语法教程
24百姓向摩西发怨言,说,我们喝什么呢?
25他呼求耶和华;上帝给了他一个树他把水倒在水里,水就变甜了。
出埃及记15,24-25
摩西支持被称为基于短语的层次模型和基于句法的模型这些模型使用由SCFG(同步上下文自由语法)规则组成的语法。在下文中,我们将这些模型称为基于树的模型.
内容
基于树的模型
传统的基于短语的模型将输入短语映射到输出短语作为原子翻译步骤。基于树的模型基于所谓的语法规则,其中包括映射规则中的变量:
内X1pas->非X1(法语-英语)吃X1->哈贝X1盖格森(英语-德语)X(X)1X的2->勒X2X(X)1(英语-法语)
这些语法规则中的变量称为非终结符,因为它们的出现表明进程尚未终止以产生最终单词(终端). 除了通用的非终结符X(X),语言驱动的非终结符,如NP公司(名词短语)或副总裁(动词短语)也可以在语法(或翻译规则集)中使用。
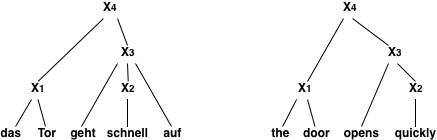
我们称这些模型为基于树的,因为在转换过程中,会创建一个称为树的数据结构。为了充分说明这一点,请考虑以下输入和翻译规则:
输入:Das Tor geht schnell auf公司规则:Das Tor->门
schnell->快速
个X1auf->打开X1
X(X)1X(X)2->X(X)1X(X)2
当按照给定的顺序应用这些规则时,我们生成翻译门很快打开按以下方式:
首先是简单短语映射(1)Das Tor公司到门和(2)施奈尔到迅速地执行。这允许应用更复杂的规则(3)个X1自动变速器到打开X1注意,此时,非终结符X(X),它覆盖了施奈尔替换为已知翻译迅速地最后,胶水规则(4)X(X)1X(X)2到X(X)1X(X)2将这两个片段组合成一个完整的句子。
以下是如何填写输入词的跨度:
|4----门开得很快----|||3---快速打开---||1门||2快|||达斯|Tor|geht|schnell|auf|
形式上,这种上下文无关语法比基于短语的模型的形式主义更具约束性。然而,在实践中,基于短语的模型使用了重新排序限制,这导致了线性解码时间。对于基于树的模型,除非使用了重新排序限制,否则解码与句子长度不是线性的。
目前对基于树的模型的研究期望建立翻译模型,以更紧密地模拟语言的底层语言结构及其基本元素:递归。这是一个活跃的研究领域。
术语一词
您可能已经阅读过有关统计机器翻译中基于层次结构的短语、字符串到树、树到字符串、树到树、目标语法化、语法增强、语法定向、语法为基础、语法为依据等模型的文献。基于树的模型支持什么?以上所有内容。
术语如雪崩般涌现,部分原因在于研究人员需要开拓自己的领域,部分原因是这一领域的工作尚未完全确定一个商定的框架,但也有一个根本性的差异。正如我们已经指出的,基于树的模型的动机是语言理论及其语法树。因此,当我们构建一个名为树(正如《计算机科学家》所称),我们的意思是建立一种语言语法吗树(正如语言学家所说)?
并非总是如此,因此产生了困惑。在上面的所有示例中,我们使用了一个非终端X(X),所以没有多少人会声称结果是一个带有名词短语的正确的语言句法NP公司,动词短语副总裁等等。为了区分在输入端、输出端、两者或两者都不使用正确语言语法的模型,所有这些术语都是发明出来的。
让我们解读一下文献中常见的术语:
- 基于层次短语:无语言语法,
- 字符串到树:仅输出语言中的语言语法,
- 树到字符串:仅在输入语言中使用语言语法,
- 树对树:两种语言的语言语法,
- 目标语法化:仅输出语言中的语言语法,
- 语法增强:仅输出语言中的语言语法,
- 语法导向:仅在输入语言中使用语言语法,
- 基于语法:不清楚,我们将其用于具有任何语言语法的模型,以及
- 基于语法:等等,什么?
