跳到主管道|跳到侧栏
 Unicode联盟宣布2019年牛头犬奖获得者:安迪·亨宁格和诺伯特·林登伯格。
Andy Heninger多年来为联合体的工作,包括提供关键的International Components中的分段和正则表达式支持Unicode(ICU)。在ICU执行这些功能之前,请在Unicode实现非常有限。这两项贡献都是稳健的关键文本支持。例如,正确的分割可以防止家族表情符号分裂!
诺伯特·林登伯格在多年来实现了Web国际化,并为Unicode脚本特殊组。他为许多Unicode标准的复杂脚本,包括泰语、缅甸语、高棉语、爪哇语、,和泰米尔语。他的作品被Mozilla、Yahoo!、!,太阳微系统公司和苹果公司。
多年来,两者都是强大的Unicode文本的推土机支持。
有关他们的许多贡献的更多详细信息,请访问Unicode斗牛犬奖励页面。
Unicode联盟宣布2019年牛头犬奖获得者:安迪·亨宁格和诺伯特·林登伯格。
Andy Heninger多年来为联合体的工作,包括提供关键的International Components中的分段和正则表达式支持Unicode(ICU)。在ICU执行这些功能之前,请在Unicode实现非常有限。这两项贡献都是稳健的关键文本支持。例如,正确的分割可以防止家族表情符号分裂!
诺伯特·林登伯格在多年来实现了Web国际化,并为Unicode脚本特殊组。他为许多Unicode标准的复杂脚本,包括泰语、缅甸语、高棉语、爪哇语、,和泰米尔语。他的作品被Mozilla、Yahoo!、!,太阳微系统公司和苹果公司。
多年来,两者都是强大的Unicode文本的推土机支持。
有关他们的许多贡献的更多详细信息,请访问Unicode斗牛犬奖励页面。
超过136000个字符可用于采用,至帮助Unicode联盟在数字弱势语言方面的工作。
![[徽章]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_uT0RvJqJehb9CDyBsaEsd7JnnNGSO9rDfkcDTLTqWoHZuEaxlwhUIWsgAXmvDKEPX4L6ia12O8-Y7Ay_DCFWIu92FUrBJFTyOuIHjjFY6E7LK-tW7FARTK=s0-d)
 表情符号12.1发布了168个新表情符号。有138种新的性别中立形式,所以你很快就能在不指定性别的情况下发送关于人的信息。此外,还添加了30种不同肤色的手拉手的新组合。
新表情符号列在Emoji最近添加v12.1,以及示例图像。这些图片只是示例:手机、个人电脑和网络平台的供应商通常会为表情符号设计自己的字体。特别是Emoji订购v12.1图表显示了新表情符号应如何按照现有表情符号的顺序进行排序,新表情符号用圆角矩形标记。其他的12.1版的表情图已更新以显示表情符号。
在中,可以使用不同语言的初始名称和搜索关键字Unicode CLDR 36码,例如卫生工作者(医生、护士。。。). 这些将在本季度进行改进。
新的表情符号12.1供应商可以使用这些数据创建emoji字体和代码。这些新表情符号将在本季度和下季度开始出现在手机上。新表情符号很快将可用于采用帮助Unicode联盟支持数字优势语言。
