利用未初始化的记忆获取乐趣和利润
发布于2008年3月14日星期五。
开发一种将矩阵条目初始化为零的技术 第一次访问时,从而消除 O(运行) (|| V(V) || 2 )时间 初始化邻接矩阵。
用更少的时间交换更多空间的一个问题是 初始化空间本身会花费大量时间。 展示如何通过设计技术来规避此问题 第一次初始化向量的条目为零 已访问。 您的方案应使用恒定时间进行初始化 以及每个矢量访问; 你可以使用额外的空间比例 向量的大小。 因为这种方法减少了 通过使用更多空间初始化时间,它应该 只有在空间便宜、时间昂贵、 向量是稀疏的。
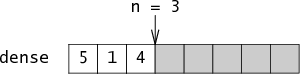
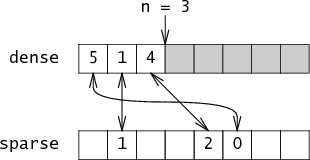
添加成员(i): 密度[n]=i 稀疏[i]=n n个++
是成员(i): return sparse[i]<n&&密集[sparse[1i]]==i
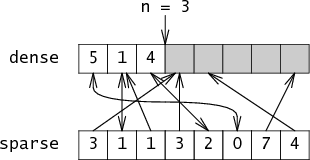
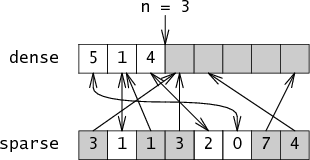
clear-set(): n=0
iterate(): 对于(i=0;i<n;i++) 屈服密度[i]
-
瓦哈拉苏 (2008年3月14日下午12:58) 是成员(i): return sparse[i]<n&&密集[sparse[1]] 这不应该吗 return sparse[i]<n&&密集[sparse[1i]]==i ,因为密集可以包含空元素。 显然,这只会在false=0表示时失败。
-
俄罗斯考克斯 (2008年3月14日下午1:50) @瓦哈拉苏:已经说过了 密集[稀疏[i]]=i; 我把=改为==,所以伪代码更像C。
-
瓦哈拉苏 (2008年3月14日下午3:13) Doh公司。 块前切割的任何东西都太靠右,所以==i没有出现。 从不知道div中的预块可能是这样的邪恶:)
-
俄罗斯考克斯 (2008年3月14日下午3:43) @瓦哈拉苏:谢谢你指出这一点。 添加了一些CSS魔法,使预块自动换行。
-
画 (2008年3月14日下午3:46) 还有恒定时间移除(尽管 小的 更多工作): 删除成员(i): 如果不是-member(i):返回 j=密实[n-1]; 稠密[稀疏[i]]=j; 稀疏[j]=稀疏[i]; n=n-1
-
格鲁西姆 (2008年3月15日12:17 AM) 非常酷。 但是,空间要求是每个元素两个单词(我假设您的意思是2*n),这样说对吗? 如果集合中的一个整数非常大,那么稀疏向量就不需要占用相应的大空间吗?
-
俄罗斯考克斯 (2008年3月15日上午11:06) @gruseom:空间成本是每个潜在条目2个单词(每个universe成员)。 我希望我已经把措辞改得更清楚了。 这里的对比应该是2个单词对1位。
-
丹 (2008年3月15日9:30 PM) 从安全的角度来看,因为第一眼看到的是另一个实例,有人认为未初始化的RAM包含随机数据。 实际上,这很管用,而且很酷! 这是从另一个镜头看它的样子。 规范、可信的“数组”是密集数组。 然而,这可能访问速度较慢。 因此,创建了第二个数组,其中数组中的值本身用作密集数组的索引。 现在,未初始化的内存可以包含任何内容,但其中的值要么引用回受信任数据集中的条目,要么不引用。 一个可能的麻烦来源是,如果同一个i被添加到数组中两次,第二个条目将吹走稀疏集中的第一个条目,这意味着密集集中会有一个值,而没有索引条目指向它。对于某些情况,这可能是一个问题。 然而,一个更大的问题是,整数不需要无符号:)如果不需要,稀疏[i]处的内存可能包含一个大于MAXINT的数字,该数字将小于0,因此传递n<0的成员身份。 您的系统可能会崩溃。
-
丹 (2008年3月15日10:28 PM) 除了崩溃之外,在稀疏[i]小于0的情况下,密集[sparse[i]]是 也 未初始化的内存。 所以,如果稠密[稀疏[i]] 发生 若要包含i,则会得到集合成员身份的假阳性。 (当然,我假设我被限制为小于malloc要稀疏的区域的大小)
-
丹 (2008年3月15日10:29 PM) 画, 检查n>0:)
-
蒂莫西·巴林顿·斯迈思 (2008年3月15日10:33 PM) 10打印“我的大脑很痛” 20转到10
-
八字裤 (2008年3月15日10:44 PM) 嘿Russ, 通过一个随机链接看到了这个博客。 然后我就像。。。 嘿,我认识这家伙! 很棒的博客。 我已经给它添加了书签。希望你一切顺利。 AJ公司
