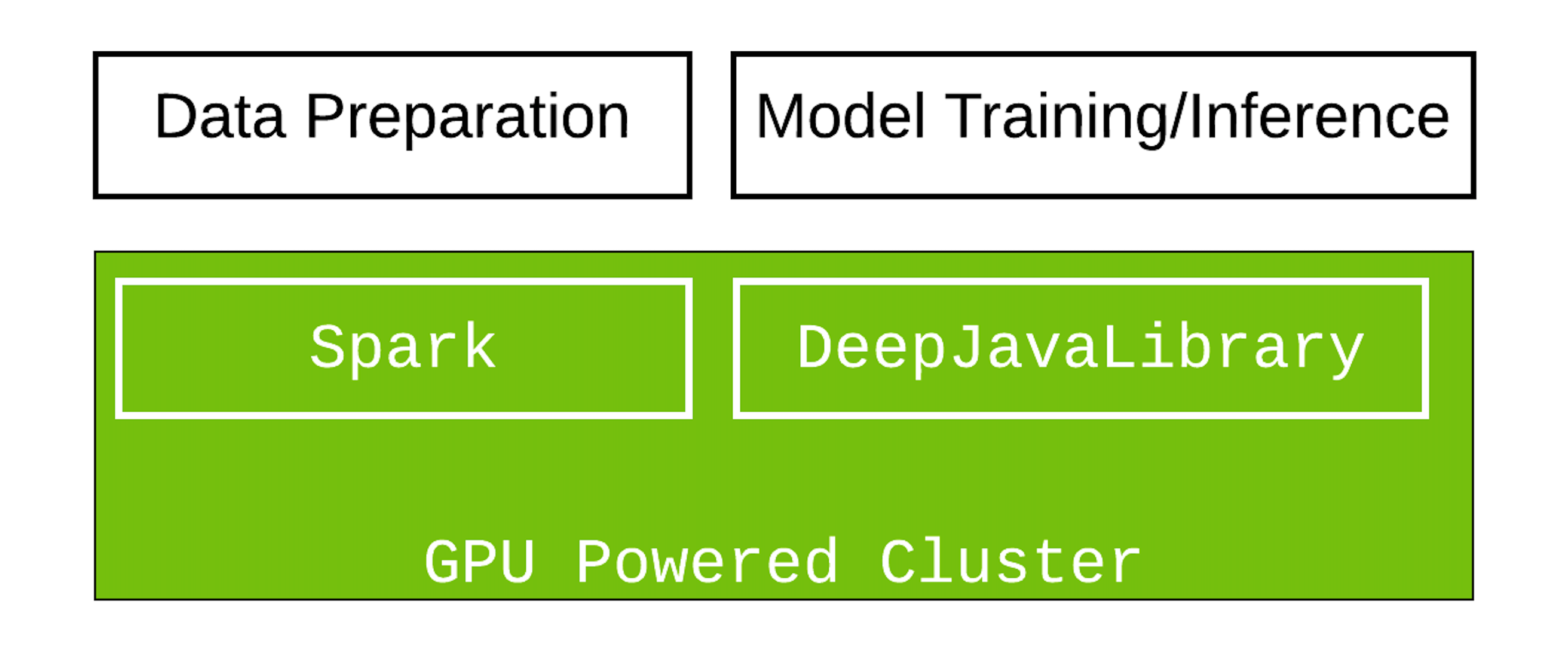
阿帕奇火花是针对大规模数据的分布式提取、转换和加载(ETL)工作负载的业界领先平台。然而,随着深度学习(DL),许多Spark从业者试图在销售预测、内容建议、情绪分析和欺诈检测等各种用例的数据处理管道中添加DL模型。
然而,结合DL培训和推理对于Spark用户来说,使用大规模数据一直是一个挑战。大多数DL框架都是为单节点环境设计的,它们的分布式训练和推理API通常是作为事后考虑添加的。
为了帮助解决单节点DL环境和大规模分布式环境之间的这种脱节,有多种第三方解决方案,例如Horovod-on-Sark公司,Tensor火花流量、和火花炬但是,由于这些解决方案不是在Spark中内置的,用户必须根据自己的需要评估每个平台。
随着火花3.4,用户现在可以访问用于分布式模型训练和大规模模型推理的内置API,详情如下。
分布式培训
对于分布式培训,有一个新的火炬分配器PyTorch的API,遵循火花张量流量分配器TensorFlow的API。通过利用Spark的屏障执行模式在Spark执行器之上生成分布式DL集群节点,这些简化了分布式DL模型训练代码到Spark中的迁移。
一旦Spark启动了DL集群,控制权就通过主fn传递给了火炬分配器应用程序编程接口。
如以下代码所示,使用此新API在Spark上运行标准的分布式DL培训只需进行最小的代码更改。