在本教程中,我们将未命名的树称为树,和到语法注释为的树语法因此,所谓的字符串到树模型在这里被称为目标语法模型。
图表解码
基于短语的解码通过在部分翻译的末尾添加短语,从左到右生成句子。基于树的解码构建了一个图表,其中包括输入句子中所有可能跨度的部分翻译。
目前,Moses为每个规则中任意数量的非终结符和语法中任意数量类型的非终结词实现了CKY+算法。
解码
我们假设您已经安装了图表解码器,如快速入门第节。
您可以从中找到解码器的示例模型摩西网站.打开焦油球包装并进入目录样本模型:
%wget公司http://www.statmt.org/moses/download/sample-models.tgz%tar xzf示例-模型.tgz%cd样本模型/字符串到树
解码器的调用与短语模型相同:
%echo“das ist ein haus”|摩西_查特-f摩西.ini>out%猫出来了这是一所房子
这里发生了什么?
跟踪
使用选项-T型我们可以了解翻译是如何组装的:
41 X顶部-><s>s</s>(1,1)[0..5]-3.593<<0.000,-2.606,-9.711,2.526>>2020 X S->NP V NP(0,0)(1,1)(2,2)[1..4]-1.988<<0.000,-1.737,-6.501,2.526>>3 5 113 X NP->这个[1.1]0.486<0.000,-0.434,-1.330,2.303>>5 X V->为[2..2]-1.267<<0.000,-0.434,-2.533,0.000>>11 X NP->DT NN(0,0)(1,1)[3..4]-2.698<<0.000,-0.869,-5.396,0.000>>7 97 X DT->a[3..3]-1.012<<0.000,-0.434,-2.024,0.000>>9 X NN->房屋[4..4]-2.887<<0.000,-0.434,-5.774,0.000>>
每一行代表一个假设,这是最佳翻译推导的一部分。每行(以第一行为例)中的信息如下:
- 假设数,序列标识符(
41), - 输入非终结符(
X(X)), - 输出非终结(
S公司), - 用于生成此假设的规则(
顶部->s), - 规则中输入和输出非终结符之间的对齐信息(
(1,1)), - 假设所涵盖的范围,由输入单词的位置定义(
[0..5]), - 假设的得分(
3.593), - 其成分得分(
<<...>>):- 未知词惩罚(
0), - 文字惩罚(
-2.606), - 语言模型分数(
-9.711), - 规则应用概率(
2.526)、和
- 先前的假设,即树中的子节点,该假设是基于(
20).
如您所见,这里使用的模型是一个target-syntax模型,它在目标端使用语言语法注释,但在输入端所有内容都被标记X(X).
规则表
如果我们看看字符串到树目录中,我们找到两个文件:配置文件摩西·伊尼它指向语言模型(在lm/europarl.srim.gz公司)和规则表文件规则表.
