介绍
我从八年级就开始学习拉丁文(目前我正进入十二年级),每年我都会更加喜欢这种语言。上个学年,我选修了AP拉丁语,并立即被拉丁文诗歌的复杂世界所吸引。与此同时,我参加了人工智能课程,并继续培养对计算机科学的热情。用拉丁语(尤其是诗歌)编码的想法在我脑海中酝酿了一段时间,在过去两周的夏令营中,我终于想出并创建了这个项目。
许多重要的拉丁诗歌作品都采用了指形六边形的格式,这意味着每一行都由六个韵脚的组合组成,每一个韵脚要么是一个pondee(两个长音节),要么是一种dactyl(一个长音节后接两个短音节)。每个音节的长度取决于单词本身、它在行中的位置、周围的单词和韵脚。扫描是识别一行拉丁诗歌中韵律脚的模式的过程。有一种快速扫线的方法,可以让朗诵罗马诗歌更容易,让“拉丁人”以外的观众欣赏拉丁节奏模式的美,以及语言本身的美。在这个项目中,我使用机器学习来扫描手指六边形的拉丁诗歌行。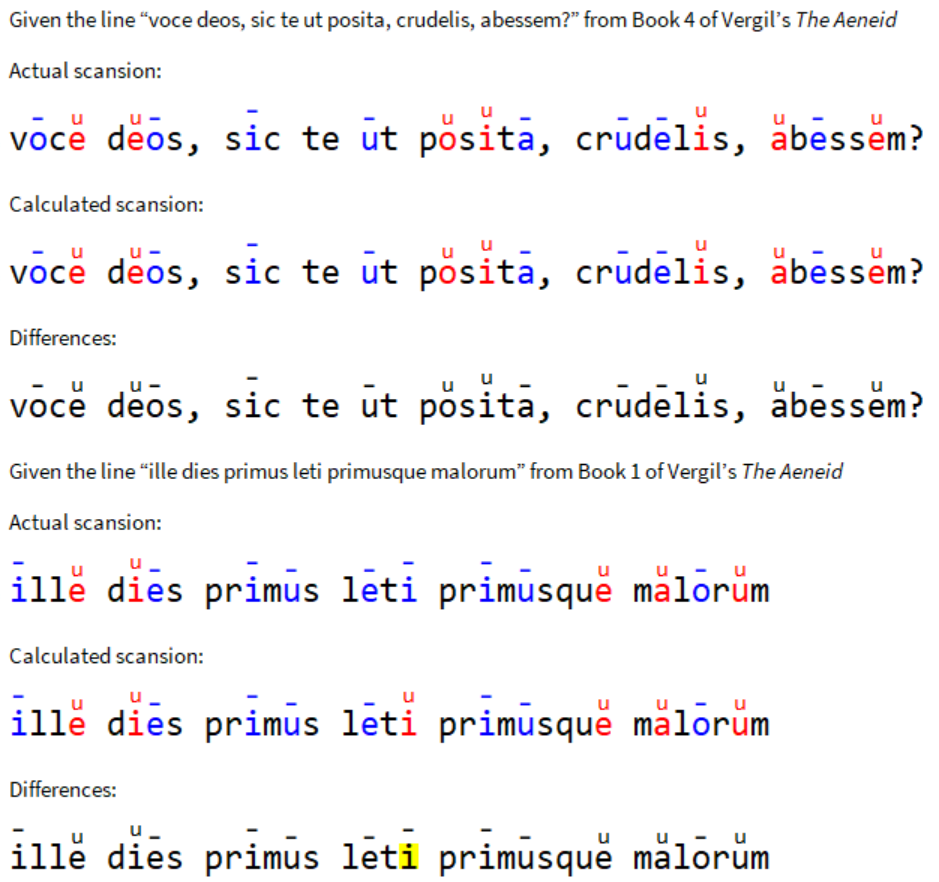
扫描
拉丁文诗歌主要使用两种韵律脚:扬抑,或两个长音节,和指形,或一个长音节后接两个短音节。不同的米需要不同数量的总英尺或特定类型的英尺。在指形六边形中,六只脚中的最后两只几乎总是指和足,前四只可以是指或足。脚的其余部分是通过一系列规则确定的,并最终进行消除。因为每个单词的音节长度和词尾都会根据其在句子中的功能而变化,所以简单地使用拉丁语词典就很难实现自动扫描。
理解项目结果的一些基本规则:-一些元音根据单词本身的性质被指定为长或短-双元音总是长的-元音后面跟两个辅音通常是长的-当一个以元音结尾的单词(或一个元音和字母“m”)后面跟以元音开头的单词(或者字母“h”)时和元音),第一个单词的最后一个音节“消失”在所谓的省略中
方法
我最初计划使用在拉丁语课堂上学到的规则实现自动扫描。然而,我已经知道如何做到这一点,最终,我来到营地是为了学习和探索Wolfram语言中的编码,而不是做一些我在家可以做的事情。因此,我开始了用Wolfram语言通过神经网络的激动人心(客观上可能不太成功)的旅程。
在找到并解析数据后,我在开发神经网络时尝试了四种不同的输入/输出组合,并对每个组合的数字和层次进行了调整。我最终使用了一个序列到序列网络,输入一行文本,输出每个字符成为长元音的概率列表;短元音;或辅音、标点符号或忽略的元音。从那里,我将神经网络输出转换为带有韵律标记的彩色编码线。
数据
我从美联社拉丁语资源中获得了在www.hands-up-education.org上扫描维吉尔的《埃涅阿斯纪》的训练数据。这些行包括音节长度和韵律断脚,格式如下:“?rm?v?r|?mqu?c?n|?,||Tr?|ia?qu?|pr?m?s?b|?r?s。”
去掉韵脚的标记后,我将线条及其标记转换为整数列表(每个字符一个),其中1表示长元音;2个短元音;3辅音、标点符号或忽略的元音。然后,我将该文件转换为一个规则列表,其中的普通行指向其关联的字符“长度”列表
formatData[lines_]:=表[plainLine[x]->所有字符长度[removeFootMarks[x]],{x,lines}]
下面是我使用的一个数据点示例:
“印度语通过Tartarei quae fert Acherontis ad undas”->{3,1,3,3,3,3,2,3,3,1,3,2,3,2,1,3,33,31,3,2,3,3,1,2,3,13,3}
神经网络
我使用824行作为我的训练数据,使用20行作为我的测试数据。我训练了一个序列到序列的神经网络。为了找到最佳组合,我改变了EmbeddingLayer参数和MaxTrainingRounds。我最终在12号和100号使用。
net=NetChain[{EmbeddingLayer[12],NetBidirectionalOperator[LongShortTermMemoryLayer[32]],NetMapOperator[PlinearLayer[3]],SoftmaxLayer[]},“Input”->NetEncoder[{“字符”,{{“!”,“(”,“)”,“.”,“,”,“;”,“?”,“:”,“”,“]结果=NetTrain[net,trainingData,All,LossFunction->CrossEntropyLossLayer[“Index”],ValidationSet->testData,MaxTrainingRounds->1000]
我获得的神经网络在验证数据上的误差为2.9%,因此每隔几行就会出现一个分类错误的字符。
格式化神经网络输出
神经网络为每个字符输出1、2和3的概率列表,如下所示:
