背景
统计机器翻译作为一个研究领域,始于20世纪80年代末IBM的Candide项目。IBM最初的方法是将单个单词映射到单词,并允许删除和插入单词。
最近,各种研究人员都表明,短语翻译可以提高翻译质量。基于短语的机器翻译可以追溯到Och的对齐模板模型,该模型可以重新构建为短语翻译系统。其他研究人员使用短语翻译来增强他们的系统,例如Yamada,他在基于句法的模型中使用短语翻译。
Marcu为短语翻译引入了联合概率模型。目前,大多数有竞争力的统计机器翻译系统都使用短语翻译,例如CMU、IBM、ISI和Google系统等等。基于短语的系统在最近的一次国际机器翻译比赛中取得了领先地位(DARPA TIDES机器翻译评估2003-2006年中英文和阿拉伯语-英语)。
当然,还有其他方法可以进行机器翻译。大多数商业系统使用转移规则和丰富的翻译词典。20世纪80年代,机器翻译研究的重点是基于转换的系统,20世纪90年代,机器译研究的重点则是基于知识的系统,这些系统使用语际表示作为输入和输出之间的中间步骤。
还有其他方法可以进行统计机器翻译。在构建基于语法的模型方面有一些努力,这些模型要么使用语法分析器生成的实际语法树,要么使用由语法重新排序模式驱动的树传输方法。
我们在这里提出的基于短语的统计机器翻译模型定义如下Koehn等人(2003年)。另请参阅的描述Zens(2002)基于短语的替代方法在创建短语翻译表的方式上有所不同,我们将在下面详细讨论。
型号
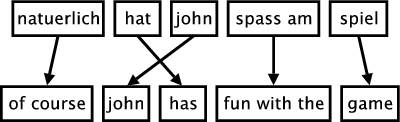
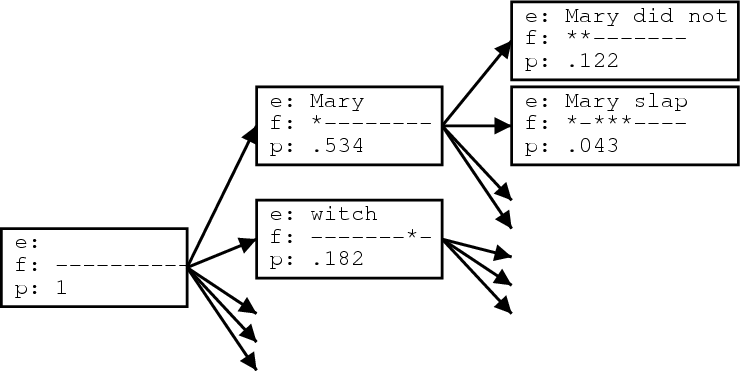
下图说明了基于短语的翻译过程。输入被分割成多个连续单词序列(所谓的短语). 每个短语都被翻译成英语短语,输出中的英语短语可以重新排序。
在本节中,我们将正式定义基于短语的机器翻译模型。短语翻译模型基于噪声信道模型。我们使用贝叶斯规则来重新表述翻译外国句子的翻译概率(f)翻译成英语电子作为
argmax(最大值)电子第页(电子|(f))=argmax(最大值)电子第页((f)|电子)第页(电子)
这允许一个语言模型p(电子)和一个单独的翻译模型p((f)|电子).
