本文描述了识别和分析GnuTLS低效部分的过程。我正在使用的工具是callgrind。我不会详细描述这个工具,因为我不是callgrund专家,而是关注于发现和解决问题的方法。我希望这对了解维护人员如何解决与性能相关的问题很有用。它还展示了像valgrind和callgrind这样非常有用的工具。
今天我偶然发现了一篇罕见的帖子,其中包含重现问题的示例代码。这篇文章是埃德加·傅在openldap列表上写的:连接到edgars柱首先,这里有一点需要学习:如果那篇帖子中没有代码,我很可能会忽略它,因为理解和复制这个问题对我来说太麻烦了。尤其是当这不是一个真正的GnuTLS错误报告,而是关于非GnuTLS邮件列表的讨论时。通过发布这样的示例代码,我很容易编译和运行它。结果是,代码非常慢,我的好奇心也被发现了。Edgar的错误触发代码(为了可读性做了一些修改):
d=opendir(“/etc/ssl/certs”);gnutls_certificate_allocate_credentials(&ca_list);while((dent=readdir(d))!=空){sprintf(ca_file,“/etc/ssl/certs/%s”,dent->d_name);stat(ca_file,&s);如果(!S_ISREG(S.st_mode))继续;gnutls_certificate_set_x509_trust_file(ca_list,ca_file,GNUTLS_X509_FMT_PEM);}closedir(d);
如果您不熟悉GnuTLS,我将描述代码的用途/etc/ssl/certs/和电话gnutls证书设置_x509信任文件对于每个文件。该函数将读取文件中存储的一个或多个X.509 CA证书,并将其添加到GnuTLS内的CA信任存储中。这些文件通常较小(1-2kb),但包含由GnuTLS解码的base64编码ASN.1数据。CA信任存储用于确定是否信任客户端或服务器的证书。虽然这通常只在启动时完成,而不是在每个TLS连接期间完成,但它不是特别关键的性能。不过,如果速度过慢,则会降低应用程序的启动速度。
在我的系统(x86 Debian测试)中,/etc/ssl/certs目录包含206个文件。我编译了测试代码并运行了它:
茉莉@mocca:~$gcc-o foo foo.c-lgnutls
茉莉@摩卡:~$次/foo/etc/ssl/certs/
实际0m40.821s
用户0m40.743s
系统0m0.036s
茉莉@mocca以下为:~$
40秒!将应用程序的启动延迟这么多是非常重要的,所以我知道这被认为是一个问题。
我开始好奇这个过程使用了多少内存。如果我的机器已经开始分页(不太可能是2GB的,但你永远也不知道),我可以理解它是否如此慢。然而,最高产量相对稳定:
PID用户PR NI VIRT RES SHR…
6538家20 0 5548 3668 752…
换句话说,虚拟大小约为6MB,这看起来很正常。我的下一步是在valgrind下运行二进制文件,以可能检测任何内存损坏或其他可能解释缓慢的问题。Valgrind大大降低了执行速度,大约7分钟后,我放弃了,并对代码进行了轻微修改,使其只迭代了前两个文件。在运行了一次valgrind之后,我发现代码没有调用所需的gnutls_certificate_free_credentials()和gnutls_global_deinit()。您可以下载更新的示例代码gnutls-call研磨.c。用于关闭某些已知libgcrypt内部内存泄漏的valgrind suppressions文件可用作库加密.supp.
茉莉@mocca:~$gcc-o foo foo.c-lgnutls
茉莉@mocca:~$次/foo公司
实际0m0.222s
用户0m0.216s
系统0m0.004s
茉莉@mocca:~$time valgrind–suppressions=foo.supp–安静/foo公司
实际0m7.619s
用户0m7.488s
系统0m0.108秒
茉莉@mocca:~$
很好!没有内存泄漏。我们现在可以相对肯定的是,问题实际上是源于代码的意图,而不是一些与内存相关的错误。鉴于我们在这里使用C,您希望尽早排除此类问题,因为它们是需要调试的噩梦。
现在是性能调优会话。让我们在应用程序上运行callgrind。首先,我们必须确保使用一个用调试信息编译的GnuTLS。最简单的方法是根据静态libgnutls编译它。按以下步骤操作。
茉莉@mocca:~$gcc-o foo foo.c/usr/lib/libgnutls.a-lgcrypt-ltasn1-lz
茉莉@mocca:~$time valgrind–tool=callgrind-安静/foo公司
