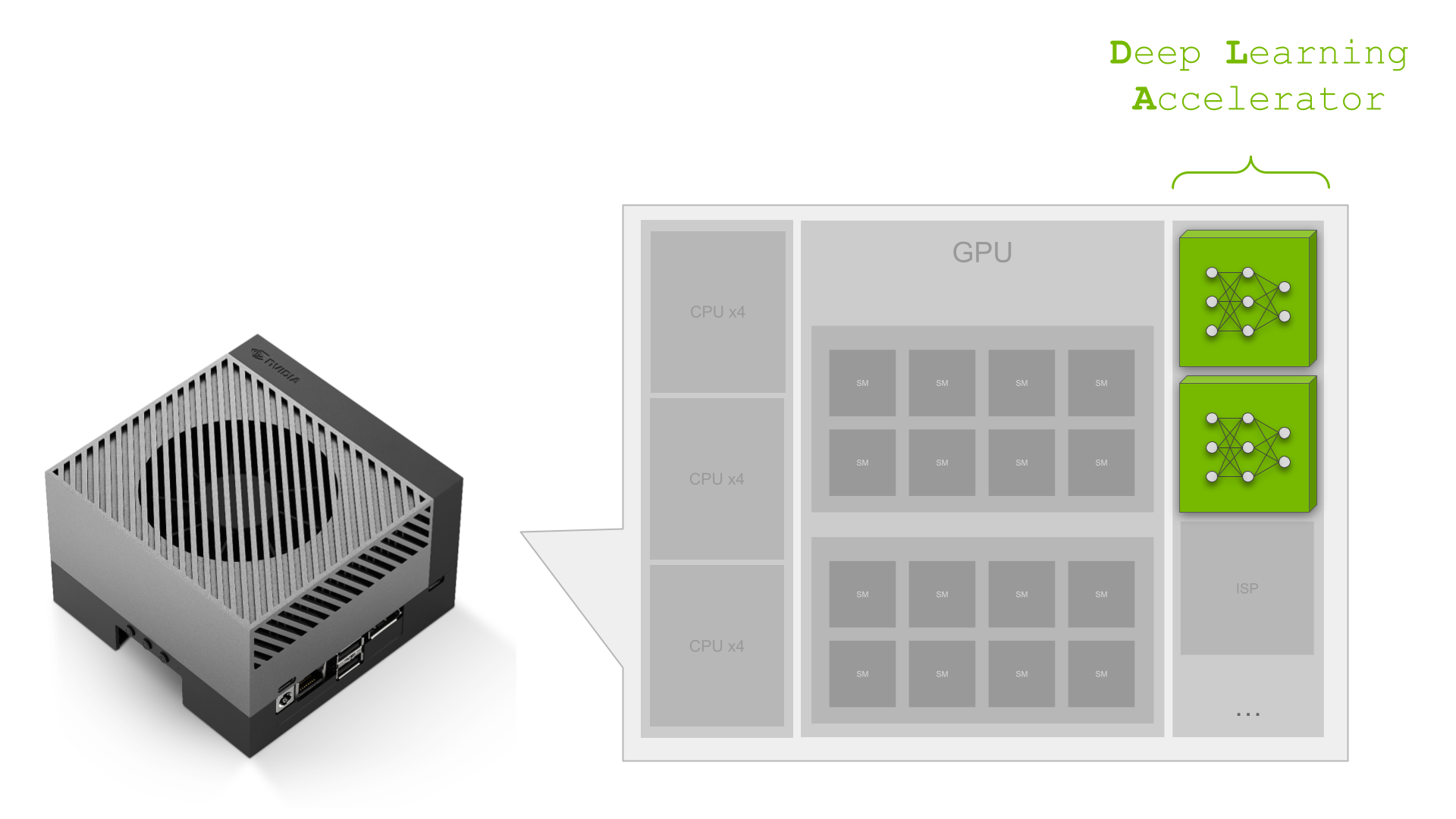
NVIDIA Jetson Orin公司 是用于AI工作负载的最佳嵌入式平台。 Orin平台的关键组件之一是第二代 深度学习加速器(DLA) 是专门的深度学习推理引擎,在AGX Orin平台上提供三分之一的AI计算。
本文深入探讨了使用Orin平台的嵌入式开发人员如何使用 YOLOv5公司 作为参考。 要了解有关DLA如何帮助最大化深度学习应用程序性能的更多信息,请参阅 利用DLA最大化NVIDIA Jetson Orin的深度学习性能 .