配置文件摩西·伊尼具有相当熟悉的格式。它与基于短语的模型的配置文件基本相同。下面我们将进一步详细描述图表解码器的新参数。
规则表符合规则是法老/摩西短语表的扩展,因此任何以前使用过它的人都会熟悉它。以下是一些行的示例:
gibt[X]|||给出[ADJ]|||1.0||||| ||3 5esgibt[X]|||有[ADJ]|||1.0||||| ||2 3[十] [DT][X][NN][X]| |[X][DT][X][NN][NP]| | |1.0 | | 0-0 1-1 | | |2 4[十] [DT][X][ADJ][X][NN][X]||[X][DT][X][ADJ][X][CN][NP]||1.0||0-0 1-12-2|||5 6[X] [V][X][NP][X]||[X][V][X][NP][VP]|||1.0||0-0 1-1 |||4 3
规则表中的每一行描述一条翻译规则。它由五个部件组成,由三根杆隔开:
- 源字符串和源左侧,
- 目标字符串和目标左侧,
- 分数:这里只使用一个,但通常使用多个分数,
- 非终结符之间的对齐(使用以0开头的单词位置作为源-目标),以及
- 源短语和目标短语的频率计数(用于调试;在解码期间不使用)。
格式与Hiero格式略有不同。例如,Hiero规则
[十] ||[X,1]跟踪'|||[X,1]추적'\||| 0.727273 0.444625 1 0.172348 2.718
格式为
[十] [X]跟踪'[X]|||[X][X]추적'[X]\||| 0.727273 0.444625 1 0.172348 2.718 ||| 0-0 ||| 2 3
字符串到树语法中的语法规则:
[NP]|||全部[NN,1]|||[NN\||| 0.869565 0.627907 0.645161 0.243243 2.718
格式为
所有[X][NN][X]|||모든[X][NN][NP]\||| 0.869565 0.627907 0.645161 0.243243 2.718 ||| 1-1 ||| 23 31
该格式还可以表示树到字符串规则,该规则没有Hiero等效规则:
所有[NN][X][NP]|||모든[NN][X][X]\||| 0.869565 0.627907 0.645161 0.243243 2.718 ||| 1-1 ||| 23 31
通常,您还需要以下“粘合”规则:
<s> [X][s]</s>[X]|||<s>[X][s]</s>[TOP]||1.0|||1-1<s> [X][NP]</s>[X]|||<s>[X][NP]</s>[TOP]||1.0|||1-1<s> [X]|||<s>[s]|||1|||[十] [S]</S>[X]|||[X][S]</S>[S]||1||0-0[十] [S][X][X][X]||[X][S][X][X][S]|||2.718|||0-0 1-1
最后,这条相当技术性的规则只适用于除句子边界标记外涵盖所有内容的跨接<秒>和</s>。它完成了一个句子跨度的翻译(S公司).
更多示例
表中的第二条规则,我们刚刚看了一下,允许一些非常有趣的东西:非连续短语的翻译:马赫数X auf.
让我们用一个示例句子的解码器来尝试一下:
%echo'er macht das tor auf'|moses_chart-f moses.ini-T跟踪文件;猫追踪弹[...]14 X顶部-><s>s</s>(1,1)[0..6]-7.833<<0.000,-2.606,-17.163,1.496>>1313 X S->NP VP(0,0)(1,1)[1..5]-6.367<<0.000,-1.737,-14.229,1.496>>2 112 X NP->he[1..1]-1.064<<0.000,-0.434,-2.484,0.35711 X VP->打开NP(1,1)[2..5]-5.627<<0.000,-1.303,-12.394,1.139>>1010 X NP->DT NN(0,0)(1,1)[3..4]-3.154<<0.000,-0.869,-7.224,0.916>>6 76 X DT->[3..3]0.016<<0.000,-0.434,-0.884,0.916>>7 X NN->门[4..4]-3.588<<0.000,-0.434,-7.176,0.000>>他打开了大门
你可以看到规则在假设创建中的创建应用11。它生成打开NP覆盖输入范围[2..5]通过使用假设10,覆盖跨度[3..4].
注意,这个规则允许我们做一些在简单的基于短语的模型中不可能做的事情。摩西中基于短语的模型要求所有短语都是连续的,它们不能有空格。
最后一个示例说明了在基于树的模型中如何重新排序:
%echo'ein haus ist das'|moses_chart-f moses.ini-T跟踪文件;猫追踪弹41 X顶部-><s>s</s>(1,1)[0..5]-2.900<<0.000,-2.606,-9.711,3.912>>1818 X S->NP V NP(0,2)(1,1)(2,0)[1..4]-1.295<0.000,-1.737,-6.501,3.912>>11 5 811 X NP->DT NN(0,0)(1,1)[1..2]-2.698<<0.000,-0.869,-5.396,0.000>>2 42 X DT->a[1..1]-1.012<<0.000,-0.434,-2.024,0.000>>4 X NN->房屋[2..2]-2.887<<0.000,-0.434,-5.774,0.000>>5 X V->为[3..3]-1.267<<0.000,-0.434,-2.533,0.000>>8 X NP->本[4..4]0.486<<0.000,-0.434,-1.330,2.303>>这是一所房子
句子中的重新排序发生在假设18生成。非词汇规则S->NP V NP以相反的顺序获取底层子节点((0,2) (1,1) (2,0)).