在解码过程中,外国输入句子(f)被分割成一系列我短语(f)1我.我们假设所有可能的分段都有统一的概率分布。
每个外国短语(f)我在里面(f)1我翻译成英语短语电子我英语短语可以重新排序。短语翻译由概率分布φ建模((f)我|电子我). 回想一下,由于贝叶斯规则从建模的角度来看,转换方向是颠倒的。
英语输出短语的重新排序由相对失真概率分布d(start我,结束i-1号机组),从哪里开始我表示翻译为我第个英语短语,和结尾i-1号机组表示翻译为(i-1)第个英语短语。
我们使用一个简单的畸变模型d(开始我,结束i-1号机组) = α|启动我-结束i-1号机组-1|参数α的适当值。
为了校准输出长度,除了三角语言模型p之外,我们为每个生成的英语单词引入一个因子ω(称为单词成本)LM公司。这是一种优化性能的简单方法。通常,该系数大于1,偏向于更长的输出。
总之,最好的英语输出句子电子最好的给定一个外国输入句(f)根据我们的模型是
电子最好的=argmax(最大值)_电子第页(电子|(f))=最大参数电子第页((f)|电子)p_LM(磅)(电子) ω长度(电子)
其中p((f)|电子)分解为
第页((f)1我|电子1我) = Φi=1我φ((f)我|电子我)d(开始我,结束i-1号机组)
单词对齐方式
到目前为止,在描述基于短语的翻译模型时,我们没有讨论如何获取模型参数,特别是将外来短语映射为英语短语的短语概率翻译表。
最近发表的从平行语料库中提取短语翻译表的方法都是从单词对齐开始的。单词对齐是一个活跃的研究课题。例如,这个问题是最近一次共同任务的焦点数据驱动机器翻译车间参见Och和Ney的系统比较(计算语言学,2003)。
此时,建立单词对齐的最常用工具是使用工具箱GIZA公司++此工具包是开始统计机器翻译研究的原始IBM模型的实现。然而,这些模型有一些严重的缺陷。最重要的是,他们最多只允许一个英语单词与每个外国单词对齐。为了解决这个问题,需要应用一些转换。
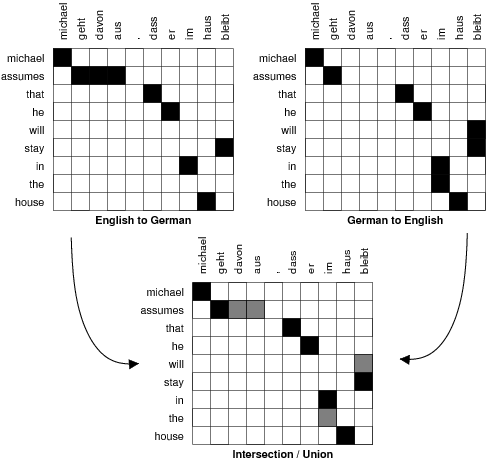
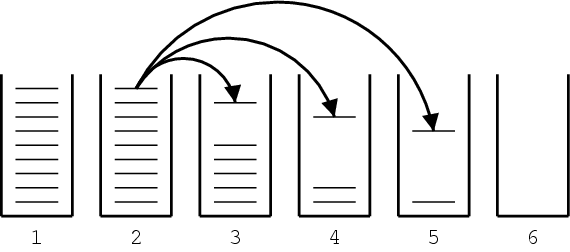
首先,平行语料库是双向对齐的,例如,西班牙语对英语和英语对西班牙语。这将生成必须协调的两个单词对齐。如果我们将两条路线相交,我们将得到高置信度对齐点的高精度对齐。如果我们将这两种对齐方式结合起来,我们将得到一个具有附加对齐方式的高召回对齐方式点。请参见下图以获取图示。
研究人员在方法上有所不同。我们在下面描述了细节。
短语翻译的学习方法
最近提出的大多数方法都使用单词对齐来学习短语翻译表。我们在本节中讨论了三种这样的方法和一个例外。
Marcu和Wong
首先,例外:Marcu和Wong(EMNLP,2002)提出直接在平行语料库中建立短语对应关系。为了学习这种对应关系,他们引入了一种基于短语的联合概率模型,该模型在平行语料库中同时生成源句子和目标句子。
Marcu和Wong框架中的期望最大化学习产生了(i)联合概率分布φ(电子,(f)),它反映了短语电子和(f)是翻译等价物;(ii)和联合分配d(i,j),它反映了短语在位置处的概率我被翻译成短语j个.
为了在我们的框架中使用这个模型,我们只是将Marcu和Wong(EMNLP,2002)估计的联合概率边缘化为条件概率。注意,这种方法与Marcu和Wong自己采取的方法一致,他们在解码过程中使用条件模型。
Och和Ney
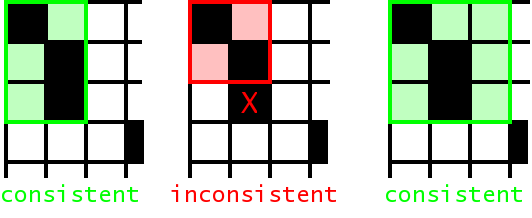
Och和Ney(计算语言学,2003年)提出了一种启发式方法来改进从GIZA++获得的对齐。至少保留两条路线交点的所有路线点。最多考虑两条路线的结合点。要对此进行说明,请参见下图。交点为黑色,并集中的其他点为灰色。
Och和Ney通过扩展启发式探索交集和并集之间的空间从交点开始并添加其他对齐点。要添加哪些点的决定可能取决于一些标准:
- 潜在对齐点存在于哪个对齐中?外国英语还是外国英语?
