一位SAS统计程序员最近提出了一个关于统计的理论问题。“我读到过‘p值在零假设下均匀分布’,”他开始说道,“但这在实践中意味着什么?重要吗?”
我认为数据模拟是讨论p值一致(或不一致)的条件的好方法分布式。本文执行以下操作:
- 说明p值均匀分布的条件。简要地,你必须有一个统计模型(M),一个从M中抽取的随机样本(X),以及一个假设检验,该检验统计具有已知分布。
- 举例说明p值不再均匀分布的情况。一种常见的情况是模型(M)和数据(X)具有不同的分布。
p值究竟是什么?
本节讨论了p值的一些理论、使用和误用。如果你熟悉p值,或者只想直接跳到例如,您可以跳过本节。
P值可能会导致混淆、误解和误用。甚至专业统计学家也会感到困惑。学生和科学家经常不理解他们。正是由于这些原因,美国统计协会(ASA)2016年发布了一份声明,澄清了p值的适当使用(Wasserman和Lazar,2016年,ASA关于p值的声明:背景、过程和目的,TAS公司). 这一声明是对一些关于p值在科学中如何使用的批评的回应。这也是对几家著名科学期刊决定在其发表的文章中“禁止”p值的回应。
我鼓励感兴趣的读者阅读Wasserman和Lazar(2016)中描述p值的解释、误解、应用和误用的六点。
ASA关于p值的声明是为从业人员编写的。Wasserman和Lazar(2016)对p值的定义如下:“非正式地,p值是指在特定统计模型下,数据的统计汇总(例如,两个比较组之间的样本平均差)等于或大于其观察值的概率。”在此定义下,p值是使用一组数据计算的一个数字。不幸的是,此定义无法启用你来讨论分布p值。
要讨论分布,您必须采用更广泛的视角:您必须将p值视为随机变量。这在一篇优秀的文章中由格陵兰岛(2019年)在同样优秀的文章中Murdoch、Tsai和Adcock(2008).
其想法是,数据(X)是来自假设模型分布的随机样本。当您生成随机样本时,数据决定了零假设的测试统计量。因此,测试统计是一个随机变量。每个测试统计都有一个p值。因此,p值也是一个随机变量。如果测试统计量的分布已知,那么根据定义,p值是均匀分布的,因为它是测试统计量的概率积分变换.
基于模拟的p值方法
本节显示了一个常见的假设检验和p值示例:单样本t吨测试平均值。回想一下,一个样本t吨该测试假设随机样本包含来自正态分布的独立抽取。(您也可以使用t吨测试来自非正态连续分布的大样本,但为了简单起见,让我们使用正态数据。)假设数据来自N(72,σ)。无效假设是H0:μ≥72与μ<72的替代假设。让我们生成N=20个独立的正态变量,并使用SAS中的PROC TTEST运行单侧t吨模拟数据测试:
/*定义参数*/
%出租 N个=20;/*样本量*/
%出租单位:MU0=72;/*参数真值*/
数据模拟1;/*mu=&MU0的正态分布随机样本*/
呼叫流线型的(1234);做我=1至&N个;x=兰特(“正常”,&单位:MU0,10);输出;结束;运行; /*H0:发电分布有mu<=&MU0。由于N很小,也假设数据正常*/
程序测试 数据=Sim1α=0.05H0型=&单位:MU0侧面=L图=无;变量 X(X);运行; |