-
俄罗斯考克斯 (2008年3月16日上午5:04) @是的:i是无符号的,通常add-member需要检查数字是否已经存在,所有例程都应该根据稀疏的大小检查i。 我试图使演示保持简单。 报纸上有所有血腥的细节。
-
数据类型 (2008年3月16日上午7:30) 非常酷。 有一天我会用这个。
-
莫比乌斯 (2008年3月16日上午9:27) 稠密[]的元素不一定是唯一整数吗? 我
-
俄罗斯考克斯 (2008年3月16日上午9:39) @莫比乌斯:是的。 但集合是一种数据结构,每个元素只存储一次,所以没关系。 或者,如果您根据练习要求对其进行调整,则密集包含已用数据初始化的向量索引列表。 不管怎样,稠密元素的唯一性并不是一个真正的限制。
-
丹 (2008年3月16日上午11:51) @rsc i可以全天无符号——n必须是无符号的:)问题是当您取消引用稀疏[i]时。 如果该值恰好大于MAXINT,则会错过n<0检查和读取AV。 我认为这是一个合理的假设,即我将以适合稀疏[]的方式生成。 但您正在发布一篇关于如何处理内存中的任意值的帖子——您现在无法处理一半的值:)
-
丹 (2008年3月16日下午8:46) 实际上,我错了。 它是稀疏[]中元素的声明,必须是无符号的。 巴哈。
-
Rklz2号机组 (2008年4月7日晚上11:40) 起初我以为这是一个虚拟记忆技巧。 但是没有。 嗯,实际上可能是这样。这让我想起了复制垃圾收集器,垃圾收集器也会以更多的空间使用换取更少的时间分配,而去除所有复杂性后的算法与本文中的算法具有相同的主旨。
-
达格温 (2010年5月19日凌晨3:21) 注意,所有sparse[]都必须显式初始化(无关紧要的是,最好是0),以确保陷阱表示不被访问。 大多数人不会遇到这样的平台,但这是C标准允许的一种可能性。
-
哈斯克内比 (2010年7月11日12:32 PM) 这些索引技巧有很多 被Cray程序员发现 使用克雷散射/收集指令的。 例如,您可以通过对向量(1…n)写出一个iota来确定一组整数是否唯一,然后将该集合用作分散的索引,然后将集合用作聚集的索引来读取结果。 如果结果是相同的1..n,则集合是唯一的。
-
Zooko公司 (2010年7月12日上午7:50) CPython内存管理器做到了这一点,它确实推动了valgrind的发展。 但幸运的是,valgrind有一个很好的特性来抑制警告,而CPython的valgrind-抑制文件会抑制这些警告。
-
俄罗斯考克斯 (2011年1月6日上午10:12) 既然RE2是开源的,我可以指出这个过度设计的C++实现: util/spare_array。 小时 util/spare_set。 小时 我在最后提到的图形算法的一个示例是NFA模拟工作列表。 re2/nfa.cc公司
-
匿名 (2011年1月14日上午9:32) 虽然这在过去可能是真的,但当前硬件上的缓存线消耗将使位向量在任何情况下都优于此方法,除了非常小的数据集。
-
俄罗斯考克斯 (2011年1月14日上午10:11) @anonymous:这完全取决于你清理集合并重新开始的频率。 如果重置是罕见的,那么当然。 然而,如果重置很常见,那么您将看到O(1)vs O(n)。 当n变大时,无论你怎么看待内存系统,它都会赶上你。
-
Jean-Denis公司 (2011年2月22日凌晨1:53) 链接的纸张似乎不再可用,可能除了在付费墙后面。 谁能提供一个工作链接,或者可能通过电子邮件发送给我? 谢谢, gmail dot com上的jdmuys
-
莱拉 (2011年3月4日9:42 PM) 你好, 酷帖子! 这是一个很巧妙的技巧,我过去也用过,走集的好处真的很好(对于许多问题,它们远比不需要初始化数组的好处重要!)但我觉得我应该稍微保护一下位向量,因为我认为它们在清除问题上受到了一些不好的评价:-) 位向量不必是O(M)即可清除-它们可以很容易地是O(M/W)或O(M/(W*IPC)),其中W是体系结构的位宽度,IPC是每个时钟周期的指令数。 在单问题64位体系结构上,这将是O(M/64)。。。 在双问题128位SIMD体系结构(如推土机)上,这可能是O(M/256)。 对于大于64和256的集合大小,O(M/64)和O(M/256)仍然不是O(1),但O(M/W*IPC)通常仍然比O(M)友好得多!:)
-
匿名 (2011年12月7日下午3:44) @莱拉 这假定CPU可以发出类似的内存操作来清除这些单词。 你必须考虑内存总线。 x64 CPU可以通过总线上的单个指令清除256位吗?