- 潜在点邻居是否已建立点?
- 做邻近的是指直接相邻(块距)还是对角相邻?
- 到目前为止,潜在点连接的英语或外来词是否未对齐?两者都没有对齐吗?
- 潜在点的词法概率是多少?
Och和Ney(计算语言学,2003)对其改进方法中添加了哪些对齐点的描述模棱两可。我们为摩西重新实现了他们的方法,所以我们将在这里描述这个解释。
我们的启发式过程如下:我们从两个单词对齐的交集开始。我们只添加存在于两个单词对齐的并集中的新对齐点。我们还总是要求一个新的对齐点连接至少一个以前未对齐的单词。
首先,我们只扩展到直接相邻的对齐点。我们从对齐矩阵的右上角开始检查潜在点,检查第一个英语单词的对齐点,然后继续检查第二个英语单词,依此类推。
这是反复进行的,直到无法再添加对齐点。在最后一步中,我们添加不相邻的对齐点,其他方面的要求相同。
我们收集所有与单词对齐一致的对齐短语对:合法短语对中的单词只相互对齐,而不与外部单词对齐。双语短语集英国石油公司可以正式定义为(Zens,KI 2002):
英国石油公司(f)1J型,电子1J型,A)={(fj个j+米,电子我i+n(输入/输出))}:对于A中的所有(i',j'):j<=j'<=j+m<->i<=i'<=i+n
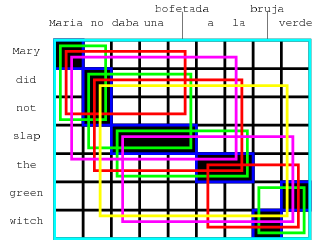
有关这意味着什么的一些示例,请参见下图。短语对中单词的所有对齐点都必须位于短语对齐框中。在短语对齐中使用未对齐的单词是可以的,即使是在边界处。
下图显示了根据此定义收集的所有短语对,用于运行示例中的对齐。
(玛丽亚、玛丽),(不,没有),(巴掌,达巴·乌纳·博费塔达),(a la,the),(巫婆,巫婆),(佛得角绿),(玛丽亚没有,玛丽亚没有),(没有达巴·乌纳·博费塔达,没有打耳光),(daba una bofetada a la,拍一下),(佛手柑,绿色女巫),(Maria no daba una bofetada,Mary没有扇耳光),(没有daba una bofetada a la,没有打耳光),(绿衣女巫拉布鲁娅·维德)(玛丽亚没有扇耳光,玛丽没有扇耳光),(daba una bofetada a la bruja verde,扇绿色女巫一巴掌),(没有daba una bofetada a la bruja verde,没有扇绿色女巫一巴掌),(玛丽亚·诺·达巴·乌娜·波菲塔达(Maria no daba una bofetada a la bruja verde),玛丽亚没有扇绿色女巫一巴掌)
给定所收集的短语对,我们通过相对频率φ估计短语翻译概率分布((f)|电子)=计数((f),电子)∑(f)计数((f),电子)
虽然词法加权解决了数据稀疏的问题,但没有执行平滑。有关更多详细信息,请参阅我们关于基于短语的翻译的论文(Koehn at al,HLT-NAACL 2003)。
蒂尔曼
Tillmann(EMNLP,2003)提出了这种方法的一种变体。他从基于两个GIZA++对齐的交集的短语对齐开始,并使用并集点来扩展这些对齐。有关详细信息,请参阅他的演示。
Venugopal、Zhang和Vogel
Venugopal等人(ACL 2003)还允许收集单词对齐违反的短语对。他们引入了一些评分方法,考虑了单词对齐、词汇翻译概率、短语长度等方面的一致性。
Zhang et al.(2003)提出了一种基于单词对齐的短语对齐方法,并尝试找到句子对的唯一分段,这是由Marcu和Wong直接完成的。这使他们能够估计联合概率分布,而联合概率分布可以被边缘化为条件概率分布。
Vogel等人(2003)回顾了这两种方法,并表明不同方法生成的组合短语表可以改善结果。
解码器
本节从更理论的角度描述摩西解码器。解码器最初是为Marcu和Wong提出的短语模型开发的。当时,只有贪婪的爬山解码器可用,这对于我们的名词短语翻译工作来说是不够的(Koehn,博士,2003)。
解码器实现了波束搜索,与Tillmann(博士,2001)和Och(博士,2002)的工作大致相似。事实上,通过将Och的对齐模板模型重新构建为短语翻译模型,解码器也适用于他的模型以及其他最近提出的短语模型。