不允许任意重新排序,这在短语模型中可能是这样的。重新排序必须受到翻译规则的激励。如果模型使用实际语法,则必须有语法理由来重新排序。
解码器参数
解码时最重要的考虑是速度和质量的权衡。如果你想赢得比赛,你需要尽可能高的质量,即使翻译2000个句子需要一周的时间。如果你想提供在线服务,你知道当用户不得不等待一秒钟以上时,他们会变得不耐烦。
光束设置
图表解码器使用立方体剪枝实现CKY解码。后者意味着每个跨度只生成固定数量的假设。此数字可以通过选项更改立方体修剪pop-limit(或短煤层气开采). 默认值为1000,数字越大,解码器的速度越慢,但质量可能会更好。
另一个直接影响速度的设置是为每个输入左侧考虑的规则数。它可以设置为ttable-limit公司.
限制重新订购
图表解码期间填充的跨距数与句子长度成二次关系。但情况变得更糟了。组合成一个跨度的跨度数量与二进制规则的句子长度成线性关系,与三元规则的二次关系,等等。简而言之,长句成了一个问题。一个极端的解决方案是将内部跨度的大小设置为最大值。
这听起来有点极端,但对于非句法模型来说确实有些道理。重新排序在基于短语的模型和非语法树模型(更好地称为基于层次短语的模型)中是有限的,应该出于同样的原因限制重新排序:它们只是不太擅长远距离重新排序。
跨距大小的限制可以用图表最大跨度。实际上,它的默认值是10对于语法模型来说,这不是一个有用的设置。
处理未知单词
在target-syntax模型中,只需逐字复制到输出中的未知单词需要获得非终结符标签。实际上,生词往往是开放类单词,很可能是名称、名词或数字。使用选项未知-lhs您可以指定一个文件,其中包含成对的非终结符标签及其每行的概率。
或者,我们还可以通过稀疏特征对未知单词的非终结符选择进行建模,并通过MIRA或PRO优化其成本。这是通过在解码期间放松标签匹配约束来实现的,以允许软匹配,并允许未知单词扩展到任何非终结符。要激活此功能:
use-unknown-word-soft-matches=true(在EMS配置中)-unknown-word-label FILE1-unknown word-soft-matches FILE2(在train-model.perl中)
技术设置
参数非端子用于指定特权非终端。这些用于未知单词(除非存在未知单词标签文件),并在未指定时定义输入端的非终结符标签。
通常,我们要考虑所有可能适用的规则。然而,由于最大短语长度太大,规则表太多,并且没有规则表限制,这可能会激增。考虑的规则数量可以限制为规则限制。默认值为5000。
培训
简而言之,训练使用与基于短语的模型相同的训练脚本。运行时列车模型.perl,您必须指定其他参数,例如。-分层胶粒仪。通常还可以使用-最大长度5.
就是这样。
培训参数
关于您可能希望在模型中包含的规则类型,还有许多其他决定。这通常是一种大小/质量权衡:允许更多的规则类型会增加规则表的大小,但会产生更好的结果。较大的规则表对内存使用和解码器速度有负面影响。
创建规则表有两个部分:规则提取和规则评分。第一个可以用参数修改--extract options=“…”属于列车模型.perl。第二个带有--得分选项=“…”.
