在快速发展的软件开发领域,聊天机器人和 GitHub Copilot公司 极大地改变了开发人员编写和管理代码的方式。 这些工具基于 大型语言模型 (LLM),通过自动化常规编码任务来提高生产力。
并行计算挑战 然而,使用LLM生成并行计算代码对于 高性能计算 (HPC)应用程序遇到了挑战。 并行计算应用程序需要对函数编程的逻辑和管理多个并发操作所涉及的复杂性(例如避免死锁和竞争条件)有细致的理解。 传统的人工智能模型可以有效地生成串行代码,但由于这些额外的复杂性,并行结构会使其步履蹒跚。
NVIDIA在生成复杂代码方面也面临着类似的挑战,但在支持新加速计算半导体设计的背景下。 解决此问题的相关工作非常重要, ChipNeMo芯片 在2023年超级计算期间发布 域自适应预培训 (DAPT)和 检索增强生成 (RAG)技术成功地为工程师制作了EDA联合试验。 DAPT与先进RAG技术的结合很好地解决了Sandia科学家面临的问题,并启动了以下合作。
一组科学家 桑迪亚国家实验室 开始了一个雄心勃勃的项目 NVIDIA NeMo公司 软件产品,例如早期访问nSolve-40K(嵌入模型),以解决这些挑战。 他们为 科科斯 是一个C++库,它为您提供了编写性能可移植应用程序的工具。 它抽象了硬件复杂性,并使代码能够在不同类型的HPC体系结构上高效运行。
为此类特定任务创建AI模型通常需要使用特定领域的知识对基础模型进行微调,这是一个资源密集且耗时的过程。 为了保持软件更新和错误修复的敏捷性,HPC开发人员通常喜欢更灵活的方法。
该助手旨在利用AI的最新进展,为您提供准确的上下文软件代码建议,从而为您提供支持。
实施高级RAG Sandia正在与NVIDIA合作开发一种先进的RAG方法,以实现模块化工作流程,该工作流程可适应正在进行的数据集更改,并在最先进的模型发布后立即将其与HPC工作负载集成。
根据 Robert Hoekstra,博士,桑迪亚极限规模计算高级经理, o个 包括Sandia在内的多个行业的组织正在利用NVIDIA生成性AI挖掘有价值的见解,实现企业数据的语义搜索。 Sandia和NVIDIA正在合作评估新兴的生成性人工智能工具,以最大限度地提高数据洞察力,同时提高准确性和性能。
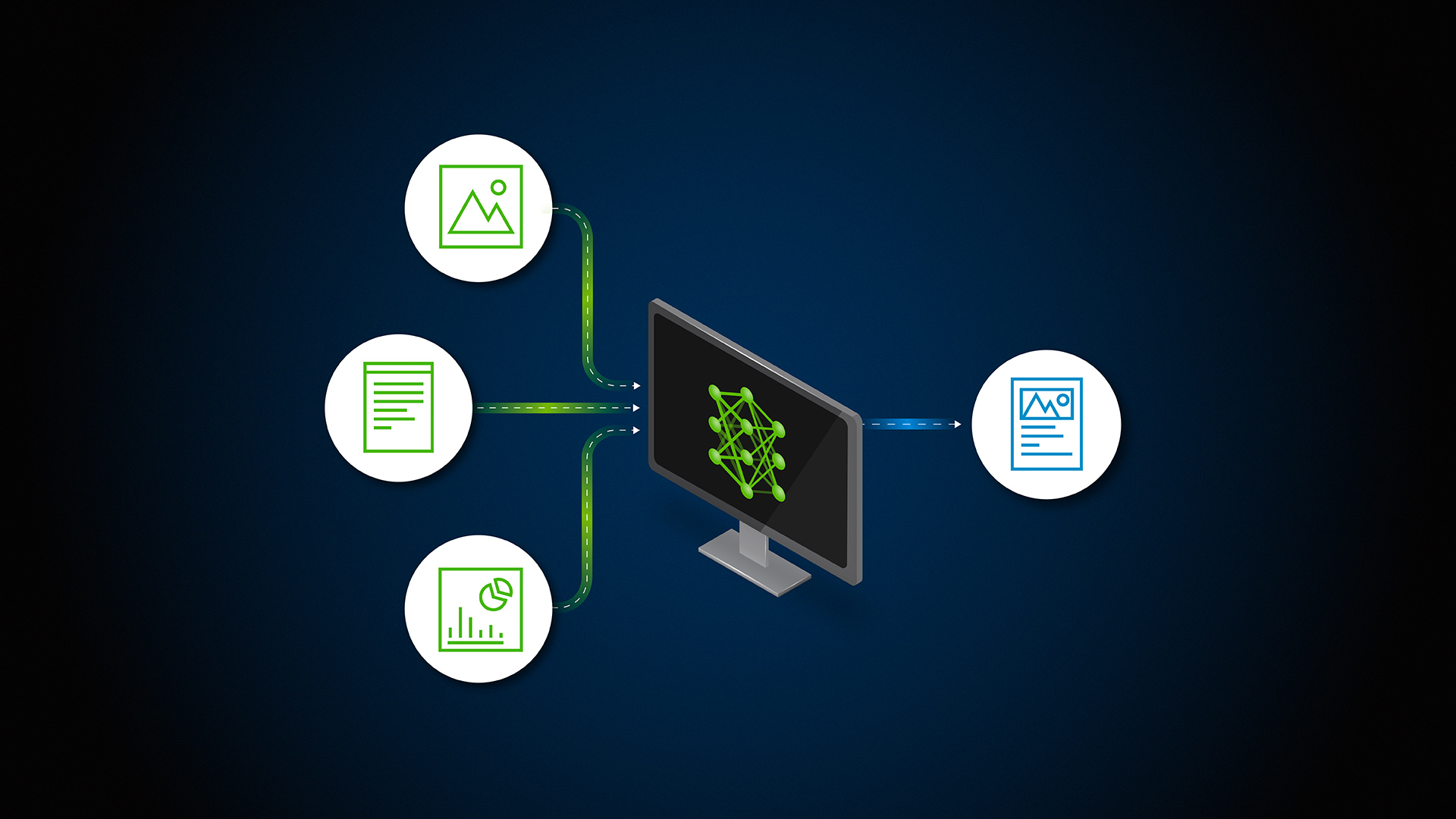
通过编译使用 科科斯 Sandia的科学家创建了一个动态且不断更新的数据集。 使用递归文本拆分器进行C编程,可以将数据集组织为可管理的块。 然后,这些数据集块被转换为向量嵌入并存储在数据库中,从而产生比微调更少的资源密集型过程。
当进行查询时,它被转换为一个向量,该向量根据余弦相似性从数据库中检索相关代码块。 然后,这些块用于提供生成响应的上下文,创建包含真实世界编码模式和解决方案的丰富、知情的输出。
图1。 用户查询的RAG技术
RAG评估 在Sandia对naive RAG的初步评估中,使用了各种指标,包括BLEU、ChrF、METEOR和ROUGE-L,以根据Sandia Kokkos开发人员提供的标准基准评估生成代码的有效性。 令人鼓舞的是,初步结果显示,随着RAG方法的实施,标度平均值评估增加了3-4个百分点。