YOLOv5公司 是一种物体检测算法。 在v3和v4成功的基础上,YOLOv5旨在提高实时目标检测任务的准确性和速度。 YOLOv5因其在准确性和速度之间的出色权衡而臭名昭著,成为计算机视觉领域研究人员和实践者的热门选择。 它的开源实现使开发人员能够利用预处理模型,并根据特定目标对其进行定制。
以下部分将介绍 端到端YOLOv5 cuDLA样本 它向您展示了如何:
使用Quantization-Aware Training(QAT)训练YOLOv5模型,并将其导出以在DLA上部署。 通过TensorRT和cuDLA部署网络并使用CUDA进行推理。 执行目标YOLOv5精度验证和性能分析。
使用此示例,我们演示了如何使用DLA INT8在COCO数据集上实现37.3 mAP(官方FP32 mAP为37.4)。 我们还展示了如何在单个NVIDIA Jetson Orin DLA上获得超过400 FPS的YOLOv5。 (Orin上共有两个DLA实例可用。)
DLA的QAT培训和导出 为了平衡YOLOv5的推理性能和准确性,有必要在模型上应用量化软件训练(QAT)。 由于DLA在编写时不支持通过TensorRT进行QAT,因此有必要在推理之前将QAT模型转换为训练后量化(PTQ)模型。 这些步骤如图1所示。
图1。 将QAT模型转换为PTQ模型的关键步骤 QAT培训工作流程 使用 TensorRT pytorch量化 用于量化YOLOv5的工具包。 第一步是将量化器模块添加到神经网络图中。 此工具包提供 一组量化层模块 用于常见的DL操作。 如果模块不在提供的量化模块中,则可以在模型中的正确位置创建自定义量化模块。
第二步是校准模型,获得每个量化/去量化(Q/DQ)模块的标度值。 校准完成后,选择训练计划并使用COCO数据集微调校准模型。
图2。 QAT培训工作流程的步骤 添加Q/DQ节点 将Q/DQ节点添加到网络中有两个选项:
选项1: 根据建议将Q/DQ节点放置在 Q/DQ网络的张量RT处理 该方法遵循用于Q/DQ层的TensorRT融合策略。 这些TensorRT策略主要针对GPU推理进行调整。 要使其与DLA兼容,请添加额外的Q/DQ节点,这些节点可以使用来自相邻层的刻度派生 Q/DQ转换器 .
任何缺失的刻度都会导致某些层在FP16中运行。 这可能会导致mAP略有下降,并可能导致性能大幅下降。 Orin DLA针对INT8卷积进行了优化,约为FP16密集性能的15倍(或在比较密集FP16和INT8稀疏性能时为30倍)。
选项2: 在每一层插入Q/DQ节点,以确保所有张量具有INT8尺度。 使用此选项,可以在模型微调期间获得所有层的比例。 然而,当在GPU上运行推理时,此方法可能会破坏带有Q/DQ层的TensorRT融合策略,并导致GPU上的延迟更高。 另一方面,对于DLA来说,PTQ尺度的经验法则是:“可用尺度越多,延迟越低。”
实验证实,我们的YOLOv5模型在COCO 2017验证数据集上进行了验证,分辨率为672 x 672像素。 选项1和选项2的mAP得分分别为37.1和37.0
根据您的需要选择最佳选项。 如果您已经有一个用于GPU的QAT工作流,并且希望尽可能地保留它,那么选项1可能更好。 (您可能需要扩展Q/DQ转换器,以推断出更多缺失的刻度,从而实现最佳的DLA延迟。)
另一方面,如果您正在寻找将Q/DQ节点插入所有层并与DLA兼容的QAT培训方法,那么选项2可能是最有希望的。
Q/DQ转换器工作流 Q/DQ转换器的目的是将经过QAT训练的ONNX图转换为PTQ张量尺度和无Q/DQ节点的ONNX模型。
对于这个YOLOv5模型,从QAT模型中的Q/DQ节点提取量化尺度。 使用相邻层的信息推断其他层的输入/输出比例,例如YOLOv5的SiLU或Concat节点中的Sigmoid和Mul。 提取刻度后,导出不带Q/DQ节点的ONNX模型和(PTQ)校准缓存文件,以便TensorRT可以使用它们构建DLA引擎。
将网络部署到DLA进行推理 下一步是部署网络,并通过TensorRT和cuDLA使用CUDA进行推理。
使用TensorRT的可加载构建 使用TensorRT构建可加载的DLA。 这为DLA可加载构建提供了易于使用的界面,并在需要时与GPU无缝集成。 有关TensorRT-DLA的更多信息,请参阅 与DLA合作 在《TensorRT开发人员指南》中。
trtexec公司 是TensorRT提供的一个方便的工具,用于构建引擎和测试性能。 请注意,DLA可加载是通过DLA编译器成功编译DLA的结果,TensorRT可以在序列化引擎中打包DLA可装载。
首先,准备ONNX模型和上一节中生成的校准缓存。 可加载的DLA可以用单个命令构建。 通过 --安全的,安全的 选项,整个模型可以在DLA上运行。 这直接将编译结果保存为可加载的序列化DLA(没有TensorRT引擎)。 有关此步骤的更多详细信息,请参阅 NVIDIA深度学习TensorRT文档 .