以下是提取选项:
--仅限Direct:仅创建具有直接条件概率的模型p(f | e)而不是默认的直接和间接(p(f | e)和p(e | f)).--最大跨度尺寸:规则的最大跨度大小。默认值为15.--MaxSymbols源大小和--最大符号目标大小:虽然可以从大范围中提取规则,但大部分规则可能会被用非终结符替换的子短语删除。因此,实际符号(保留非终端和单词)会减少。默认的最大符号数为5对于源端,实际上是无限的(999)针对目标方。--MinWords大小:规则中的最小字数。默认值为1,这意味着每个规则中必须至少包含一个单词。如果要允许非词法规则,请将其设置为零。您不希望对层次模型执行此操作。--仅允许未对齐的单词:这与上述有关。规则中可能包含单词,但这些单词可能是未连接的未对齐单词。默认情况下,至少需要一个对齐的单词。使用此选项,将删除此要求。--最大非终端尺寸:规则右侧的非终结符数。这对非终端规则的数量有影响。默认情况下只生成二进制规则,因此设置为2.--最小孔源尺寸和--最小孔目标尺寸:当子短语被非终结符替换时,我们可能需要这些子短语的最小大小。默认值为2在源端,以及1(无限制)。--不允许NonTermConsecTarget和--非术语ConsecSource。我们可能希望限制规则中是否可以有相邻的非终结符。在分层模型中,解码会产生不良影响,从而允许源端的相邻非终端。默认设置是不允许这样做——这在目标端是允许的。这些开关覆盖默认值。--无分数计数:对于任何给定的源范围,可以生成任意数量的规则。默认情况下,分配分数计数,所以这些规则的概率加起来等于一。此选项将为每个规则计数一个。--无非术语首字:不允许规则以非终结符开头。
收集规则后,必须将规则文件及其计数转换为概率模型。这称为规则评分,还有一些其他选项:
--仅限Direct:仅估计直接条件概率。请注意,需要为规则提取和规则评分指定此选项。--诺莱克斯:只包括规则级别的条件概率,不包括词汇分数。--古德图灵:使用良好的图灵折扣来减少实际账户。这是一件好事,好好利用它。
训练语法模型
训练层次短语模型,即不带句法注释的基于树的模型,是非常直接的。在源端或目标端向规则添加语法标签并不复杂。主要障碍是获得注释。这需要一个语法分析器。
语法注释是通过用语法标签注释所有训练数据(输入端或输出端,或两者)来提供的。用于此操作的格式使用XML标记。这里有一个例子:
<tree label=“NP”><tree label=“DET”></tree>\<tree label=“NN”>cat</tree></tree>
所以,成分被一个开口和一个闭口所包围<树>标签,标签中提供了参数标签。XML标记还允许在其他位置放置标记,只要跨度提供了参数:
<tree label=“NP”span=“0-1”/>\猫
在使用语法信息注释训练数据后,您可以简单地运行列车模型.perl和以前一样,除了开关--源-语法或--目标-语法(或两者)必须设置。
您还可以更改某些提取设置,例如--最大跨度999.
批注包装
为了获得语法注释,您可能会使用第三方解析器,该解析器具有自己的特殊输入和输出格式。您需要编写一个包装器脚本,将其转换为语法树的Moses格式。
我们提供包装器(英寸脚本/培训/包装器)用于以下解析器。
- 比特率可从慕尼黑大学。包装是
解析-de-bitpar.perl
- 柯林斯解析器可从以下位置获得麻省理工学院。包装是
parse-en-colins.perl
如果您为公开可用的解析器编写了自己的包装器,请与我们共享!
