从R2021a开始,您现在可以使用Simulink Coder和Embedded Coder从包含深层神经网络的Simullink模型生成通用C和C++代码。通用C和C++代码不依赖于第三方库,因此可以部署到编译C和C++码的任何嵌入式处理器上,包括一系列设备供应商的ARM Cortex-M系列处理器、DSP和微控制器。
在Simulink中,可以为卷积和递归深度学习神经网络生成通用C和C++代码。您可以使用深度学习工具箱中的块将网络对象合并到Simulink模型中,包括R2021a中引入的状态分类和状态预测块,或使用MATLAB功能块。通用C和C++代码生成支持多种网络和层。完整列表可以在我们的文档中找到。
现在,让我们部署一个从Simulink到ARM Cortex-M处理器的深度学习网络。在本例中,我们将使用LSTM网络预测涡扇发动机的剩余使用寿命。预训练网络接受来自17个发动机传感器的序列数据,并输出发动机剩余使用寿命的预测,以周期为单位进行测量。时间序列输入数据通过固定的工作空间块输入到模型,然后发送到预测神经网络块。
使用Deep Network Designer应用程序,我们可以深入查看网络,发现它包含六层,包括LSTM层。让我们在Simulink中模拟模型。从模拟中,我们可以看到,在这里显示的每个观测中,预训练的神经网络都相对较好地预测了涡扇发动机的剩余使用寿命。预测值与实际值接近,均方根误差为20.37。
现在,让我们从该模型生成通用C代码,并将其部署到ARM Cortex-M处理器。在配置参数中,我们将选择STM32F746G-Discovery板作为硬件板。在代码生成下,我们将系统目标文件设置为使用嵌入式编码器,将目标语言设置为C。我们将在工具链中使用ARM嵌入式处理器的新工具。最后,我们将确保深度学习目标库设置为“无”,以删除对第三方库的任何依赖。有了这些设置,让我们为包含神经网络的子系统生成代码。
在代码生成报告中,我们可以看到生成的文件不包括任何外部深度学习库。让我们在生成的代码中搜索模型步骤函数。看看步长函数,我们可以看到它包含一个预测方法。在预测方法中,我们可以看到为神经网络中使用而定义的一组权重和偏差。向下滚动,我们可以看见用于计算神经网络输出的代码,用于计算在每个时间步长传递的时间序列输入。
成功生成代码后,让我们将其部署到我们的目标。我们将使用处理器循环执行来对生成的代码的输出进行数字验证。在第二个模型中,我们将前面看到的预测块放置在模型参考中,并将其模拟模式设置为PIL。在SIL/PIL管理器应用程序中,我们将模拟模式设置为SIL/PII,仅用于收集在执行PIL时运行生成代码的结果,并选择SIL/PIL模式下的模型块作为我们的测试系统。
模拟后,我们将比较在硬件上运行通用C代码和Simulink的预测输出。现在让我们运行生成的代码。首先在PIL模式下为模型参考块生成代码。与我们的Cortex-M发现板建立了连接。最后,构建源代码并下载到其中。
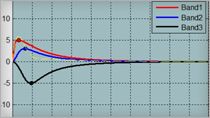
左边的一组图显示了在硬件上运行生成的代码的结果与实际测试数据非常接近。为了验证代码的数值准确性,我们在右侧创建了第二组图,以显示在目标硬件上以Simulink和PIL模式运行仿真时预测的差异。所有10次观察结果均表明,偏差在约500000的公差范围内,对神经网络的准确性影响可忽略不计。
总的来说,我们已经了解了如何从Simulink中的深度学习网络生成通用的C和C++代码,这些网络不依赖于优化库,有效地将其应用扩展到几乎任何嵌入式处理器。此外,通过处理器在环测试,我们验证了生成代码的输出与Simulink仿真的输出相匹配。要了解有关Simulink中深度学习代码生成和MATLAB的更多信息,请单击下面的链接之一或参阅我们的文档。