trtexec--onnx=model.onnx--useDLACore=0--safe--saveEngine=model.loadable--inputIOFormats=int8:dla_hwc4--outputIOFormats=fp16:chw16--int8--fp16--calib=qat2ptq.cache 注意,输入格式 dla_hwc4 如果您的模型输入合格,则从性能角度强烈建议使用。 输入最多必须有 四个输入通道并被卷积消耗 。在INT8中,DLA可以从特定的硬件和软件优化中获益,如果您使用 --输入IO格式=int8:chw32 相反,例如。
使用cuDLA进行推理 古巴 是DLA的CUDA运行时接口,是CUDA编程模型的扩展,它集成了DLA和CUDA。 cuDLA允许您使用CUDA编程结构提交DLA任务。 您可以使用cuDLA通过TensorRT运行时隐式运行推断,也可以显式调用cuDLA API。 此示例演示了显式调用cuDLA API以在中运行推断的后一种方法 混合模式 和 单机模式 .
cuDLA混合模式和独立模式主要在同步方面有所不同。 在混合模式下,DLA任务被提交到CUDA流,因此可以与其他CUDA任务无缝同步。
在独立模式下 cudla任务 该结构规定了cuDLA必须等待和分别发出信号的等待和信号事件,作为 cudla提交任务 .
简而言之,使用cuDLA混合模式可以快速集成其他CUDA任务。 使用cuDLA独立模式可以防止创建CUDA上下文,因此如果管道没有CUDA上下文则可以节省资源。
本YOLOv5示例中使用的主要cuDLA API如下所示。
目标验证和分析 重要的是要注意GPU和DLA之间的数字差异。 底层硬件不同,因此计算不精确。 因为网络培训是在GPU上完成的,然后部署到目标上的DLA,所以在目标上进行验证非常重要。 当涉及到量化时,这一点尤其重要。 与参考基线进行比较也很重要。