放松分析
由于每个非终结符必须对应于语法树中的一个实际非终结符,因此语法注释的使用对可提取的规则数量造成了严格限制。
最近的研究提出了对这一约束的一些放松。程序松弛解析(英寸训练/短语摘录)实现了两种语法松弛:二值化和Zollmann和Venugopal在语法增强机器翻译(SAMT)标签下提出的方法。
熟悉解析中二值化语法概念的读者需要注意:我们在这里讨论的是修改解析树,这会改变提取语法的功能,而不是将二值化作为解码过程中的优化步骤。
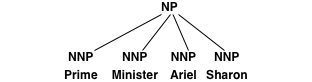
其思想如下:如果训练数据包含一个子树,例如
那么就不可能为提取翻译规则阿里尔·沙龙没有额外的句法上下文。回想一下,每个规则都必须匹配一个句法成分。
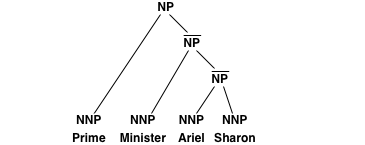
放松解析树的思想是添加额外的内部节点,从而可以提取额外的规则。例如,left-binarization添加了两个额外的节点,并将子树转换为:
带有标签的附加节点^NP公司允许直接提取翻译规则(当然,除非单词对齐不提供一致对齐)。
程序松弛解析允许以下树转换:
--左侧二值化和--右二值化:按上述示例添加内部节点。右支化创建右支树。--SAMT 1号机组:将相邻的子节点对组合为标记,例如DET+ADJ公司。也是除第一个子节点以外的所有节点(NP\\DET公司)除了最后一个孩子(NP/NN公司)已添加。--SAMT 2:组合任何相邻节点对,而不仅仅是子节点,例如。,副总裁兼首席执行官.--SAMT 3号机组:未实现。--SAMT 4号机组:如上所述,但另外,每个以前未标记的节点都标记为失败,因此语法约束上没有语法约束。
请注意,您也可以同时使用--左侧二值化和--右二值化注意,在这种情况下,与所有SAMT松弛一样,生成的注释不再是树,因为没有一组规则应用程序生成该结构(现在称为林)。
这里有一个示例,解析松弛对提取的规则数量有什么影响(英语-德语新闻评论,使用Bitpar表示德语,没有英语语法):
| 放松设置 | 规则的数量 |
| 没有语法 | 59,079,493 |
| 基本语法 | 2,291,400 |
| 左首字母 | 2914348个 |
| 右旋的 | 2,979,830 |
| SAMT 1号机组 | 8,669,942 |
| SAMT 2 | 35,164,756 |
| SAMT 4号机组 | 131,889,855 |
On-Disk规则表
规则表可能太大,无法放入机器的RAM中。不需要将规则加载到内存中,也可以将规则表留在磁盘上,并根据需要检索规则。
这在中进行了描述On-Disk短语表.
在非终端符号(例如CCG)中使用元符号
通常,语法形式主义将使用元符号的一部分符号,这些元符号表示SCFG规则表中的非终结边界,以及粘合语法。例如,在组合范畴语法(CCG,Steedman,2000)中,习惯上是通过将语法特征放在方括号内的非终结符之后来表示语法特征,如S[dcl](陈述句)与S[q](疑问句)。
尽管这样的注解可能有助于区分好的翻译和坏的翻译,但包括非终结符中的方括号本身可能会使摩西感到困惑。一些用户报告说,类别符号在转换为磁盘表示形式后(可能在其他情况下,这是一个尚未解决的问题)被破坏(通过在方括号中拆分它们)。解决此问题的一种方法是使用不属于语法文件元语言的符号转义方括号,例如使用下划线符号:
S[dcl]=>S_dcl_
和
S[q]=>S_q_
之前提取语法。这应该在提及此类语法类别的所有数据或表中完成。如果自动提取规则表,则只需转义<tree label=“…”…>中的类别提供给培训脚本的标记。如果您滚动自己的规则表(或使用未知-lhs文件),您应该确保它们被正确转义。
不同类型的语法模型
字符串到树
目前,大多数基于SCFG的机器翻译解码器都设计为使用基于层次短语的语法(Chiang,2005)或句法语法。Joshua、cdec和Jane是一些拥有此类解码器的开源系统。