来自pyspark.ml.torc.distributor导入TorchDistributor定义main_fn(检查点目录):#标准分布式PyTorch代码...#设置num_process=num_WORKERS*num_GPUS_PER_WORKIRoutput_dist=火炬分配器(num_processes=2,local_mode=False,use_gpu=True).run(main_fn,checkpoint_dir)
一旦启动,运行在执行器上的进程就依赖于其各自DL框架的内置分布式训练API。将现有的分布式训练代码移植到Spark应该只需要很少或根本不需要修改。然后,这些进程可以在训练期间相互通信,也可以直接访问与Spark集群关联的分布式文件系统(图1)。
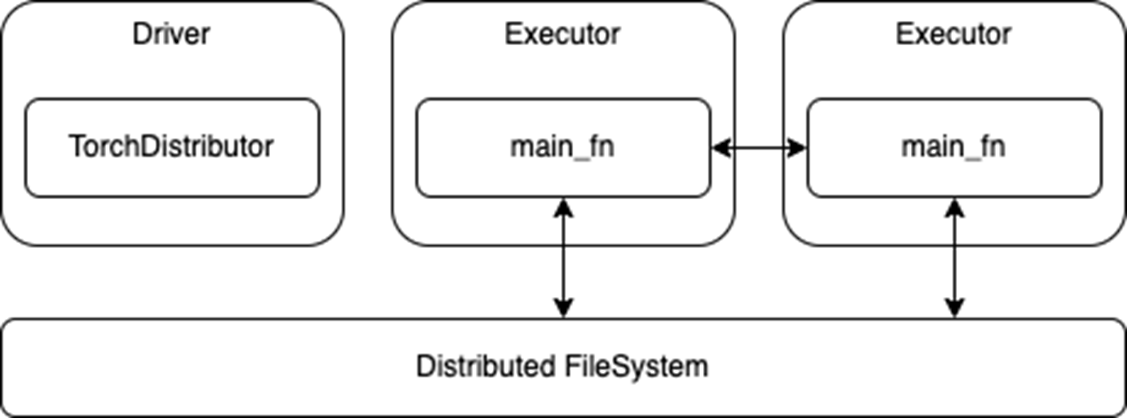 图1。分布式培训使用
图1。分布式培训使用火炬分配器美国石油学会
然而,这种易于迁移的特性也意味着这些API不使用Spark RDD或DataFrames进行数据传输。虽然这样就不需要在Spark和DL框架之间转换或序列化数据,但它还要求在启动培训工作之前完成任何Spark预处理并保存到存储中。可能还需要调整主要培训功能,以便从分布式文件系统而不是本地存储中读取。
分布式推理
对于分布式推理,有一个新的预测_匹配_udfAPI,它构建在Spark Pandas自定义项以提供用于DL模型推断的更简单的接口。与基于行的UDF相比,Pandas UDF具有几个优点,包括通过阿帕奇箭头并通过以下方式加快矢量化操作熊猫。有关详细信息,请参阅为PySpark引入Pandas UDF.