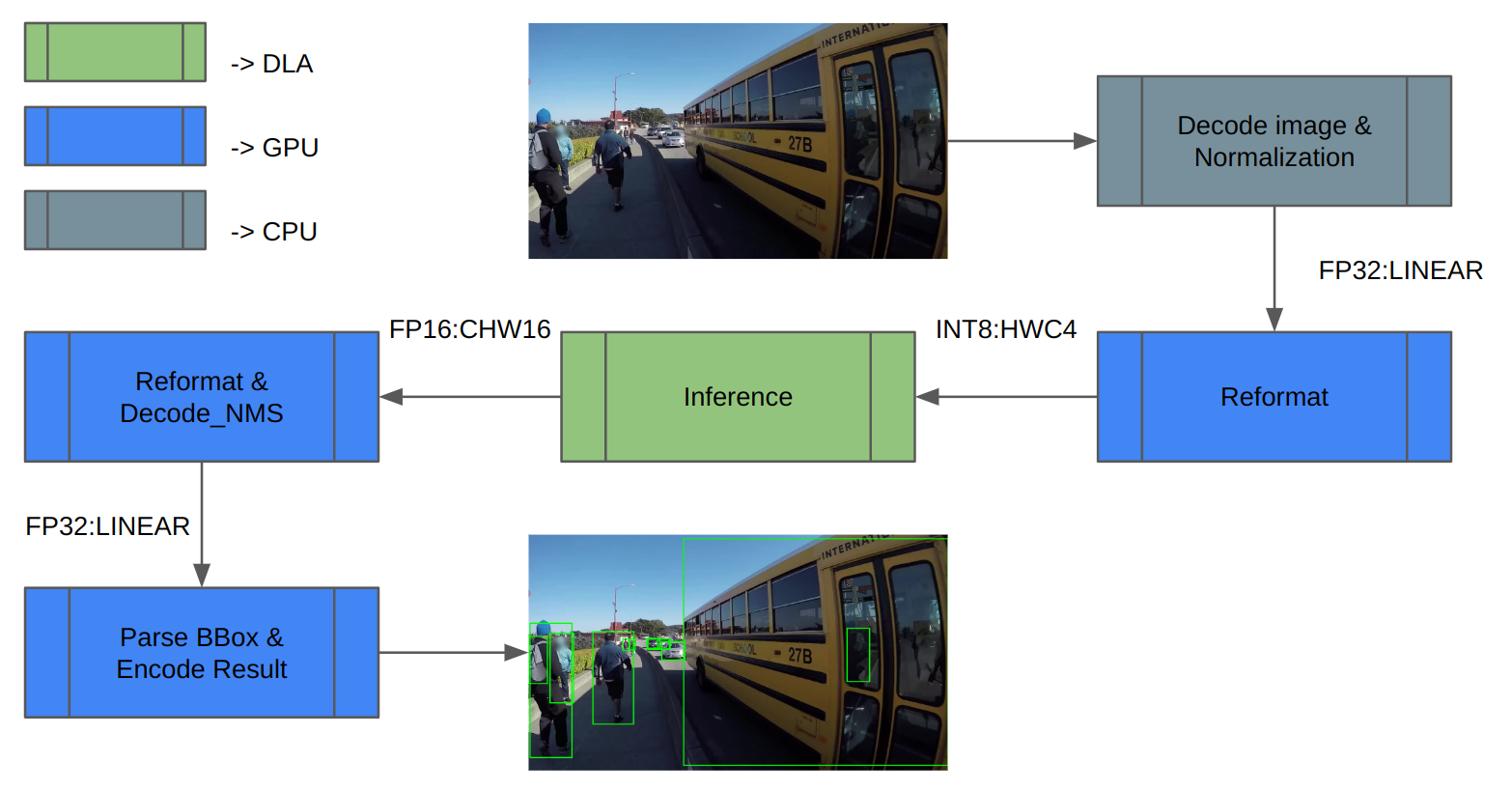
YOLOv5 DLA准确性验证 我们使用COCO数据集进行验证。 图3显示了推理管道体系结构。 首先,加载图像数据并将其规范化。由于DLA仅支持INT8/FP16,因此需要对推断输入和输出进行额外的重新格式化
推理完成后,对推理结果进行解码并执行NMS(非最大值抑制)以获得检测结果。 最后,保存结果并计算mAP。
图3。 包含映射到不同计算引擎的任务的推断管道
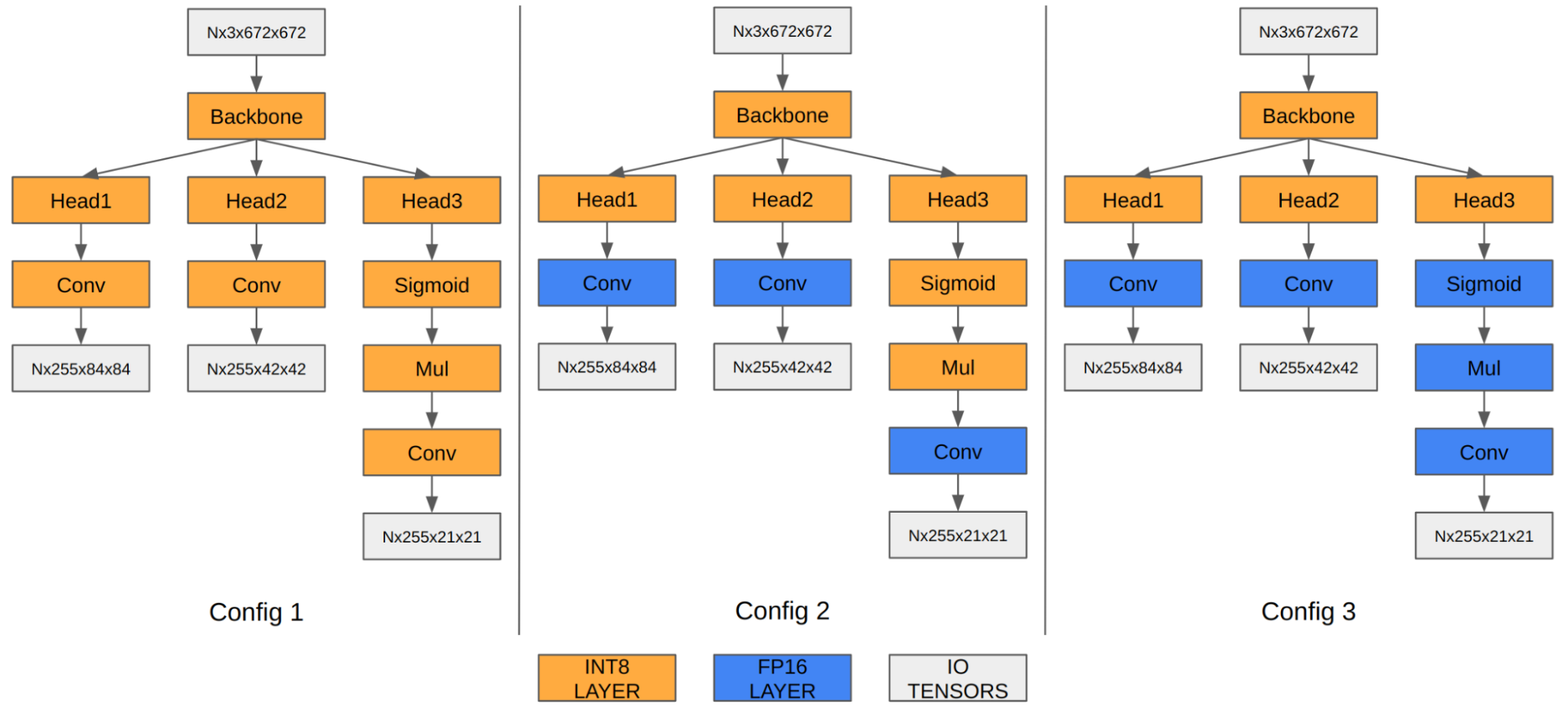
在YOLOv5的情况下,最后三个卷积层的特征映射编码最终检测信息。 当量化到INT8时,与FP16/FP32相比,边界框坐标的量化误差变得明显,从而影响最终的mAP。
我们的实验表明,在FP16中运行最后三个卷积层可以将最终的mAP从35.9提高到37.1。 Orin DLA有一个针对INT8进行了高度优化的特殊硬件设计,因此当这三个卷积在FP16中运行时,我们观察到性能下降。
图4。 不同精度配置的YOLOv5发动机 配置1 配置2 配置3 输入张量格式 内景8:DLA_HWC4 内部8:DLA_HWC4 内景8:DLA_HWC4 输出张量格式 内景8:CHW32 FP16:CHW16 FP16:CHW16 COCO值mAP 35.9 37.1 37.3 FPS(DLA 3.14.0,1x DLA@1.33 GHz,EMC@3.2 GHz) 410 255 252
表1。 探索最后三个卷积层混合精度的配置 请注意,mAP结果基于前面关于添加Q/DQ节点的部分中描述的选项1。 您也可以对选项2应用相同的原则。
得益于两个DLA内核,DLA在Orin AGX平台上提供了三分之一的AI计算。 有关Orin DLA性能的一般基准,请参阅 深度学习加速器-SW 在GitHub上。