基于短语的层次语法在其他地方有很好的描述,所以我们不在这里详细介绍。简言之,非终结语没有任何语言上的标记。按照惯例,非终端被简单地标记为X,例如。
X-->顺序X1|||X轴1
通常,需要一组粘合规则来确保解码器始终输出一个答案。按照惯例,粘合规则的非终结符标记为S,例如。
S--><S>|||<S>S-->X1</s>|||X1</s>S-->X1X(X)2|||X(X)1X(X)2
在句法模型中,非终结符被标记为语言上的动标,如“NOUN”、“VERB”等。例如:
DET-->命令|||ADJ-->kleines|||小
这些标签通常是通过解析训练语料库的目标端获得的。(然而,也可以使用源端的解析,该解析已投射到目标端(Ambati和Chen,2007))。
使用此模型时,解码器的输入是传统字符串,如基于短语和基于层次短语的模型。输出是一个字符串。然而,也可以获得输出(目标)的CFG树派生(在Moses中使用-T参数),该树中的非终端将被标记为具有语言动机的标签。
由于这些原因,摩西社区和其他地方的许多人将这些语法模型称为“目标”语法模型或“字符串到树”模型。(ISI的一些人的论文推翻了这种命名惯例,因为他们坚持噪音通道框架)。
字符串到树模型的实现相当标准,并且在不同的开源解码器(如Moses、Joshua、cdec和Jane)中类似。
在可下载的示例模型.
模型的输入是字符串:
das ist ein kleines haus公司
输出字符串为
这是一所小房子
它生成的目标树是
(TOP<s>(s(NP this)(VP(V is)(NP(DT a)(ADJ small)(NN house))))
RECAP-输入是一个字符串,输出是一个带有语言移动标签的树。
树到字符串
与串对树模型不同,树对串模型在不同的解码器之间没有标准化。本节描述了Moses的实现。
输入树表示
解码器的输入是一个解析树,而不是字符串。对于Moses来说,解析树应该使用XML格式化。解码器将解析树转换为带注释的字符串(图表?)。图表中的每个span都使用解析树中的非终结符进行标记。例如,输入
<tree label=“NP”><tree label=“DET”>猫</tree></tree>
转换为带注释的字符串
猫-检测-NN------NP公司-----
为了支持更简单的粘合规则,还为注释字符串中的每个span添加了非终结符“X”。因此,上面的输入实际上转换为:
猫-数据元素--NN----X----X------NP公司----------X(X)-----
翻译规则
在解码期间,跨越句子中子字符串的规则的非终结符必须与注释字符串上的标签匹配。例如,以下规则可以应用于上述句子。
NP-->katze |||死katzeNP-->NN1|||序号NN1NP-->检测1猫||DET1卡茨NP-->检测1NN公司2|||DET公司1NN公司2
然而,这些规则不能匹配一个或多个非终端。
VB-->凯特|||死凯特NP-->ADJ1|||ADJ命令1NP-->调整1猫|||ADJ1卡茨ADV-->ADJ公司1NN公司2|||ADJ公司1NN公司2
因此,树到字符串模型中的转换规则中的非终结符充当了可以应用规则的约束。这个约束是对非终端的常规作用的补充。
摩西解码器目前独有的一个功能是能够区分这两个角色。所有转换规则中的每个非终结符都由两个标签表示:
- 将规则约束到输入解析树的源非终结符
- 具有正常解析角色的目标非终结符。
当我们需要区分源和目标非终结符时,转换规则的编写方式如下:
NP-->NN1|||X-->顺序X1
该规则表明,非终结符应跨越输入文本中的NN成分,而整个规则应跨越NP成分。此规则中的目标非终结符都是X,因此,此规则将被视为树对字符串语法的一部分。
(使用这种符号可能是错误的,因为源句子没有正确解析-请参阅下一节。将摩西树到字符串语法表示为分层语法可能会更好,并添加约束。例如:
X-->X1|||顺序X1|||LHS=NP,X_1=NN
然而,这可能会更加令人困惑,所以我们现在将坚持我们的约定。)