嵌入模型 有限责任经理 BGE–大型–EN–V 1.5 MISTRAL–7B–说明–V0.2 E5–底座–V2。 MIXTRAL–8X7V–说明–V 0.1 NVolve40K解决方案 WIZARDCODER–15B–V1.0版 阿联酋–大型–V1 MAGICOD ER–S–DS–6.7 B。
表1。 测试嵌入模型和开源LLM 模型 OSS标度平均值 RAG标度平均值 mistalai-MIstral-7B-指令-v0.2 18.75 22.59 mistalai-Mixtral-8x7B-仪器-v0.1 23.68 23.85 向导LM_WizardCoder-15B-V1.0 25.01 28.61 ise-uiuc_MagicCoder-S-DS-6.7B 25.90 28.96
表2。 对开源软件(OSS)嵌入模型和LLM进行基准测试 模块化HPC工作流的RAG结果 通过一个幼稚的RAG管道实现,性能得到了微小的改进。 Mixtral模型(MoE架构)没有受到附加的Kokkos上下文的显著影响。
没有找到更好的嵌入模型。 相反,嵌入模型和LLM的特定配对提供了最佳结果。
用于多查询检索的RAG Sandia团队还试验了先进的RAG技术,以改进如何检索相关内容。
其中一种技术涉及生成多个相关查询,以扩大对适用代码段的搜索,特别是当用户查询模糊或缺少特定细节时。 该方法提高了检索更相关上下文的可能性,提高了生成代码的准确性和实用性。
图2。 将多查询检索应用于中型代码示例
下面的示例显示了一个查询以及由多查询检索器创建的生成的查询。
提示:创建尺寸为10 x 3的双打Kokkos视图 生成的查询: 1.如何创建10 x 3号双打的Kokkos视图? 2.如何创建大小为10 x 3的double的Kokkos视图,并用随机值初始化它? 3.如何创建一个大小为10 x 3的double的Kokkos视图,并使用文件中的值对其进行初始化? 数据集上下文丰富 Sandia研究人员也在探索父文档检索方法。 在这种方法中,数据被分割为提供一般上下文的大型父块和专注于特定细节的较小子块。
该策略有助于平衡特定性需求和上下文广度,优化检索信息的相关性和全面性。
图3。 将数据集拆分为父数据块和子数据块
下面的提示示例显示了用于搜索数据库的子块和父块。
提示:创建尺寸为10 x 3的双打Kokkos视图 儿童区块: //创建Kokkos::视图X_lcl。 const size_t numLclRows=10; const size_t numVecs=3; 类型名dual_view_type::t_dev X_lcl(“X_lc1”,numLclRows,numVecs); 父区块: //创建Kokkos::View X_lcl。 const size_t numLclRows=10; const size_t numVecs=3; 类型名dual_view_type::t_dev X_lcl(“X_lc1”,numLclRows,numVecs); //修改Kokkos::View的数据。 