在最新版本DLA 3.14.0(DOS 6.0.8.0和JetPack 6.0)中,DLA编译器添加了一些性能优化,专门适用于基于INT8 CNN体系结构的模型:
原生INT8 Sigmoid(之前在FP16中运行,必须在INT8中进行转换;也适用于Tanh) INT8 SiLU融合为单个DLA硬件操作(而不是独立的Sigmoid加上独立的元素级Mul) 将INT8 SiLU硬件操作与先前的INT8 Conv硬件操作融合(也适用于独立的Sigmoid或Tanh)
与以前的版本相比,这些改进可以为YOLO架构提供6倍的加速。 例如,在YOLOv5的情况下,INT8中的推理性能从13毫秒跳到2.4毫秒(FP16中运行了几个层),这是5.4倍的改进。 此外,您可以使用 cuDLA样品 以分层分析DNN,确定瓶颈,并修改网络以提高其性能。
DLA入门 这篇文章解释了如何在Orin的专用深度学习加速器上使用YOLOv5以最有效的方式运行整个对象检测管道。 请记住,其他SoC组件(如GPU)要么在怠速运行,要么在很小的负载下运行。 如果您有一个摄像头以每秒30帧的速度生成输入,那么一个DLA实例将仅以大约10%的速度加载。 因此,有足够的空间为您的应用程序添加更多的功能。
准备好潜水了吗? YOLOv5示例复制了这里讨论的整个工作流。 您可以将其用作您自己的用例的参考点。
对于初学者 Jetson_dla_tutorial喷气发动机 在GitHub上演示了一个基本的DLA工作流,以帮助您开始部署一个简单的模型 DLA公司 .
有关利用DLA实现最大价值的其他示例和资源 NVIDIA大道 或NVIDIA Jetson,访问 深度学习加速器-SW 在GitHub上。 有关cuDLA的更多信息,请访问 深度学习加速器软件/samples/cuDLA .