实际0m18.292秒
用户0m18.129s
系统0m0.084s
茉莉@mocca:~$ls-la callgrind.out.8164
-rw---1个jas jas 69654 2008-02-26 21:46 callgrind.out.8164
茉莉@mocca:~$k咖啡磨&
如您所见,执行时间甚至比valgrind慢。配置文件数据输出文件非常小。运行kcachegrind会产生此输出(单击放大):
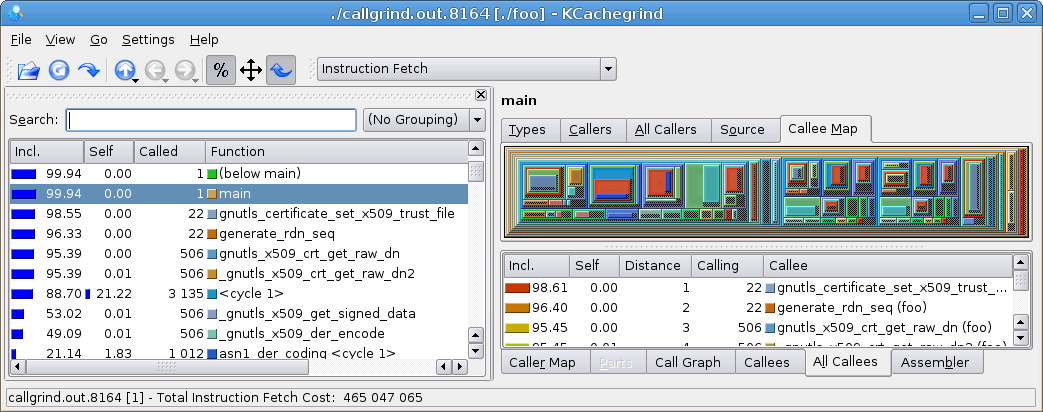
一开始,kcachegrind中的信息量可能非常庞大。然而,有趣的值位于左侧的百分比和调用计数列中。它告诉我们gnutls_certificate_set_x509_trust_file()被调用了22次,98%的时间都花在那里。(如果您对22感到惊讶,请查看代码,变量我从0开始,循环一直运行到大于20,即21,这使得循环中有22次迭代。)该函数的代码如下所示:
{int ret,ret2;size_t大小;char*data=read_binary_file(cafile,&size);if(数据==NULL){gnutls_assert();返回GNUTLS_E_FILE_ERROR;}如果(类型==GNUTLS_X509_FMT_DER)ret=parse_der_ca_mem(&res->x509_ca_list,&资源->x509_ncas,数据、大小);其他的ret=parse_pem_ca_mem(&res->x509_ca_list,&资源->x509_ncas,数据、大小);自由(数据);如果(ret<0){gnutls_assert();回流管;}如果((ret2=generate_rdn_seq(res))<0)返回ret2;返回ret;}
callgrind输出告诉我们,96%的程序时间花在22次调用generate_rdn_seq()中,而这22次调用又调用gnutls_x509_crt_get_raw_dn,总共506次。对gnutls_509_crt_get_raw_dn的调用占程序执行时间的95%。
我们现在可以得出结论,问题出在generate_rdn_seq()函数内部,而不是gnutls_certificate_set_x509_trust_file()函数体的其余部分。假设95%的时间实际上是在generate_rdn_seq调用的函数中(即gnutls_x509_crt_get_raw_dn),问题是函数调用次数太多或速度太慢。
关于generate_rdn_seq()的目的是什么:它预先计算CA证书的名称列表。在TLS服务器中,此受信任CA的名称列表将发送给客户端。客户端使用该列表查找由服务器识别的CA颁发的客户端证书。为了避免每次需要时都计算列表(例如,对于每个连接),GnuTLS会预先计算并将其存储在凭证结构中。一个凭证结构可以与一个或多个TLS会话关联。
我们现在准备查看generate_rdn_seq的代码:
静态intgenerate_rdn_seq(gnutls_certificate_credentials_tres){gnutls_datum_ttmp;int ret;无符号尺寸,i;不透明*pdata;/*生成RDN序列*当证书*请求消息已发送。*//*FIXME:如果是客户,则不需要*这样做。这将节省时间和内存。*然而,我们没有可用的信息*这里。*/大小=0;对于(i=0;i<res->x509_ncas;i++){如果((ret=gnutls_x509_crt_get_raw_dn(res->x509_ca_list[i],&tmp))<0){gnutls_assert();返回ret;}尺寸+=(2+临时尺寸);_gnutls_free_datum(&tmp);}if(res->x509_rdn_sequence.data!=空)gnutls_free(res->x509_rdn_sequence.data);资源->x509_rdn_sequence.data=gnutls_malloc(大小);如果(res->x509_rdn_sequence.data==NULL){gnutls_assert();返回GNUTLS_E_MEMORY_ERROR;}res->x509_rdn_sequence.size=大小;更新=res->x509_rdn_sequence.data;对于(i=0;i<res->x509_ncas;i++){如果((ret=gnutls_x509_crt_get_raw_dn(res->x509_ca_list[i],&tmp))<0){_gnutls自由度(&res->x509_rdn_sequence);gnutls_assert();返回ret;}_gnutls写入数据16(pdata,tmp);pdata+=(2+tmp.size);_gnutls_free_datum(&tmp);}返回0;}