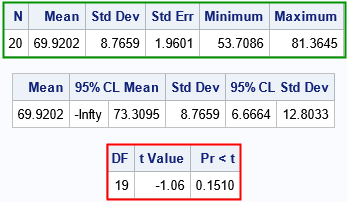
输出包括样本的描述性统计数据表(顶部表格)。中间的表格显示了关于参数的推论,例如真实平均值可能小于73.31。最后一张表是我想关注的。它总结了假设检验的检验统计数据。测试统计值为-1.06。假设统计是根据t吨19个自由度的分布,我们观察到值小于-1.06的概率为Pr(T<-1.06)=0.1510。
这里有一点很重要:由于我们模拟了N(72,σ)的数据,我们知道零假设是正确的,并且我们知道测试统计数据确实具有T(DF=19)分布!因此,当t吨测试的p值很大,我们无法拒绝零假设。
然而,回想一下,当我们模拟样本时,我们可能会运气不好。对于5%的正常样本t吨测试将产生较小的p值,我们将拒绝零假设。因此,当我检查模拟的正确性时,我喜欢生成许多随机样本,而不仅仅是一个。
模拟研究t吨测试
如果您想了解p值的分布,可以执行蒙特卡罗模拟研究,其中您从相同的分布中生成许多大小为N的随机样本。你运行了一个t吨对每个样本进行测试,生成许多测试统计数据和许多p值。以下SAS程序执行此模拟研究,建议如下Murdoch、Tsai和Adcock(2008):
/*多个随机样本的模拟*/
%出租数字(NumSim)=10000;/*随机样本数*/
数据SimH0;呼叫流线型的(1234);做示例ID=1到&数字(NumSim);做我=1至&N个;x=兰特(“正常”,&单位:MU0,10);输出;结束;结束;运行; ods排除所有;程序测试 数据=SimH0α=0.05H0型=&单位:MU0侧面=L图=无;通过样本ID;变量 X(X);ods公司输出TTests=TTests;运行;ods不排除none; 标题 “单样本T检验的测试统计”;标题2“H0:mu0<=&mu0”;程序sgplot 数据=T测试;直方图t值/比例=透明度百分比=0.5;运行; |
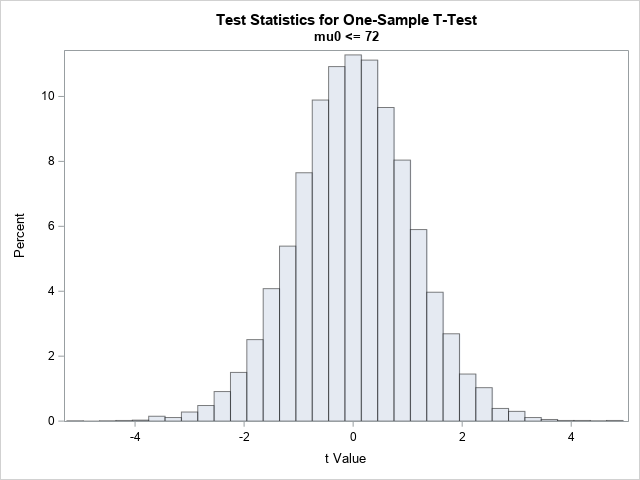
数据满足t吨测试和是从正态分布中采样的,对于正态分布,真实参数值满足零假设。因此,直方图显示测试统计的分布看起来非常像t吨19个自由度的分布。
这与p值有什么关系?好吧,p值只是一个测试统计的转换。p值是一种使标准化这个测试统计数据,以便更容易解释。对于任何t,对应的左尾p值为p=CDF(“t”,t,29),或右尾p值的1-CDF。如前一篇文章所述,如果t分布为t(DF=29),则p为U(0,1)。您可以通过绘制p值来证明这一事实:
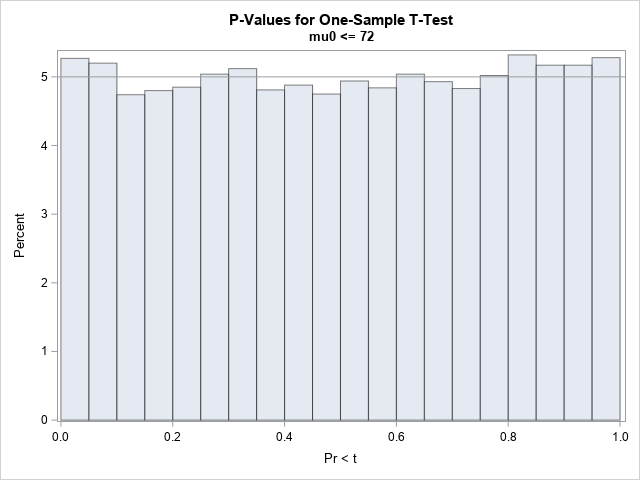
正如所承诺的那样,p值均匀分布在(0,1)中。如果你当p值小于0.05时,拒绝零假设,您将在5%的时间内发生类型1错误。
注意,要使p值均匀分布,许多事情必须同时发生。数据必须符合测试的假设,并包含来自用于构建测试统计的模型的独立随机变量。如果是这样,则测试统计遵循已知的t吨分配。(有时我们只知道测试统计量的渐近分布。)如果所有这些恒星都对齐,那么p值将均匀分布。
p值何时不一致?