本节首先定义转换选项的概念,描述波束搜索的基本机制及其必要组件:修剪、未来成本估算。最后,我们介绍了n个最佳列表生成的背景。
翻译选项
给定一个单词输入字符串,可以应用一些短语翻译。我们将每一个这样适用的短语翻译为转换选项。如下图所示,其中西班牙语输入句子的许多短语翻译Maria no daba uma bofetada a la bruja verde玛丽亚·诺·达巴·乌玛·波菲塔达给出了。
在进行任何解码之前,都会收集这些翻译选项。这比在解码期间查询整个短语翻译表更快。翻译选项与信息一起存储
- 覆盖的第一个外来词
- 覆盖的最后一个外来词
- 英语短语翻译
- 短语翻译概率
请注意,只有可应用于给定输入文本的翻译选项才是解码所必需的。由于整个短语翻译表可能太大而无法存储,因此我们可以限制自己使用这些翻译选项来克服这种计算问题。我们甚至可以根据需要生成短语翻译表,其中只包含给定输入文本的有效翻译选项。通过这种方式,可能永远不需要构建完整的短语翻译表(可能计算成本太高,无法生成)。
核心算法
我们开发的基于短语的解码器采用了波束搜索算法,类似于Jelinek(1998年出版的《语音识别的统计方法》一书)用于语音识别的算法。英语输出句子是以假设的形式从左到右生成的。
该过程如下图所示。从最初的假设开始,第一个扩展是外来词玛丽亚,翻译为玛丽。外来词标记为已翻译(用星号标记)。我们也可以通过翻译外来词来扩展最初的假设女巫作为女巫.
我们可以从这些扩展的假设中产生新的假设。给出第一个扩展的假设,我们通过翻译生成一个新的假设不具有没有现在是前两个外来词玛丽亚和不标记为被覆盖。根据这些假设的反向指针,我们可以阅读这个句子的(部分)翻译。
现在让我们更正式地描述光束搜索。我们在一个初始状态下开始搜索,在该状态下没有翻译任何外来输入单词,也没有生成任何英语输出单词。新状态是通过扩展英语输出来创建的,其短语翻译涵盖了一些尚未翻译的外国输入词。
新状态的当前成本是原始状态的成本乘以附加短语翻译的翻译、失真和语言模型成本。请注意,我们使用非正式概念成本与概率类似:高成本就是低概率。
每个搜索状态(假设)由
- 到最佳先前状态的反向链接(需要通过搜索状态的反向跟踪来找到句子的最佳翻译)
- 到目前为止所涉及的外来词
- 生成的最后两个英语单词(用于计算未来的语言模型成本)
- 涵盖的最后一个外文短语的结尾(计算未来失真成本所需)
- 最后添加的英语短语(从假设路径阅读译文时需要)
- 到目前为止的成本
- 对未来成本的估计(出于效率的原因预先计算和存储,详见下文的专门章节)
搜索的最终状态是涵盖所有外来词的假设。其中成本最低(概率最高)的假设被选为最佳翻译。
到目前为止描述的算法可以用于对所有可能的翻译进行穷尽搜索。在接下来的部分中,我们将描述如何通过丢弃不能成为最佳翻译路径一部分的假设来优化搜索。然后,我们引入了可比较状态的概念,这使我们能够定义一系列好的假设,并删除掉这些假设。在后面的部分中,我们将描述如何生成(近似)n个最佳列表。
重组假设
重组假设是一种减少搜索空间的无风险方法。如果两个假设一致,则可以重新组合
- 到目前为止涵盖的外来词
- 生成的最后两个英语单词
- 最后一个外文短语的结尾
如果有两条路径导致两个假设在这些属性中一致,那么我们只保留更便宜的假设,例如,到目前为止成本最低的假设。另一个假设不能成为最佳翻译的一部分,我们可以放心地放弃它。
请注意,劣等假设可能是第二好翻译的一部分。这对于生成n个最佳列表很重要。
波束搜索
虽然如上所述的假设重组减小了搜索空间的大小,但除了最短的句子外,这还不够。让我们估计在一次彻底的搜索过程中产生了多少假设(或状态)。考虑到唯一假设性质的可能值,我们可以通过N~2估计状态数的上界n个(f)|V(V)电子|2n个(f)其中n(f)是外来词的数量,|V电子|英语词汇的大小。实际上,生成的最后两个单词的可能英语单词数远小于|V电子|2主要关注的是2的指数爆炸n个(f)假设所涵盖的外来词的可能结构。请注意,这导致机器翻译问题成为NP完全问题(Knight,计算语言学,1999),因此比语音识别更难。