表情符号12.1发布了168个新表情符号。有138种新的性别中立形式,所以你很快就能在不指定性别的情况下发送关于人的信息。此外,还添加了30种不同肤色的手拉手的新组合。
新表情符号列在Emoji最近添加v12.1,以及示例图像。这些图片只是示例:手机、个人电脑和网络平台的供应商通常会为表情符号设计自己的字体。特别是Emoji订购v12.1图表显示了新表情符号应如何按照现有表情符号的顺序进行排序,新表情符号用圆角矩形标记。其他的12.1版的表情图已更新以显示表情符号。
在中,可以使用不同语言的初始名称和搜索关键字Unicode CLDR 36码,例如卫生工作者(医生、护士。。。). 这些将在本季度进行改进。
新的表情符号12.1供应商可以使用这些数据创建emoji字体和代码。这些新表情符号将在本季度和下季度开始出现在手机上。新表情符号很快将可用于采用帮助Unicode联盟支持数字优势语言。
超过136000个字符可用于采用,至帮助Unicode联盟在数字弱势语言方面的工作。
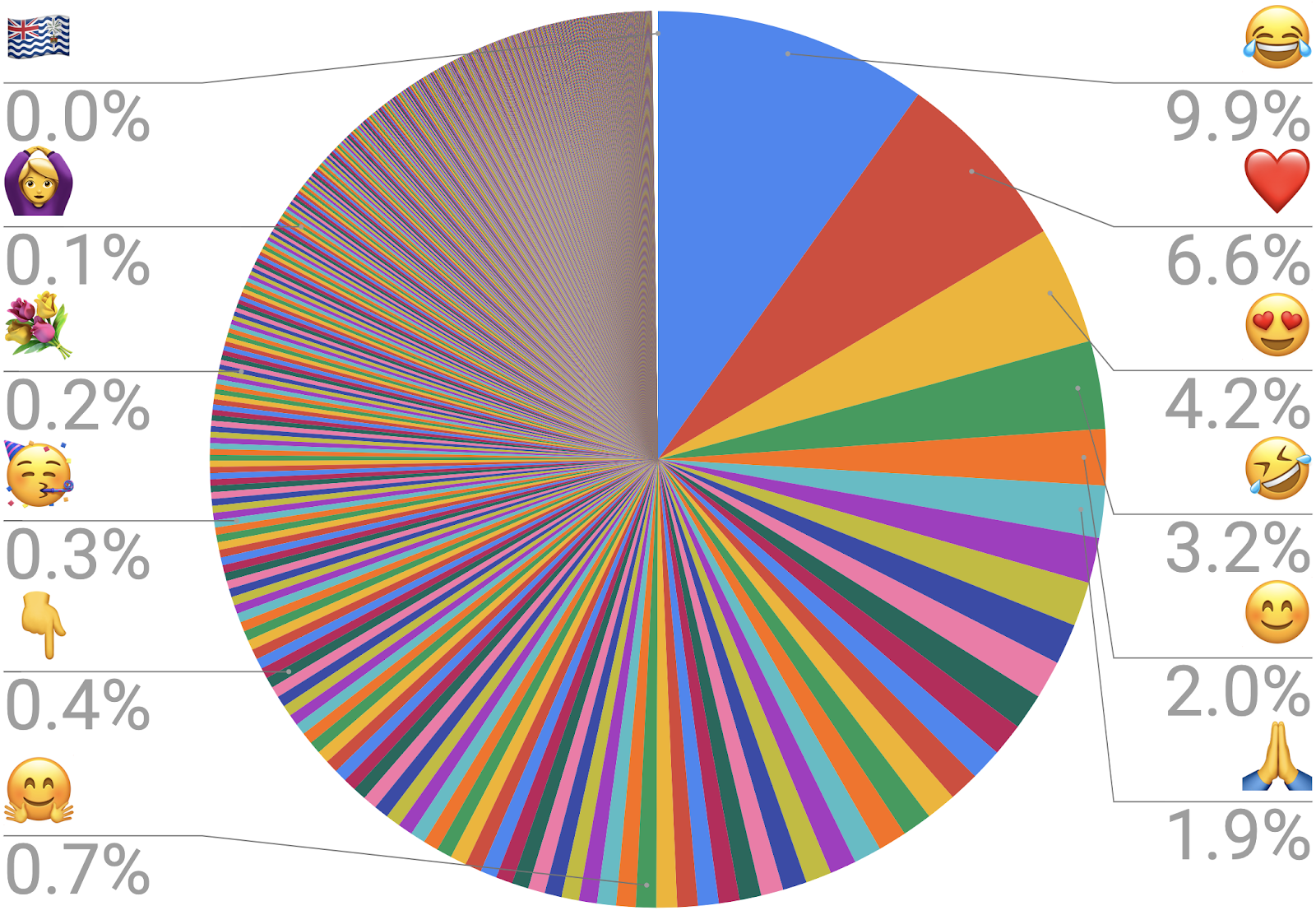 Unicode联盟如何选择添加哪些新表情符号?一个重要因素是关于当前表情符号使用频率的数据。使用模式有助于决定未来的表情符号。联合体一直在努力收集这些信息并向公众提供。
世界上最常用的两个表情符号是。。。
Unicode联盟如何选择添加哪些新表情符号?一个重要因素是关于当前表情符号使用频率的数据。使用模式有助于决定未来的表情符号。联合体一直在努力收集这些信息并向公众提供。
世界上最常用的两个表情符号是。。。
😂 和❤️
新的Unicode表情符号频率页面显示了Unicode v12.0表情符号的列表,按照使用频率进行了排名。
Unicode协会主席Mark Davis表示:“预测的使用频率是决定是否对新表情符号进行编码的关键因素,因此了解现有表情符号的使用频率非常重要。”。“了解表情符号的使用频率有助于确定哪些类别需要重点关注,哪些表情符号需要添加到标准中。”
超过136000个字符可用于采用,以帮助Unicode联盟在数字弱势语言方面的工作。
 Unicode®ICU 65刚刚发布。它更新为CLDR第36页区域设置数据有许多添加和更正,以及一些新的测量单位。这个Java LocaleMatcher API得到了改进,并移植到了C++。对于构建ICU数据,有新的筛选选项,以及对数据加载的新跟踪支持ICU4C中。
ICU是一个软件库产品广泛使用和其他库支持世界语言,实现Unicode标准和Unicode地区数据(CLDR)的最新版本。
有关详细信息,请参阅http://site.icu-project.org/download/65。
Unicode®ICU 65刚刚发布。它更新为CLDR第36页区域设置数据有许多添加和更正,以及一些新的测量单位。这个Java LocaleMatcher API得到了改进,并移植到了C++。对于构建ICU数据,有新的筛选选项,以及对数据加载的新跟踪支持ICU4C中。