回顾——摩西的语法规则中,每个非终结语都有两个标签;一个用于将非终结符约束到输入解析树,另一个用于解析。
后果
1.摩西解码器总是检查源代码的非终结符,即使是使用字符串对字符串或字符串对树语法进行解码时也是如此。例如,在检查是否可以应用以下规则时
X-->顺序X1|||X轴1
解码器将检查RHS非终结符和整个规则是否跨越输入解析成分X。因此,即使在使用字符串到字符串或字符串到树语法进行解码时,也需要在每个输入范围中添加X非终结符。例如,输入字符串猫必须注释如下
猫--X----X-------X(X)-----
允许使用字符串对字符串或字符串对树语法对字符串进行解码。
2.语言衍生的非终结语标签,如NP、VP等,与非语言动机的X标签没有区别。它们都可以在一种语法中使用,甚至可以在一条翻译规则中使用。在(Hoang和Koehn,2010)和Hieu Hoang的论文
3.翻译规则中的源非终结符仅用于约束输入解析树,而不是用于解析。例如,如果输入解析树是
(副总裁(NP(PRO he))(VB gos))
树到字符串的规则是:
专业-->he|||X-->ilVB-->开始|||X-->va副总裁-->NP1VB(虚拟语言)2|||X-->X1X(X)2
这将创建有效的翻译。然而,第一条规则将单词“he”的跨度标记为PRO,第三条规则将其标记为NP。Hieu的论文第4.2.11节对此进行了详细说明。
4.为了避免上述情况并确保始终对源跨度进行一致标记,只需将非终端标签投影到源和目标。例如,更改规则
副总裁-->NP1VB(虚拟语言)2|||X-->X1X(X)2
到
副总裁-->NP1VB(虚拟语言)2|||副总裁-->NP1VB(虚拟语言)2
文本规则表格式
摩西规则表的格式与希罗(Hiero)、约书亚(Joshua)和cdec使用的格式不同,经常引起混淆。我们将尝试在本节中解释原因。
该格式源自法老/摩西基于短语的格式。在此格式中,转换规则
a b c-->d e f,带单词对齐a1,一个2…和概率p1,第页2, ...
格式为
b c d e f p1第页2…||a1一2...
对于分层pb规则,
X-->X1b c X号2|||日期f X2X(X)1
Hiero/Joshua/cdec格式为
X||a[X,1]b c[X,2]|||d f[X,2][X,1]||p1第页2...
摩西格式是
a[X][X]b c[X][X][X]| | d e f[X]1第页2... ||| 1-4 4-3
对于字符串到树规则,
副总裁-->a X1b c X号2|||NP的数据2佐剂病1
摩西的格式是
a[X][ADJ]b c[X][PP][X]| | d e f[X][NP][X][ADJ][VP]| | | p1第页2... ||| 1-4 4-3
对于树到字符串规则,
副总裁-->ADJ1b c名词短语2|||X-->d e f X2X(X)1
摩西格式是
a[ADJ][X]b c[NP][X][VP]||| d e f[NP][X][ADJ][X][X]||p1第页2... ||| 1-4 4-3
Hiero/Joshua/cdec和Moses格式之间存在差异的主要原因如下:
- 文本规则表应易于转换为二进制磁盘格式。我们已经在社区中看到,这允许在解码期间使用更大的模型,甚至在内存限制的服务器上。为了提高转换效率,文本规则表必须具有以下属性:
- 对于每个规则,第一列(“源”列)中的终端和非终端序列应与解码器将执行的查找序列匹配。
- 可以对文件进行排序,以便第一列按字母顺序排列。解码器需要查找每个规则右侧的目标非终端,因此第一列由源终端和非终端组成,和从右侧瞄准非终端。
- 短语概率计算应高效执行。要计算p(t|s)=count(t,s)/count(s),提取文件必须按连续顺序排序,以便执行每个计数并用于计算概率,然后立即丢弃以节省内存。类似地,p(s|t)=count(t,s)/count(t)
Hiero/Joshua/cdec文件格式对于层次模型来说足够了,但对于Moses支持的各种语法模型来说就不够了。