在我们的波束搜索中,我们比较了相同的假设数删除劣质假设。我们可以根据到目前为止每种假设的成本来判断哪些是劣质假设。然而,这通常是一个非常糟糕的标准,因为它使搜索偏向于首先翻译句子的简单部分。例如,如果有一个三个单词的外国短语可以很容易地翻译成一个普通的英语短语,那么这可能比将三个单词单独翻译成不常用的英语单词要便宜得多。搜索会倾向于用简单的部分开始句子,而折扣选项太早。
因此,我们在波束搜索中剔除假设的措施不仅包括迄今为止的成本,还包括对未来成本的估计。这种未来的成本估算应该支持已经涵盖句子中困难部分且只剩下简单部分的假设,以及先涵盖简单部分的折扣假设。我们将在下一节中描述未来成本估算的细节。
考虑到目前为止的成本和未来的成本估算,我们可以删掉那些不在光束范围内的假设。光束大小可以通过阈值和直方图修剪来定义。相对阈值剔除了概率小于最佳假设因子α的假设(例如,α=0.001)。直方图修剪保持一定数量n个假设(例如。,n个= 100).
请注意,这种修剪并不是无风险的(与我们前面描述的重组相反)。如果未来的成本估算不充分,我们可以删去通往最佳评分翻译的假设。在波束搜索的特定版本中,a*搜索要求未来的成本估算为_admissible_,这意味着它永远不会高估未来的成本。使用最佳优先搜索和可接受的启发式可以实现无风险的修剪。然而,在实践中,这种类型的修剪并不能充分减少搜索空间。在任何一本好的人工智能教科书中都可以看到更多关于搜索的信息,比如Russel和Norvig的《人工智能:现代方法》(Artificial Intelligence:A Modern Approach)。
下图给出了我们用于波束搜索的算法的伪代码。对于涵盖的每个外来词数量,都会创建一个假设堆栈。初始假设放在假设堆栈中,没有包含任何外来词。从这个假设开始,新的假设是通过致力于涵盖以前未使用过的外来词的短语翻译而产生的。每个派生的假设都根据其包含的外来词的数量放在一个堆栈中。
初始化假设堆栈[0.nf];创建初始假设hyp_init;添加到堆栈假设堆栈[0];对于i=0到nf-1:对于假设中的每个炒作Stack[i]:对于可以从hyp派生的每个new_hyp:nf[new_hyp]=new_hyp覆盖的外来词数量;将new_hyp添加到假设堆栈[nf[new_hyp]];修剪假设堆栈[nf[new_hyp]];在假设堆栈中找到最佳假设best_hyp[nf];输出通向besthyp的最佳路径;
我们继续研究这些假设堆栈,研究堆栈中的每个假设,为该假设推导新的假设,并将其放入适当的堆栈中(参见下图中的说明)。在将新假设放入堆栈后,如果堆栈变得太大,则可能需要通过阈值或直方图修剪来修剪堆栈。最终,覆盖所有外来词的最佳假设是最佳翻译的最终状态。我们可以按照每个假设中的后面链接读出翻译的英文单词。
未来成本估算
回想一下,为了从光束中排除假设,我们不仅要考虑到目前为止的成本,还要考虑到未来成本的估计。虽然可以为每个假设计算出最便宜的未来成本,但这在计算上过于昂贵,以至于无法实现波束搜索的目的。
未来的成本取决于尚未翻译的外来词。在基于短语的模型框架中,不仅可以单独翻译单个单词,还可以将连续的单词序列作为短语进行翻译。
每个这样的翻译操作都会带来翻译成本、语言模型成本和失真成本。对于我们未来的成本估算,我们只考虑翻译和语言模型成本。语言模型成本通常由三角语言模型计算。然而,对于翻译操作,我们不知道前面的英语单词。因此,我们仅通过计算生成的英语单词的语言模型分数来估算此成本。这意味着,如果只生成一个英语单词,我们就取其单字概率。如果生成两个单词,我们取第一个单词的单格概率和第二个单词的双格概率,依此类推。
对于一系列外来词,存在多个重叠的翻译选项。我们刚刚描述了如何计算每个翻译选项的成本。翻译外文单词序列最便宜的方法包括最便宜的翻译选项。我们通过每个选项的成本乘积来近似计算通过转换选项的路径的成本。
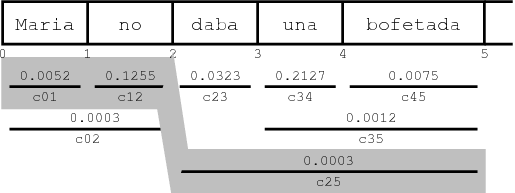
为了说明这个概念,请参阅下图。翻译选项涵盖不同的连续外国单词,并带有估计成本cij公司。通过转换选项序列的阴影路径的成本为c01c(c)12c(c)25= 1.9578 * 10-7.