如果前面的任何假设都不成立,那么p值就不需要均匀分布。最容易可视化的情况是,如果数据不是从平均值等于零假设平均值的分布中采样的。例如,我们从N(72,σ)生成数据,但如果我们运行t吨假设H0的检验:μ≥73?在这种情况下,我们预计会有更多的样本拒绝新的零假设。还有多少?正如Murdoch、Tsai和Adcock(2008)所建议的那样,我们不需要猜测或计算,只需对所有10000个样本(来自N(72,10))进行新的假设检验,并绘制p值:
/*如果样本不是来自零假设,会发生什么*/
%出租MU1公司=%系统(sysevalf)(1+&单位:MU0);ods排除所有;程序测试 数据=模拟H0α=0.05H0型=73侧面=L图=无;通过样本ID;变量 x;ods公司输出TTests=TTestsNotH0;运行;ods不排除none; 标题 “单样本T检验的P值”;标题2“H0:mu=&MU0,但实际上mu=&MU1”;程序sgplot 数据=TTestsNotH0;直方图问题T/数据标签二进制宽度=0.05二进制启动=0.025 /*将第一个料仓置于h/2的中心*/比例=透明度百分比=0.5; 参考线5/轴=y;运行; |
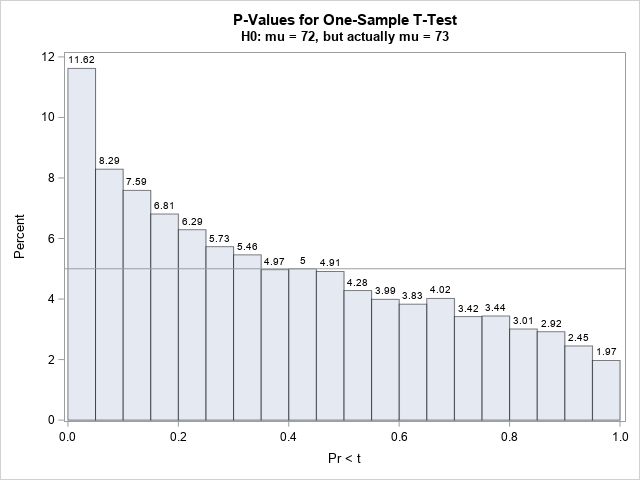
对于新的假设检验,约11.62%的样本的p值小于0.05。这意味着,如果您使用0.05作为截止值,您将在11.62%的时间内拒绝零假设。这很好,因为样本实际上是由平均值小于假设值73的分布生成的。在这种情况下,无效假设是错误的,所以您希望拒绝它。如果您进一步增加无效假设中使用的值(尝试使用75或80!),测试将拒绝更多的样本。
总结
本文使用模拟来说明多次重复的断言“p值在零假设下均匀分布。”文章显示了一个单一样本的假设检验示例t吨测试。当数据满足t吨测试和生成,以使零假设正确,则测试统计量具有已知的抽样分布。p值是测试统计量的转换。当测试统计量遵循其假设分布时,则p值是一致的。否则,p值是不一致的,这意味着使用p值截止值(如0.05)将以与截止值不同的概率拒绝零假设。
有关第二个示例,请参见“关于离散模拟的正确性。”
进一步阅读