花点时间阅读并理解此代码。真正地。你讲完后,我会在这里等你解释。
这个资源->x509_ca_list变量包含到目前为止存储在内存中的CA的整个列表。它最初是空的。读取第一个文件后,它将包含一个证书。读取第二个文件后,它将包含两个证书,依此类推。
这里发生的事情是,对于要添加的每个证书,都会迭代整个证书列表,而不仅仅是一次,而是两次!调用函数的计算复杂性是O(2*n^2)其中n是要添加的证书名称的数量。第一次迭代是计算保存CA名称的字符串的大小。实际数据被丢弃。第二次迭代为相同的数据调用相同的函数,但现在将输出存储在适当的位置。
优化这一点的第一步是认识到,不需要每次添加新CA时都迭代所有CA。为最近添加的证书添加名称就足够了。由于每次可以添加多个CA,因此该函数需要另一个参数:要预先计算其名称的最近添加的CA的数量。
我们的新代码如下:
静态intadd_new_crt_to_rdn_seq(gnutls_certificate_credentials_tres,int new){gnutls_datum_ttmp;整数ret;size_t新闻大小;无符号字符*newdata;无符号i;/*将最后添加的CA的DN添加到RDN序列*当证书*请求消息已发送。*//*FIXME:如果是客户,则不需要*这样做。这将节省时间和内存。*然而,我们没有可用的信息*这里。*此外,此功能现在效率更高,*所以优化就不那么重要了。*/for(i=res->x509_ncas-新;i<res->x509_n卡斯;i++){如果((ret=gnutls_x509_crt_get_raw_dn(res->x509_ca_list[i],&tmp))<0){gnutls_assert();返回ret;}新闻大小=res->x509_rdn_sequence.size+2+tmp.size;if(新闻大小<res->x509rdn_sequence.size){gnutls_assert();_gnutls_free_datum(&tmp);返回GNUTLS_E_SHORT_MEMORY_BUFFER;}新数据=gnutls_realloc(res->x509_rdn_sequence.data,新闻大小);if(新数据==NULL){gnutls_assert();_gnutls_free_datum(&tmp);返回GNUTLS_E_MEMORY_ERROR;}_gnutls_write_datum16(新数据+资源->x509_rdn_sequence.size,tmp);_gnutls_free_datum(&tmp);res->x509_rdn_sequence.size=新闻大小;res->x509_rdn_sequence.data=新数据;}返回0;}
我更改了函数名,以反映它现在只更新一组最近添加的证书的名称列表。这也有助于查找和更新旧函数的所有调用方。
如您所见,此函数应该很复杂O(n)相反,因为它只添加了最近添加的CA的名称。
但在实践中速度更快吗?让我们检查一下!首先,移除如果(i++>20)断裂;语句,以便我们进行完整测试。为了便于说明,首先链接到旧的libgnutls.a并再次运行旧的测试用例。
茉莉@mocca:~$gcc-o foo foo.c/usr/lib/libgnutls.a-lgcrypt-ltasn1-lz
茉莉@mocca:~$次/foo公司
实际0m40.756s
用户0m40.679s
系统0米0.052秒
茉莉@mocca:~$
同样,这需要大约40秒。现在针对我们修改过的libgnutls重新编译并运行相同的测试:
茉莉@mocca:~$gcc-o foo foo.c/home/jas/src/gnutls/lib/.libs/libgnutls.a-lgcrypt-ltasn1-lz
茉莉@mocca:~$次/foo公司
实际0m0.288s
用户0m0.280
系统0米0.012秒
茉莉@mocca:~$
真 的!从40秒降至0.3秒。现在让我们来看一下callgrind的输出。
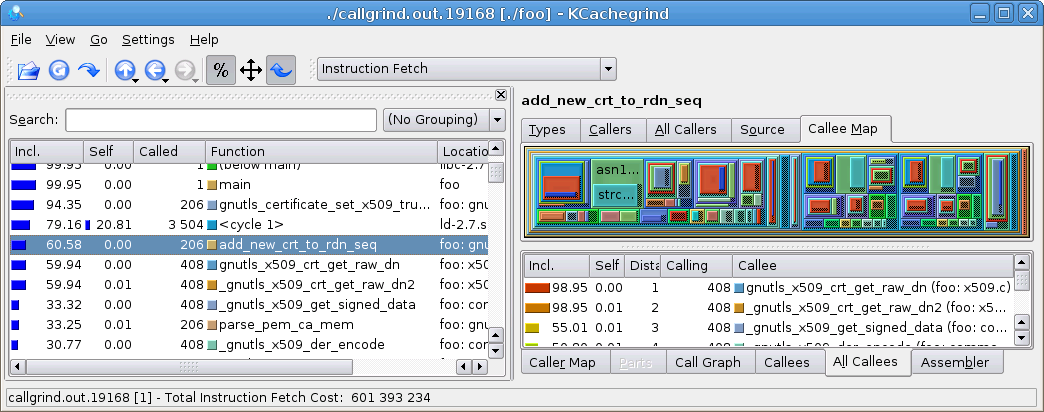
代码现在大约有60%的时间花费在add_new_crt_to_rdn_seq()中,这似乎是合理的。/etc/ssl/certs中有206个文件,这解释了调用计数。一些文件实际上包含几个CA证书(尤其是/etc/ssl/certs/CA-certificates.crt包含大量证书),这解释了为什么gnutls_x509_crt_get_raw_dn被调用408次。
此时,我停止了进一步优化代码。