ICU是一个软件库产品广泛使用和其他库支持世界语言,实现Unicode标准和Unicode地区数据(CLDR)的最新版本。
有关详细信息,请参阅http://site.icu-project.org/download/65。
Unicode CLDR 36更新了支持世界语言的软件。CLDR数据供所有人使用主要软件系统针对他们的软件国际化和本地化针对此类通用软件的不同语言约定的软件任务。
CLDR 36包括一个完整测量工具数据收集阶段,新增约32K个翻译字段,适度和/或现代覆盖率显著增加代表:ceb(Cebuano)、ha(豪萨语/拉丁语)、ig(伊博语)、kok(康卡尼语)、qu(克丘亚),to(汤加),yo(约鲁巴)。添加了几个新的种子数据语言:cic(Chickasaw)、mus(Muscogee)、osa(Osage,Osage脚本);一个(阿拉贡语),su(巽他语,拉丁文),szl(西里西亚语)。
v36中的增强功能包括:
- 新Emoji 13草稿候选人的姓名和搜索关键词是包含在本版本中,以支持即将推出的Emoji的顺利采用发布(计划于2020Q1发布,作为Unicode 13的一部分)
- 新的测量单位和模式:每厘米点,点/英寸、em、百万像素、像素、像素/厘米、像素/英寸;十年;热-我们;巴,帕斯卡;和用于组合乘法关系,如“牛顿米”。
- 区域设置ID:
- 扩展语言匹配可以为许多包含语言。
- 从BCP47语言子标签中添加了更多语言别名注册表,用于不推荐使用的语言。
- 为localeIdentifiers添加了一个新的测试目录,graphemeClusters(用于当前支持的印度语)和音译。
需要注意一些基础架构更改,包括:
- cldr存储库已从subversion迁移到git,并且使用Trac的查询不再有效。请参阅CLDR变更请求获取新信息。
- cldr存储库中的数据现在保留了对继承数据,用“↑↑↓”表示。为了在前一种形式没有“↑↑GenerateProductionData可用。
注:已发布的数据可以并行使用GenerateProductionData进行处理cldr-老化存储库,具有相同的发布标签。
公共区域数据存储库(CLDR)提供了关键的构建支持世界语言的软件块,具有最大和最多的提供了广泛的语言环境数据标准存储库。此数据由各类公司针对他们的软件国际化和本地化,使软件适应针对以下常见软件任务的不同语言约定:
- 格式化和解析的特定于本地的模式:日期、,时间、时区、数字和货币值、度量单位,…
- 姓名翻译:语言、文字、国家和地区地区、货币、时代、月份、工作日、白天、时区,城市、时间单位、表情符号字符和序列(以及搜索关键字),…
- 语言文字信息:使用的字符;复数形式;名单性别;资本化;排序和搜索规则;书写方向;音译规则;拼写数字的规则;的规则将文本分割成字母、单词和句子;键盘布局;…
- 国家信息:语言使用、货币信息、,日历首选项、周惯例…
- 有效性:的定义、别名和有效性信息Unicode区域设置、语言、脚本、区域和扩展,…
超过136000个字符可用于采用,至帮助Unicode联盟在数字弱势语言方面的工作。