Kokkos::deep_copy(X_lcl,ONE); { lclSuccess=成功? 1 : 0; gblSuccess=0;// 输出参数 reduceAll<int,int>(*comm,REDUCE_MIN,lclSuccess,outArg(gblSuccessment)); TEST_EQUALITY_CONST(gblSuccess,1); if(gblSuccess!=1){ 回报; } std::ostringstream操作系统; os<<“Proc”<<comm->getRank()<<“:checkpoint 1”<<std::endl; 标准::cerr<<os.str(); } 用于HPC结果的高级AI Sandia团队的初始评估使用了标准的NLP指标,如BLEU(双语评估替补)和ROUGE(回忆导向替补)。
然而,他们认识到需要一个更适合代码生成的更量身定制的评估指标,尤其是一个可以评估生成代码的语法准确性和操作效率而不依赖传统输出比较的指标。
增强未来的代码功能 随着桑迪亚的科学家们完善他们的检索方法和人工智能模型,他们预计编码助手不仅能生成功能准确的代码建议,还能生成与上下文相关的代码建议。 未来的发展将侧重于微调基本模型,类似于NVIDIA工程师对ChipNemo的操作,并优化检索过程,以及在可用时集成更先进的LLM和嵌入技术。
用于HPC代码开发的AI 将人工智能集成到代码开发中,特别是在高性能计算范围内,代表着生产力和效率的重大飞跃。 概念验证适用于内部的一些产品 NVIDIA NeMo公司 Sandia站在了这一变革的前沿,推动了人工智能在复杂计算环境中的发展。 通过不断调整和改进他们的人工智能模型和方法,Sandia旨在为您提供强大的工具,增强您的创新能力和解决复杂问题的能力。
这项先进的RAG计划展示了人工智能在软件开发中的潜力,并强调了目标解决方案在技术进步中的重要性。
在Sandia,他们正在评估内部和外部云解决方案,以托管这些复杂的AI模型,这需要大量的GPU资源。 选择取决于合适硬件的可用性和Sandia团队的使用规模。 与NVIDIA等供应商合作可以提供宝贵的支持,尤其是在将其容器系统与Sandia现有基础设施集成方面。
有关更多信息,请参阅以下资源:
ChipNeMo:芯片设计领域自适应LLM :包括如何使用RAG创建芯片设计的EDA脚本的解释,以及创建并行代码的RAG模型的一些类似特征。

![标度平均值=[100(BLEU+RougeL+CodeBLEU+METEOR)+ChrF]\slash5](https://s0.wp.com/latex.php?latex=Scaled+mean+%3D+%5B100%28BLEU%2BRougeL%2BCodeBLEU%2BMETEOR%29%2BChrF%5D%5Cslash5&bg=transparent&fg=000&s=0&c=20201002)