{{0.233388, 0.747286, 0.0193251}, {0.0237603, 0.102153, 0.874087}, {0.000247855, 0.00735917, 0.992393}, {0.0196234, 0.932275, 0.0481015}, {0.000736693, 0.0109938, 0.98827}, {0.000217165, 0.00133861, 0.998444}, {0.912511, 0.0845969,0.00289202}, {0.00648514, 0.0000726016, 0.993442}, {0.941853, 0.00259834, 0.0555489}, {0.000389534, 0.0000140205, 0.999596}, {0.000185425, 0.000205691, 0.999609}, {0.00244669, 0.0108199, 0.986733}, {0.165211, 0.616111, 0.218678}, {0.000199178, 0.0000279639, 0.999773}, {0.0000528181, 3.42483*10^-6, 0.999944}, {0.920206, 0.000883119, 0.0789105}, {0.00396218, 8.48394*10^-7, 0.996037}, {0.992206, 0.0000137013, 0.00778067}, {0.00125184, 5.09544*10^-7, 0.998748}, {0.000426706, 1.91505*10^-6, 0.999571}, {0.000130377, 4.82552*10^-6, 0.999865}, {0.0000298044, 9.46518*10^-6, 0.999961}, {0.172772, 0.0202387, 0.80699}, {0.942826, 0.0060539, 0.05112}, {0.30773, 0.0000756251, 0.692195}, {0.850813, 0.000620744, 0.148566}, {0.000179449, 3.39269*10^-6, 0.999817}, {0.0000538242, 0.00011357, 0.999833}, {0.000553092, 0.0406213, 0.958826}, {0.00931922, 0.985319, 0.00536204}, {0.0000223564, 0.000134355, 0.999843}, {0.00933962, 0.0149729, 0.975688}, {0.000112443, 0.000270864, 0.999617}, {0.470264, 0.527769, 0.00196643}, {0.000150167, 0.0000335595, 0.999816}, {0.239256, 0.209718, 0.551026}, {0.0000601962, 0.000211833, 0.999728}, {0.0000575157, 0.00195887, 0.997984}, {0.0931677, 0.556272, 0.35056}, {0.00254616, 0.00115129, 0.996302}, {0.0340716, 0.00185011, 0.964078}, {0.987841, 0.00371802,0.00844058}, {0.0313373, 0.000806895, 0.967856}, {0.752181, 0.226585, 0.021234}, {0.00223789, 0.00123329, 0.996529}}
我将概率格式化为每个字符的最可能整数列表。
calcOutput[probs_]:=表[If[Max[x]==x[[1],1,If[Max[x]==x[[2],2,3]],{x,probs}]
从整数列表中,我对新扫描的行进行了格式化和颜色编码。
标记={样式[“-”,粗体],样式[“u”,较小]}大写[line_,lengths_]:=scannedLine=扫描线=表[If[lengths[[x]]==3,StringPart[line,x],上标[StringPart[line,x],标记[[长度[[x]]]],{x,范围[长度]}]颜色[line_,lengths_]:=(newLine=表[如果[长度[[x]]==3,行[[x],样式[line[[x]],如果[lengths[[x]==1,Blue,Red]]],{x,范围[长度]}];样式[行[newLine],大])
最终产品
给定一行,程序猜测音节模式,并输出带有标记的彩色编码行。
扫描[line_]:=(out=calcOutput[trainedNet[line]];颜色[上标[line,out],out])

结论和未来扩展
通过这个项目,我能够创建一个神经网络,它成功地确定并格式化了拉丁诗歌中用指形六边形表示的行的韵律模式(2.9%的错误)。该程序采用一行简单的诗歌,并输出带有韵律标记的彩色编码行。
将来,可以在显示的线条中添加韵律脚之间的标记。该程序还可以扩展到其他类型的韵律或其他语言的诗歌。
致谢
我要感谢我的良师益友克里斯蒂安·帕斯克尔,他在整个过程中给予了我无尽的支持。我还要感谢其他Wolfram夏令营导师以及Wolfram暑期学校的导师和学生。