动态编程可以快速计算一系列外来词的最便宜路径。还要注意的是,如果到目前为止尚未涵盖的外来词是两个(或更多)不相连的外来词序列,那么组合成本就是每个相邻序列成本的乘积。因为只有n(n+1)/2的连续序列n个换句话说,这些序列的未来成本估算可以很容易地为每个输入句子预先计算和缓存。然后可以通过查表快速查找假设的未来成本。与动态计算未来成本相比,这具有相当大的速度优势。
N个最佳列表生成
通常,我们期望解码器根据模型为给定输入提供最佳翻译。但对于某些应用程序,我们可能还对次佳翻译、次佳翻译等感兴趣。
语音识别中的一种常见方法,也是机器翻译中出现的一种方法,是首先使用机器翻译系统(如解码器)作为基本模型,为每个输入句子生成一组候选翻译。然后,使用其他功能重新搜索这些翻译。
n-best列表是表示多个候选翻译的一种方法。这样一组可能的翻译也可以用单词图(Ueffing等人,EMNLP 2002)或解析树上的森林结构(Langkilde,EACL 2002)表示。这些替代数据结构允许更紧凑地表示更大的候选集。然而,在此类数据结构上检测和评分全局属性要困难得多。
搜索图中的其他弧
回忆一下国家扩张的过程。生成的假设和连接它们的扩展形成了一个图表。当一个假设有多个翻译选项,可以从中派生出多个新假设时,路径就会发生分支。当假设被重新组合时,路径就会连接起来。
通常,当我们重新组合假设时,我们只需丢弃较差的假设,因为它不可能是搜索图中最佳路径的一部分(换句话说,是最佳翻译的一部分)。
但是,由于我们现在也对第二好的翻译感兴趣,我们不能简单地丢弃有关该假设的信息。如果我们这样做,搜索图将只包含最后一个假设堆栈中每个假设的一条路径(其中包含涵盖所有外来词的假设)。
如果我们存储的信息表明,有多种方法可以达到一个假设,那么当我们向后遍历图时,可能的路径数也会沿着路径增加。
为了保存有关合并路径的信息,我们保留一个记录包含
- 先前假设的标识符
- 低成本假设的标识符
- 从先前到更高成本假设的成本
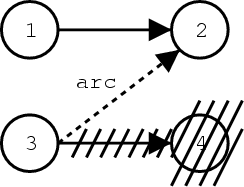
下图给出了生成这样一条弧的示例:在这种情况下,假设2和4与启发式搜索等效,如上所述。因此,删除假设4。但是,由于我们想保留从假设3到假设2的路径信息,所以我们存储了这条弧的记录。这条弧还包含从假设3至假设4增加的成本。请注意,假设1到假设2的成本不必存储,因为它可以根据假设数据结构重新计算。
挖掘n最佳列表的搜索图
假设空间的图也可以看作是概率有限状态自动机。假设是状态,倒链的记录和额外存储的弧是状态转换。扩展假设时增加的概率分数是状态转换的成本。
在这种概率有限状态自动机中寻找n条最佳路径是一个研究得很好的问题。在我们的实现中,我们将有关假设、假设转换和附加弧的信息存储在一个文件中,该文件可以由有限状态工具箱处理卡梅尔,我们用它来挖掘n个最佳列表。该工具包使用了Eppstein的_n_最短路径算法(FOCS,1994)。
我们的方法与Ueffing(2002)为IBMModel4生成n个最佳列表的工作有关。