然而,尽管Pandas UDF API可能是ETL用例的一个很好的解决方案,但它仍然不适合DL推理用例。首先,Pandas UDF API将数据表示为Pandas Series或DataFrame,这同样适用于执行ETL操作,如选择、排序、数学转换和聚合。
然而,大多数DL框架都希望数字Py数组或标准Python数组作为输入,这些数组通常由自定义Tensor变量包装。因此,Pandas UDF实现至少需要将传入的Pandas数据转换为NumPy数组。不幸的是,根据用例和数据集的不同,精确的翻译可能会有很大差异。
接下来,Pandas UDF API通常在数据分区上运行,数据分区的大小由数据集的原始写入者或分布式文件系统决定。因此,很难对传入数据进行适当的批处理以进行优化计算。
最后,仍然存在跨Spark执行器和任务加载DL模型的问题。在正常的Spark ETL作业中,工作负载遵循函数编程范式,其中可以对数据应用无状态函数。然而,对于DL推理,预测函数通常需要从磁盘加载其DL模型权重。
Spark能够通过任务序列化和广播变量将变量从驱动程序序列化到执行器。然而,它们都依赖于Python pickle序列化,这可能并不适用于所有DL模型。此外,如果操作不当,加载和序列化非常大的模型可能会对性能造成极大的代价。
解决当前限制
为了解决这些问题预测_匹配_udf引入标准化代码:
- 将Spark DataFrames转换为NumPy数组,因此最终用户DL推断代码不需要从Pandas DataFrame转换。
- 为DL框架批处理传入的NumPy数组。
- 在执行器上加载模型,避免了任何模型序列化问题,同时利用Spark
spark.python.worker.reuse公司配置以在Spark执行器中缓存模型。
下面的代码演示了这个新API如何隐藏将DL推理代码转换为Spark的复杂性生成预测函数,使用标准DL API加载模型并返回预测功能。然后预测_匹配_udf函数生成标准潘达斯UDF负责幕后的一切。
从pyspark.ml.functions导入predict_batch_udf定义make_predict_fn():#从检查点加载模型进口焊炬设备=火炬设备(“cuda”)model=网络().到(设备)检查点=load_checkpoint(checkpoint_dir)model.load_state_dict(检查点[“model”])#用numpy数组定义预测函数定义预测(输入:np.narray)->np.ndarray:torch_inputs=火炬.from_numby(输入).to(设备)输出=模型(火炬输入)返回outputs.cpu().detach().numpy()收益预测#从预测函数创建标准PandasUDFmnist=预测batch_udf(make_predict_fn,输入传感器形状=[[1,28,28]],return_type=数组类型(FloatType()),批大小=1000)df=spark.read.parquet(“/path/to/test/data”)preds=df.withColumn(“preds”,mnist('data')).collect()
请注意,此API使用标准Spark DataFrame进行推断,因此执行器将从分布式文件系统读取数据并将该数据传递给预测功能(图2)。这也意味着,任何数据处理都可以根据需要与模型预测一起进行。
还要注意,这是一个数据并行体系结构,其中每个执行器加载模型并对数据集的各自部分进行预测,因此模型必须适合执行器内存。
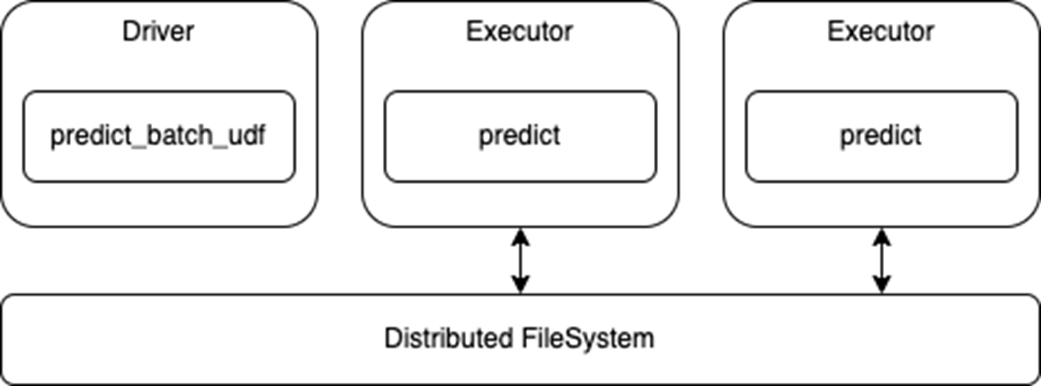 图2。分布式推理使用
图2。分布式推理使用预测_匹配_udf美国石油学会
Spark深度学习的端到端示例
要尝试这些新API,请查看Spark DL训练和推理笔记本作为一个端到端的示例。基于基于Databricks笔记本的分布式培训E2E从Databricks中,示例笔记本演示了:
- 如何使用新的
火炬分配器应用程序编程接口。
- 如何使用新的
预测_匹配_udf用于分布式推理的API。
- 如何使用NVTabular从分布式文件存储(如S3)加载训练数据。
关于深度学习推理集成的更多信息
如果您正在使用常见的DL框架,如Hugging Face、PyTorch和TensorFlow,请查看外部框架笔记本示例这些示例演示了使用新预测_匹配_udfAPI及其广泛适用性。
在2023年数据+人工智能峰会上进一步了解该API,Apache Spark上用于深度学习推理的API.